



Ksenia Se / Turing Post
@turingpost.bsky.social
Founder of the newsletter that explores AI & ML (https://www.turingpost.com)
- AI 101 series
- ML techniques
- AI Unicorns profiles
- Global dynamics
- ML History
- AI/ML Flashcards
Haven't decided yet which handle to maintain: this or @kseniase
- AI 101 series
- ML techniques
- AI Unicorns profiles
- Global dynamics
- ML History
- AI/ML Flashcards
Haven't decided yet which handle to maintain: this or @kseniase
"Densing Law of LLMs" paper: arxiv.org/abs/2412.04315

December 11, 2024 at 11:40 AM
"Densing Law of LLMs" paper: arxiv.org/abs/2412.04315
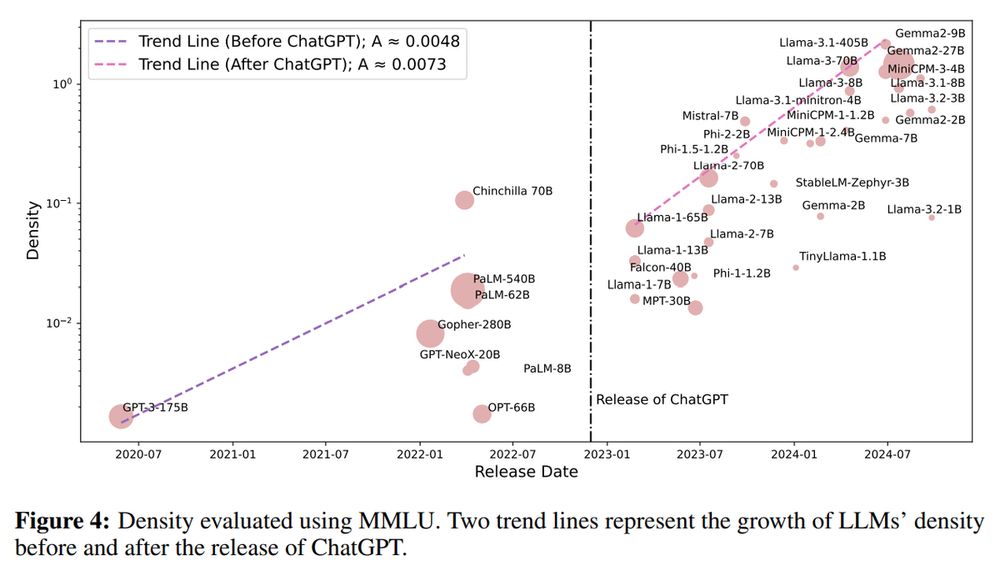
Here are the key findings from the study:
• Costs to run models are dropping as they are becoming more efficient.
• The release of ChatGPT sped up the growth of efficiency of new models up to 50%!
• Techniques like pruning and distillation don’t necessarily make models more efficient.
• Costs to run models are dropping as they are becoming more efficient.
• The release of ChatGPT sped up the growth of efficiency of new models up to 50%!
• Techniques like pruning and distillation don’t necessarily make models more efficient.
December 11, 2024 at 11:40 AM
Here are the key findings from the study:
• Costs to run models are dropping as they are becoming more efficient.
• The release of ChatGPT sped up the growth of efficiency of new models up to 50%!
• Techniques like pruning and distillation don’t necessarily make models more efficient.
• Costs to run models are dropping as they are becoming more efficient.
• The release of ChatGPT sped up the growth of efficiency of new models up to 50%!
• Techniques like pruning and distillation don’t necessarily make models more efficient.
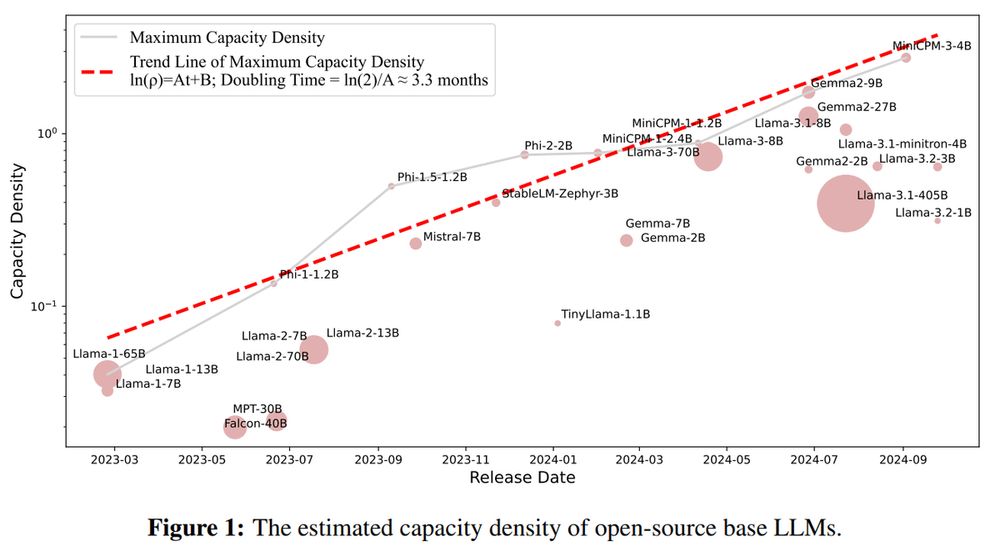
Reading about scaling laws recently I came by the interesting point:
Focus on a balance between models' size and performance is more important that aiming for larger models
Tsinghua University and ModelBest Inc propose the idea of “capacity density” to measure how efficiently a model uses its size
Focus on a balance between models' size and performance is more important that aiming for larger models
Tsinghua University and ModelBest Inc propose the idea of “capacity density” to measure how efficiently a model uses its size
December 11, 2024 at 11:40 AM
Reading about scaling laws recently I came by the interesting point:
Focus on a balance between models' size and performance is more important that aiming for larger models
Tsinghua University and ModelBest Inc propose the idea of “capacity density” to measure how efficiently a model uses its size
Focus on a balance between models' size and performance is more important that aiming for larger models
