


Antonia Wüst
@toniwuest.bsky.social
PhD student at AIML Lab TU Darmstadt
Interested in concept learning, neuro-symbolic AI and program synthesis
Interested in concept learning, neuro-symbolic AI and program synthesis
And last but not least: the spirals are still spinning, each in their own direction 🌀

August 20, 2025 at 4:57 PM
And last but not least: the spirals are still spinning, each in their own direction 🌀
💻 We also added a demo of the evaluation to our GitHub repo! Check it out here: github.com/ml-research/...

bongard-in-wonderland/demo.ipynb at main · ml-research/bongard-in-wonderland
Contribute to ml-research/bongard-in-wonderland development by creating an account on GitHub.
github.com
August 20, 2025 at 4:53 PM
💻 We also added a demo of the evaluation to our GitHub repo! Check it out here: github.com/ml-research/...
📊 Updated results are also on our webpage!
Link: ml-research.github.io/bongard-in-w...
Curious to hear - should we evaluate other models too? 🤖
Link: ml-research.github.io/bongard-in-w...
Curious to hear - should we evaluate other models too? 🤖
Bongard in Wonderland
ml-research.github.io
August 20, 2025 at 4:53 PM
📊 Updated results are also on our webpage!
Link: ml-research.github.io/bongard-in-w...
Curious to hear - should we evaluate other models too? 🤖
Link: ml-research.github.io/bongard-in-w...
Curious to hear - should we evaluate other models too? 🤖
🔎 Importantly, Task 2 continues to expose inconsistencies between the solved problems in Task 1 (64) and the problems where the model can correctly classify the individual images of the problem (only 34), given the gt options (Task 2).

August 20, 2025 at 4:52 PM
🔎 Importantly, Task 2 continues to expose inconsistencies between the solved problems in Task 1 (64) and the problems where the model can correctly classify the individual images of the problem (only 34), given the gt options (Task 2).
🤔 Surprisingly, even some easy problems like BP8 remain unsolved…

August 20, 2025 at 4:52 PM
🤔 Surprisingly, even some easy problems like BP8 remain unsolved…
Work together with my amazing co-authors @philosotim.bsky.social
Lukas Helff @ingaibs.bsky.social @wolfstammer.bsky.social @devendradhami.bsky.social @c-rothkopf.bsky.social @kerstingaiml.bsky.social ! ✨
Lukas Helff @ingaibs.bsky.social @wolfstammer.bsky.social @devendradhami.bsky.social @c-rothkopf.bsky.social @kerstingaiml.bsky.social ! ✨
May 2, 2025 at 8:00 AM
Work together with my amazing co-authors @philosotim.bsky.social
Lukas Helff @ingaibs.bsky.social @wolfstammer.bsky.social @devendradhami.bsky.social @c-rothkopf.bsky.social @kerstingaiml.bsky.social ! ✨
Lukas Helff @ingaibs.bsky.social @wolfstammer.bsky.social @devendradhami.bsky.social @c-rothkopf.bsky.social @kerstingaiml.bsky.social ! ✨
We also identified 10 particularly challenging Bongard Problems that none of the models could solve under any setting. The challenge remains wide open!
3 examples of the challenging BPs:
3 examples of the challenging BPs:
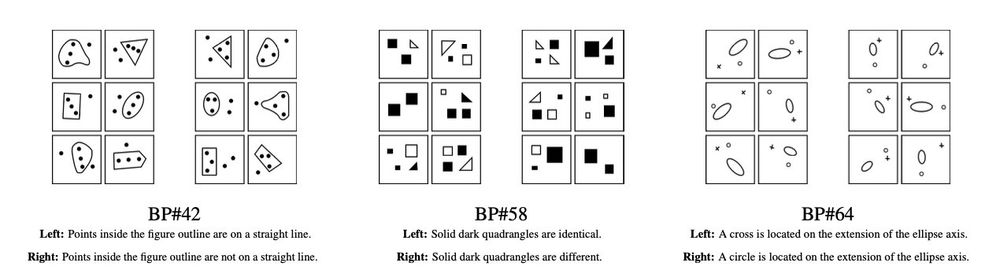
May 2, 2025 at 7:57 AM
We also identified 10 particularly challenging Bongard Problems that none of the models could solve under any setting. The challenge remains wide open!
3 examples of the challenging BPs:
3 examples of the challenging BPs:
Interestingly, success in solving the BPs (Open Question) doesn't translate to correctly categorizing individual images 👉 the sets of BPs solved in each task are not the same!
This suggests that getting the right final answer doesn’t always mean genuine understanding 🤔
This suggests that getting the right final answer doesn’t always mean genuine understanding 🤔

May 2, 2025 at 7:55 AM
Interestingly, success in solving the BPs (Open Question) doesn't translate to correctly categorizing individual images 👉 the sets of BPs solved in each task are not the same!
This suggests that getting the right final answer doesn’t always mean genuine understanding 🤔
This suggests that getting the right final answer doesn’t always mean genuine understanding 🤔
Our evaluation shows the top-performing model (o1) solved 43 out of 100 problems, with the others trailing far behind. There’s still a long way to go for current AI models!
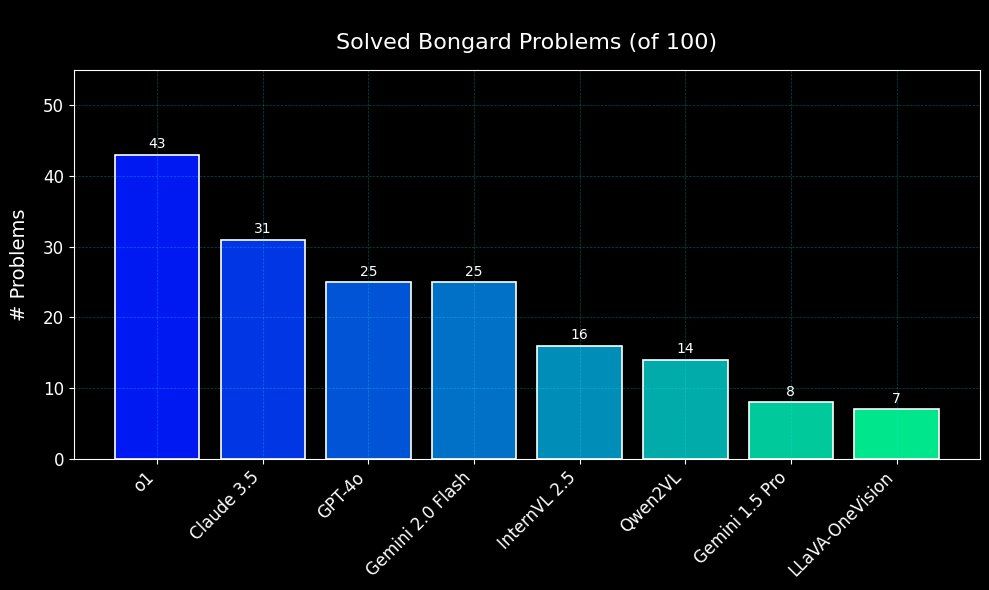
May 2, 2025 at 7:53 AM
Our evaluation shows the top-performing model (o1) solved 43 out of 100 problems, with the others trailing far behind. There’s still a long way to go for current AI models!