Tsinghua University and ModelBest Inc propose the idea of “capacity density” to measure how efficiently a model uses its size
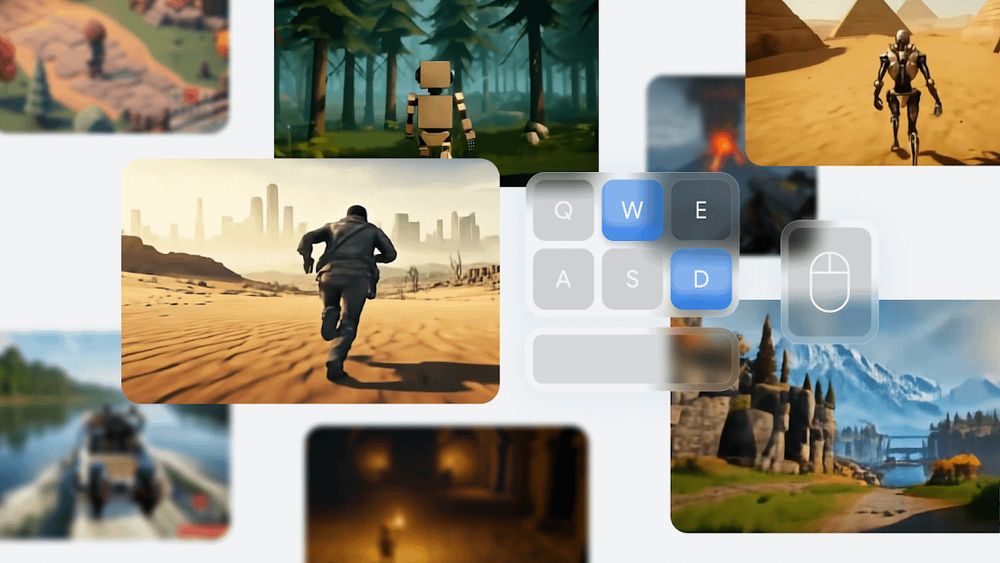
1. GoogleDeepMind's Genie 2
Generates 3D environments with object interactions, animations, and physical effects from one image or text prompt. You can interact with them in real-time using a keyboard and mouse.
Paper: deepmind.google/discover/blo...
Our example: www.youtube.com/watch?v=YjO6...
Generates 3D environments with object interactions, animations, and physical effects from one image or text prompt. You can interact with them in real-time using a keyboard and mouse.
Paper: deepmind.google/discover/blo...
Our example: www.youtube.com/watch?v=YjO6...

December 10, 2024 at 10:47 PM
1. GoogleDeepMind's Genie 2
Generates 3D environments with object interactions, animations, and physical effects from one image or text prompt. You can interact with them in real-time using a keyboard and mouse.
Paper: deepmind.google/discover/blo...
Our example: www.youtube.com/watch?v=YjO6...
Generates 3D environments with object interactions, animations, and physical effects from one image or text prompt. You can interact with them in real-time using a keyboard and mouse.
Paper: deepmind.google/discover/blo...
Our example: www.youtube.com/watch?v=YjO6...
An incredible shift is happening in spatial intelligence!
Here are 2 latest revolutional World Models, which create interactive 3D environments:
1. GoogleDeepMind's Genie 2
2. AI system from World Labs, co-founded by Fei-Fei Li
Explore more below 👇
Here are 2 latest revolutional World Models, which create interactive 3D environments:
1. GoogleDeepMind's Genie 2
2. AI system from World Labs, co-founded by Fei-Fei Li
Explore more below 👇
December 10, 2024 at 10:47 PM
An incredible shift is happening in spatial intelligence!
Here are 2 latest revolutional World Models, which create interactive 3D environments:
1. GoogleDeepMind's Genie 2
2. AI system from World Labs, co-founded by Fei-Fei Li
Explore more below 👇
Here are 2 latest revolutional World Models, which create interactive 3D environments:
1. GoogleDeepMind's Genie 2
2. AI system from World Labs, co-founded by Fei-Fei Li
Explore more below 👇
What is Flow Matching?
Flow Matching (FM) is used in top generative models, like Flux, F5-TTS, E2-TTS, and MovieGen with state-pf-the-art results. Some experts even say that FM might surpass diffusion models👇
Flow Matching (FM) is used in top generative models, like Flux, F5-TTS, E2-TTS, and MovieGen with state-pf-the-art results. Some experts even say that FM might surpass diffusion models👇
December 5, 2024 at 1:06 AM
What is Flow Matching?
Flow Matching (FM) is used in top generative models, like Flux, F5-TTS, E2-TTS, and MovieGen with state-pf-the-art results. Some experts even say that FM might surpass diffusion models👇
Flow Matching (FM) is used in top generative models, like Flux, F5-TTS, E2-TTS, and MovieGen with state-pf-the-art results. Some experts even say that FM might surpass diffusion models👇
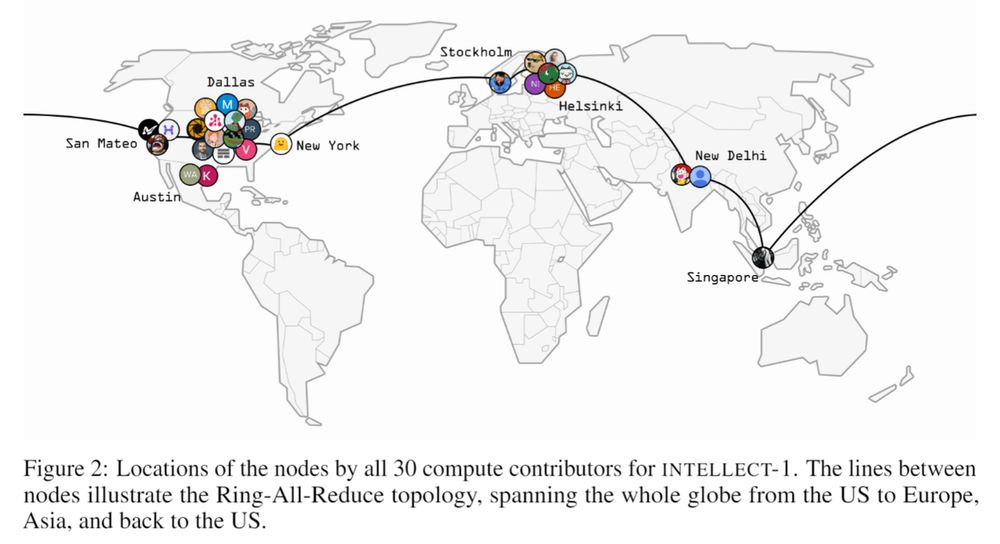
INTELLECT-1 by Prime Intellect
INTELLECT-1 is a 10B open-source LLM trained over 42 days on 1T tokens across 14 global nodes, leverages the PRIME framework for exceptional efficiency (400× bandwidth reduction).
github.com/PrimeIntelle...
INTELLECT-1 is a 10B open-source LLM trained over 42 days on 1T tokens across 14 global nodes, leverages the PRIME framework for exceptional efficiency (400× bandwidth reduction).
github.com/PrimeIntelle...
December 5, 2024 at 12:30 AM
INTELLECT-1 by Prime Intellect
INTELLECT-1 is a 10B open-source LLM trained over 42 days on 1T tokens across 14 global nodes, leverages the PRIME framework for exceptional efficiency (400× bandwidth reduction).
github.com/PrimeIntelle...
INTELLECT-1 is a 10B open-source LLM trained over 42 days on 1T tokens across 14 global nodes, leverages the PRIME framework for exceptional efficiency (400× bandwidth reduction).
github.com/PrimeIntelle...
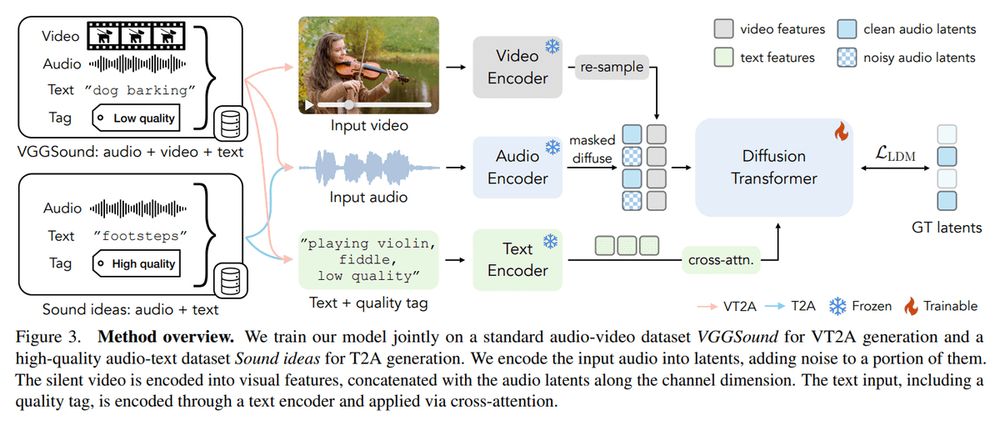
MultiFoley by Adobe Research
MultiFoley is an AI model generating high-quality sound effects from text, audio, and video inputs. Cool demos highlight its creative potential.
arxiv.org/abs/2411.17698
MultiFoley is an AI model generating high-quality sound effects from text, audio, and video inputs. Cool demos highlight its creative potential.
arxiv.org/abs/2411.17698
December 5, 2024 at 12:30 AM
MultiFoley by Adobe Research
MultiFoley is an AI model generating high-quality sound effects from text, audio, and video inputs. Cool demos highlight its creative potential.
arxiv.org/abs/2411.17698
MultiFoley is an AI model generating high-quality sound effects from text, audio, and video inputs. Cool demos highlight its creative potential.
arxiv.org/abs/2411.17698
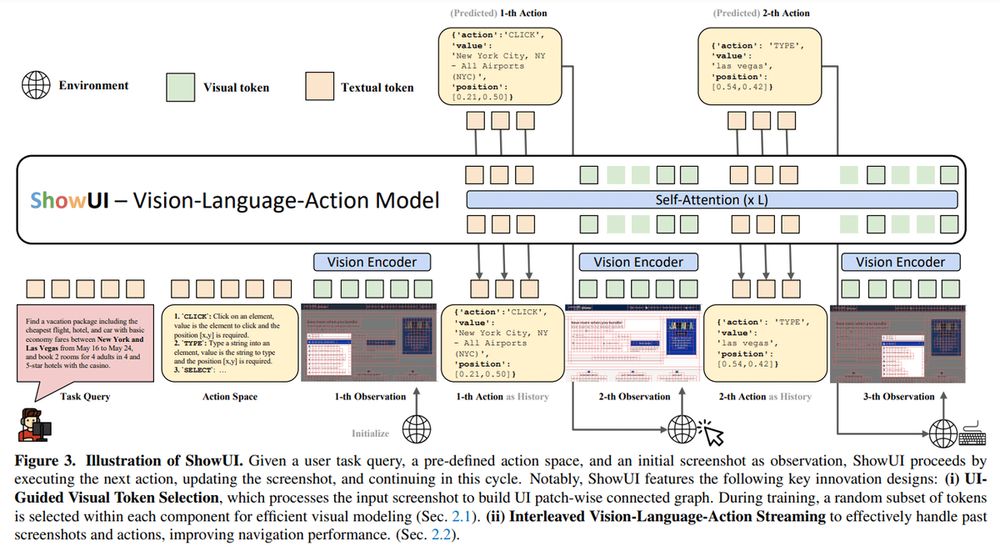
ShowUI by Show Lab, NUS, Microsoft
ShowUI is a 2B vision-language-action model tailored for GUI tasks:
- features UI-guided token selection (33% fewer tokens)
- interleaved streaming for multi-turn tasks
- 256K dataset
- achieves 75.1% zero-shot grounding accuracy
arxiv.org/abs/2411.17465
ShowUI is a 2B vision-language-action model tailored for GUI tasks:
- features UI-guided token selection (33% fewer tokens)
- interleaved streaming for multi-turn tasks
- 256K dataset
- achieves 75.1% zero-shot grounding accuracy
arxiv.org/abs/2411.17465
December 5, 2024 at 12:30 AM
ShowUI by Show Lab, NUS, Microsoft
ShowUI is a 2B vision-language-action model tailored for GUI tasks:
- features UI-guided token selection (33% fewer tokens)
- interleaved streaming for multi-turn tasks
- 256K dataset
- achieves 75.1% zero-shot grounding accuracy
arxiv.org/abs/2411.17465
ShowUI is a 2B vision-language-action model tailored for GUI tasks:
- features UI-guided token selection (33% fewer tokens)
- interleaved streaming for multi-turn tasks
- 256K dataset
- achieves 75.1% zero-shot grounding accuracy
arxiv.org/abs/2411.17465
OLMo 2 by Allen AI
OLMo 2, a family of fully open LMs with 7B and 13B parameter, is trained on 5 trillion tokens.
allenai.org/blog/olmo2
OLMo 2, a family of fully open LMs with 7B and 13B parameter, is trained on 5 trillion tokens.
allenai.org/blog/olmo2
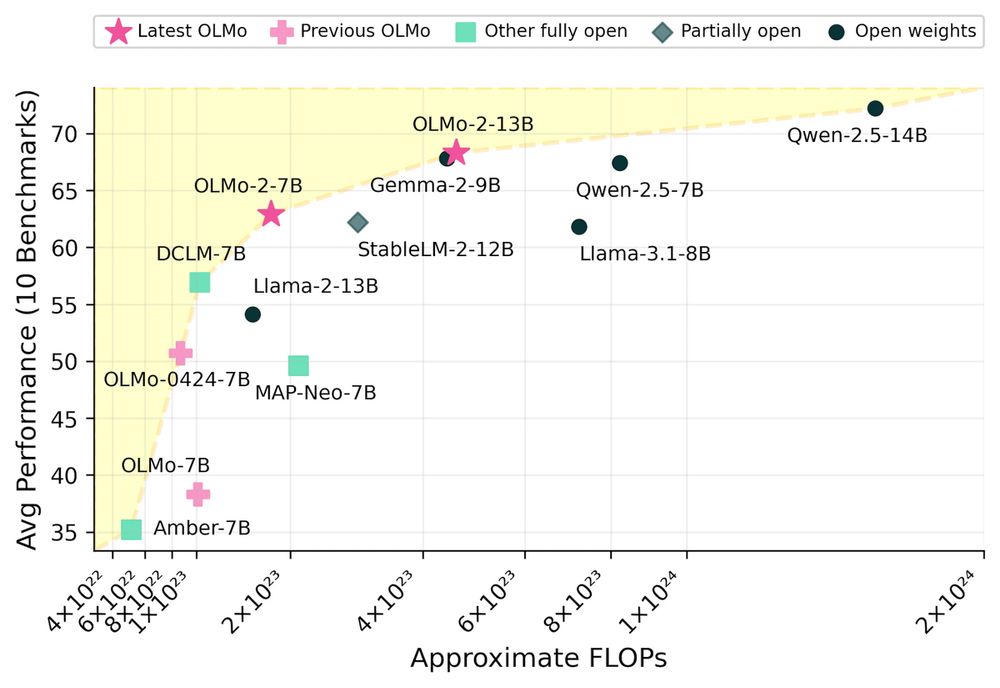
December 5, 2024 at 12:30 AM
OLMo 2 by Allen AI
OLMo 2, a family of fully open LMs with 7B and 13B parameter, is trained on 5 trillion tokens.
allenai.org/blog/olmo2
OLMo 2, a family of fully open LMs with 7B and 13B parameter, is trained on 5 trillion tokens.
allenai.org/blog/olmo2
Amazing models of the week:
• Alibaba’s QwQ-32B
• OLMo 2 by Allen AI
• ShowUI by Show Lab, NUS, Microsoft
• Adobe's MultiFoley
• INTELLECT-1 by Prime Intellect
🧵
• Alibaba’s QwQ-32B
• OLMo 2 by Allen AI
• ShowUI by Show Lab, NUS, Microsoft
• Adobe's MultiFoley
• INTELLECT-1 by Prime Intellect
🧵

December 5, 2024 at 12:30 AM
Amazing models of the week:
• Alibaba’s QwQ-32B
• OLMo 2 by Allen AI
• ShowUI by Show Lab, NUS, Microsoft
• Adobe's MultiFoley
• INTELLECT-1 by Prime Intellect
🧵
• Alibaba’s QwQ-32B
• OLMo 2 by Allen AI
• ShowUI by Show Lab, NUS, Microsoft
• Adobe's MultiFoley
• INTELLECT-1 by Prime Intellect
🧵
Boundless Socratic Learning with Language Games, Google DeepMind
This framework leverages recursive language-based "games" for self-improvement, focusing of feedback, coverage, and scalability. It suggests a roadmap for scalable AI via autonomous data gen and feedback loops
arxiv.org/abs/2411.16905
This framework leverages recursive language-based "games" for self-improvement, focusing of feedback, coverage, and scalability. It suggests a roadmap for scalable AI via autonomous data gen and feedback loops
arxiv.org/abs/2411.16905
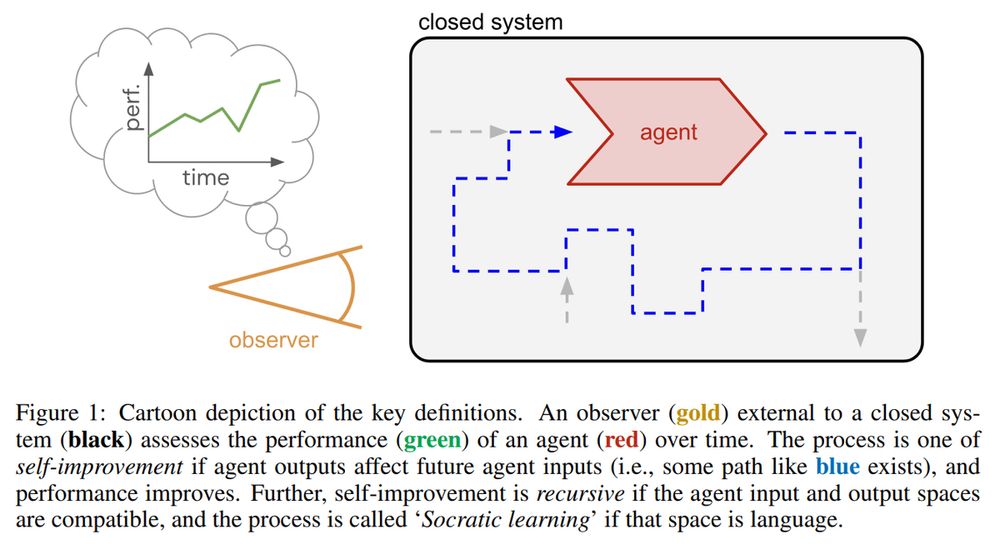
December 2, 2024 at 11:15 PM
Boundless Socratic Learning with Language Games, Google DeepMind
This framework leverages recursive language-based "games" for self-improvement, focusing of feedback, coverage, and scalability. It suggests a roadmap for scalable AI via autonomous data gen and feedback loops
arxiv.org/abs/2411.16905
This framework leverages recursive language-based "games" for self-improvement, focusing of feedback, coverage, and scalability. It suggests a roadmap for scalable AI via autonomous data gen and feedback loops
arxiv.org/abs/2411.16905
MH-MoE: Multi-Head Mixture-of-Experts
@msftresearch.bsky.social’s MH-MoE improves sparse MoE by adding multi-head attention, reducing perplexity without increasing FLOPs, and demonstrating robust performance under quantization.
arxiv.org/abs/2411.16205
@msftresearch.bsky.social’s MH-MoE improves sparse MoE by adding multi-head attention, reducing perplexity without increasing FLOPs, and demonstrating robust performance under quantization.
arxiv.org/abs/2411.16205
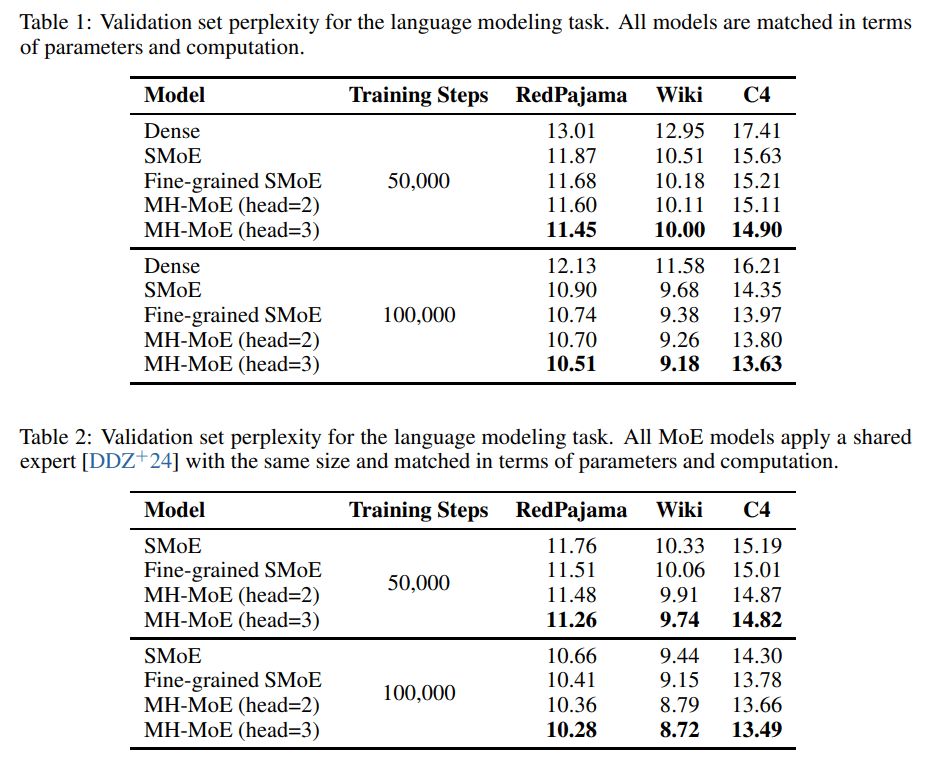
December 2, 2024 at 11:15 PM
MH-MoE: Multi-Head Mixture-of-Experts
@msftresearch.bsky.social’s MH-MoE improves sparse MoE by adding multi-head attention, reducing perplexity without increasing FLOPs, and demonstrating robust performance under quantization.
arxiv.org/abs/2411.16205
@msftresearch.bsky.social’s MH-MoE improves sparse MoE by adding multi-head attention, reducing perplexity without increasing FLOPs, and demonstrating robust performance under quantization.
arxiv.org/abs/2411.16205
LLM-as-a-Judge:
Presents a taxonomy of methodologies and applications of LLMs for judgment tasks, highlighting bias, vulnerabilities, and self-judgment, with future directions in human-LLM collaboration and bias mitigation
arxiv.org/abs/2411.16594
Presents a taxonomy of methodologies and applications of LLMs for judgment tasks, highlighting bias, vulnerabilities, and self-judgment, with future directions in human-LLM collaboration and bias mitigation
arxiv.org/abs/2411.16594
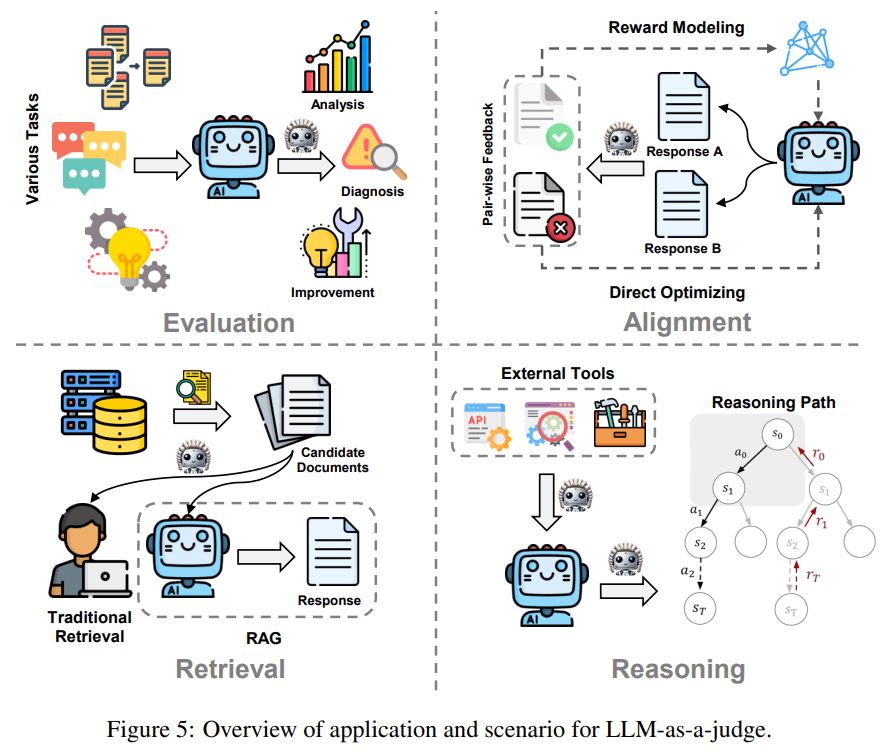
December 2, 2024 at 11:15 PM
LLM-as-a-Judge:
Presents a taxonomy of methodologies and applications of LLMs for judgment tasks, highlighting bias, vulnerabilities, and self-judgment, with future directions in human-LLM collaboration and bias mitigation
arxiv.org/abs/2411.16594
Presents a taxonomy of methodologies and applications of LLMs for judgment tasks, highlighting bias, vulnerabilities, and self-judgment, with future directions in human-LLM collaboration and bias mitigation
arxiv.org/abs/2411.16594
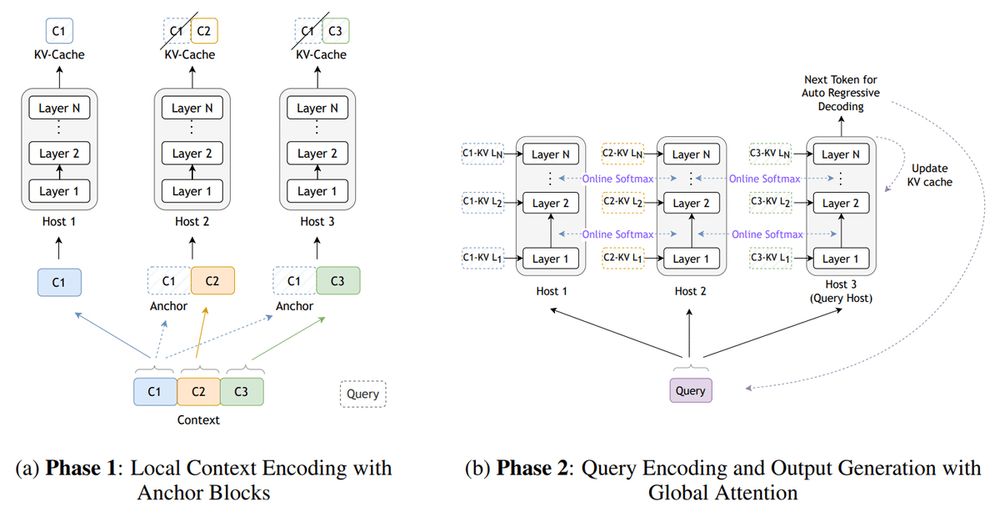
Star Attention:
NVIDIA introduced a block-sparse attention mechanism for Transformer-based LLMs. It uses local/global attention phases to achieve up to 11x inference speedup on sequences up to 1M tokens, retaining 95-100% accuracy.
arxiv.org/abs/2411.17116
Code: github.com/NVIDIA/Star-...
NVIDIA introduced a block-sparse attention mechanism for Transformer-based LLMs. It uses local/global attention phases to achieve up to 11x inference speedup on sequences up to 1M tokens, retaining 95-100% accuracy.
arxiv.org/abs/2411.17116
Code: github.com/NVIDIA/Star-...
December 2, 2024 at 11:15 PM
Star Attention:
NVIDIA introduced a block-sparse attention mechanism for Transformer-based LLMs. It uses local/global attention phases to achieve up to 11x inference speedup on sequences up to 1M tokens, retaining 95-100% accuracy.
arxiv.org/abs/2411.17116
Code: github.com/NVIDIA/Star-...
NVIDIA introduced a block-sparse attention mechanism for Transformer-based LLMs. It uses local/global attention phases to achieve up to 11x inference speedup on sequences up to 1M tokens, retaining 95-100% accuracy.
arxiv.org/abs/2411.17116
Code: github.com/NVIDIA/Star-...
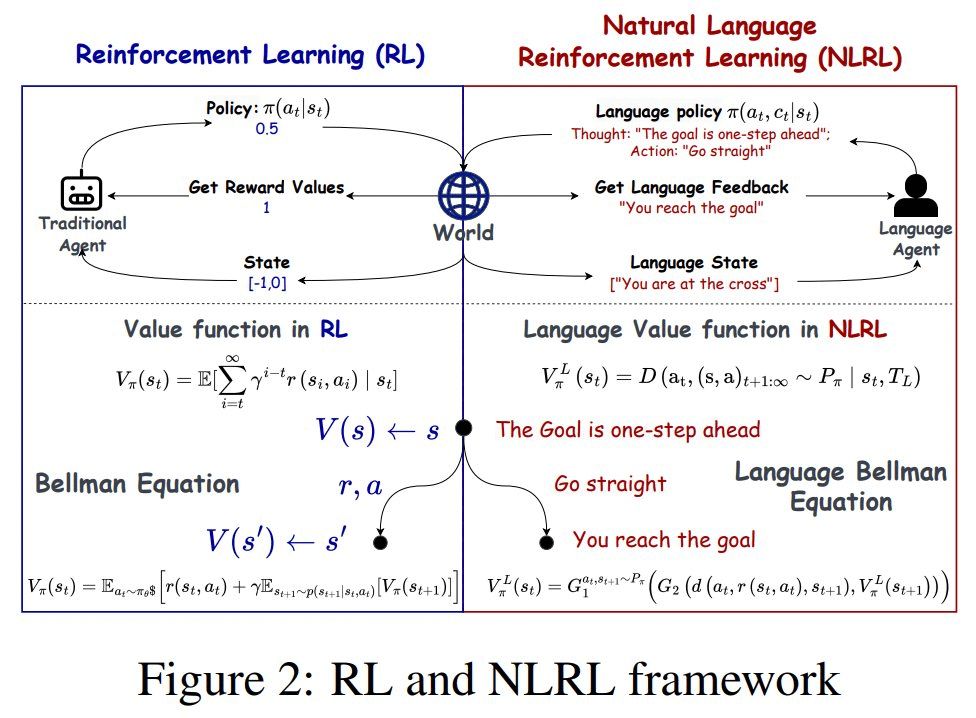
Top 5 researches of the week:
• Natural Language Reinforcement Learning
• Star Attention, NVIDIA
• Opportunities and Challenges of LLM-as-a-judge
• MH-MoE: Multi-Head Mixture-of-Experts, @msftresearch.bsky.social
• Boundless Socratic Learning with Language Games, Google DeepMind
🧵
• Natural Language Reinforcement Learning
• Star Attention, NVIDIA
• Opportunities and Challenges of LLM-as-a-judge
• MH-MoE: Multi-Head Mixture-of-Experts, @msftresearch.bsky.social
• Boundless Socratic Learning with Language Games, Google DeepMind
🧵
December 2, 2024 at 11:15 PM
Top 5 researches of the week:
• Natural Language Reinforcement Learning
• Star Attention, NVIDIA
• Opportunities and Challenges of LLM-as-a-judge
• MH-MoE: Multi-Head Mixture-of-Experts, @msftresearch.bsky.social
• Boundless Socratic Learning with Language Games, Google DeepMind
🧵
• Natural Language Reinforcement Learning
• Star Attention, NVIDIA
• Opportunities and Challenges of LLM-as-a-judge
• MH-MoE: Multi-Head Mixture-of-Experts, @msftresearch.bsky.social
• Boundless Socratic Learning with Language Games, Google DeepMind
🧵
Paper: Large Language Model-Brained GUI Agents: A Survey arxiv.org/abs/2411.18279

December 2, 2024 at 12:15 PM
Paper: Large Language Model-Brained GUI Agents: A Survey arxiv.org/abs/2411.18279
2. Prompt engineering or creating a plan:
After "looking" at the screen, the agent prepares a prompt for the AI model, which includes the user’s instructions, the visual data (like screenshots or buttons layout), and other context the agent needs to understand the task.
After "looking" at the screen, the agent prepares a prompt for the AI model, which includes the user’s instructions, the visual data (like screenshots or buttons layout), and other context the agent needs to understand the task.

December 2, 2024 at 12:15 PM
2. Prompt engineering or creating a plan:
After "looking" at the screen, the agent prepares a prompt for the AI model, which includes the user’s instructions, the visual data (like screenshots or buttons layout), and other context the agent needs to understand the task.
After "looking" at the screen, the agent prepares a prompt for the AI model, which includes the user’s instructions, the visual data (like screenshots or buttons layout), and other context the agent needs to understand the task.
1. Understanding the environment:
Firstly, the agent needs to "see" the software it’s working with. This is done through methods that capture the layout of the app or website, such as screenshots, lists of buttons and menus called widget trees.
Firstly, the agent needs to "see" the software it’s working with. This is done through methods that capture the layout of the app or website, such as screenshots, lists of buttons and menus called widget trees.

December 2, 2024 at 12:15 PM
1. Understanding the environment:
Firstly, the agent needs to "see" the software it’s working with. This is done through methods that capture the layout of the app or website, such as screenshots, lists of buttons and menus called widget trees.
Firstly, the agent needs to "see" the software it’s working with. This is done through methods that capture the layout of the app or website, such as screenshots, lists of buttons and menus called widget trees.
LLM-brained GUI agents are a way to interact with GUIs in a much more flexible and human-like way.
They blend LLMs' capabilities with software interaction to work with websites, mobile apps, and desktop software, simplifying complex tasks.
A new survey on LLM-brained GUI agents was published👇
They blend LLMs' capabilities with software interaction to work with websites, mobile apps, and desktop software, simplifying complex tasks.
A new survey on LLM-brained GUI agents was published👇

December 2, 2024 at 12:15 PM
LLM-brained GUI agents are a way to interact with GUIs in a much more flexible and human-like way.
They blend LLMs' capabilities with software interaction to work with websites, mobile apps, and desktop software, simplifying complex tasks.
A new survey on LLM-brained GUI agents was published👇
They blend LLMs' capabilities with software interaction to work with websites, mobile apps, and desktop software, simplifying complex tasks.
A new survey on LLM-brained GUI agents was published👇
Our TuringPost Twitter Library provides useful resources, such as lists of tools and models, papers and courses on various popular aspects of AI and machine learning for you every week. Check it out.
www.turingpost.com/t/Twitter-Li...
www.turingpost.com/t/Twitter-Li...

December 1, 2024 at 6:55 PM
Our TuringPost Twitter Library provides useful resources, such as lists of tools and models, papers and courses on various popular aspects of AI and machine learning for you every week. Check it out.
www.turingpost.com/t/Twitter-Li...
www.turingpost.com/t/Twitter-Li...
Top 10 GitHub Repositories to master ML, AI and Data Science:
• 100 Days of ML Code
• Data Science For Beginners
• Awesome Data Science
• Data Science Masters
• Homemade Machine Learning
• 500+ AI Projects List with Code
• Awesome Artificial Intelligence
...
Check out for more👇
• 100 Days of ML Code
• Data Science For Beginners
• Awesome Data Science
• Data Science Masters
• Homemade Machine Learning
• 500+ AI Projects List with Code
• Awesome Artificial Intelligence
...
Check out for more👇

December 1, 2024 at 6:55 PM
Top 10 GitHub Repositories to master ML, AI and Data Science:
• 100 Days of ML Code
• Data Science For Beginners
• Awesome Data Science
• Data Science Masters
• Homemade Machine Learning
• 500+ AI Projects List with Code
• Awesome Artificial Intelligence
...
Check out for more👇
• 100 Days of ML Code
• Data Science For Beginners
• Awesome Data Science
• Data Science Masters
• Homemade Machine Learning
• 500+ AI Projects List with Code
• Awesome Artificial Intelligence
...
Check out for more👇

Benefits of HiAR-ICL:
- Thanks to thought cards, HiAR-ICL requires less human input to guide it and adapts better to different types of problems
-Faster by focusing only on actions from thought card
- Accuracy: It achieved 79.6% accuracy on a math benchmark, compared to GPT-4o’s 76.6%.
- Thanks to thought cards, HiAR-ICL requires less human input to guide it and adapts better to different types of problems
-Faster by focusing only on actions from thought card
- Accuracy: It achieved 79.6% accuracy on a math benchmark, compared to GPT-4o’s 76.6%.

November 30, 2024 at 11:52 PM
Benefits of HiAR-ICL:
- Thanks to thought cards, HiAR-ICL requires less human input to guide it and adapts better to different types of problems
-Faster by focusing only on actions from thought card
- Accuracy: It achieved 79.6% accuracy on a math benchmark, compared to GPT-4o’s 76.6%.
- Thanks to thought cards, HiAR-ICL requires less human input to guide it and adapts better to different types of problems
-Faster by focusing only on actions from thought card
- Accuracy: It achieved 79.6% accuracy on a math benchmark, compared to GPT-4o’s 76.6%.
Thought Cards with Monte Carlo Tree Search (MCTS):
Thought cards are like reusable problem-solving templates.
After MCTS generates multiple possible solution paths for each problem, HiAR-ICL picks the best one by weighing the paths using Value of Computation (VOC).
Thought cards are like reusable problem-solving templates.
After MCTS generates multiple possible solution paths for each problem, HiAR-ICL picks the best one by weighing the paths using Value of Computation (VOC).

November 30, 2024 at 11:52 PM
Thought Cards with Monte Carlo Tree Search (MCTS):
Thought cards are like reusable problem-solving templates.
After MCTS generates multiple possible solution paths for each problem, HiAR-ICL picks the best one by weighing the paths using Value of Computation (VOC).
Thought cards are like reusable problem-solving templates.
After MCTS generates multiple possible solution paths for each problem, HiAR-ICL picks the best one by weighing the paths using Value of Computation (VOC).