



@tomgoldstein.bsky.social
Huginn is just a proof of concept.
Still, Huggin-3.5B can beat OLMo-7B-0724 (with CoT) at GSM8K by a wide margin (42% vs 29%).
Huginn has half the parameters, 1/3 the training tokens, no explicit fine-tuning, and the LR was never annealed.
Latent reasoning still wins.
Still, Huggin-3.5B can beat OLMo-7B-0724 (with CoT) at GSM8K by a wide margin (42% vs 29%).
Huginn has half the parameters, 1/3 the training tokens, no explicit fine-tuning, and the LR was never annealed.
Latent reasoning still wins.

February 10, 2025 at 3:58 PM
Huginn is just a proof of concept.
Still, Huggin-3.5B can beat OLMo-7B-0724 (with CoT) at GSM8K by a wide margin (42% vs 29%).
Huginn has half the parameters, 1/3 the training tokens, no explicit fine-tuning, and the LR was never annealed.
Latent reasoning still wins.
Still, Huggin-3.5B can beat OLMo-7B-0724 (with CoT) at GSM8K by a wide margin (42% vs 29%).
Huginn has half the parameters, 1/3 the training tokens, no explicit fine-tuning, and the LR was never annealed.
Latent reasoning still wins.
Recurrence improves reasoning a lot. To show this, we did a comparison with a standard architecture.
We train a standard 3.5B LLM from scratch on 180B tokens. Then we train a recurrent 3.5B model on the same tokens.
The recurrent model does 5X better on GSM8K.
We train a standard 3.5B LLM from scratch on 180B tokens. Then we train a recurrent 3.5B model on the same tokens.
The recurrent model does 5X better on GSM8K.

February 10, 2025 at 3:58 PM
Recurrence improves reasoning a lot. To show this, we did a comparison with a standard architecture.
We train a standard 3.5B LLM from scratch on 180B tokens. Then we train a recurrent 3.5B model on the same tokens.
The recurrent model does 5X better on GSM8K.
We train a standard 3.5B LLM from scratch on 180B tokens. Then we train a recurrent 3.5B model on the same tokens.
The recurrent model does 5X better on GSM8K.
Huginn was built for reasoning from the ground up, not just fine-tuned on CoT.
We built our reasoning system by putting a recurrent block inside the LLM. On a forward pass, we loop this block a random number of times. By looping it more times, we dial up compute.
We built our reasoning system by putting a recurrent block inside the LLM. On a forward pass, we loop this block a random number of times. By looping it more times, we dial up compute.

February 10, 2025 at 3:58 PM
Huginn was built for reasoning from the ground up, not just fine-tuned on CoT.
We built our reasoning system by putting a recurrent block inside the LLM. On a forward pass, we loop this block a random number of times. By looping it more times, we dial up compute.
We built our reasoning system by putting a recurrent block inside the LLM. On a forward pass, we loop this block a random number of times. By looping it more times, we dial up compute.
New open source reasoning model!
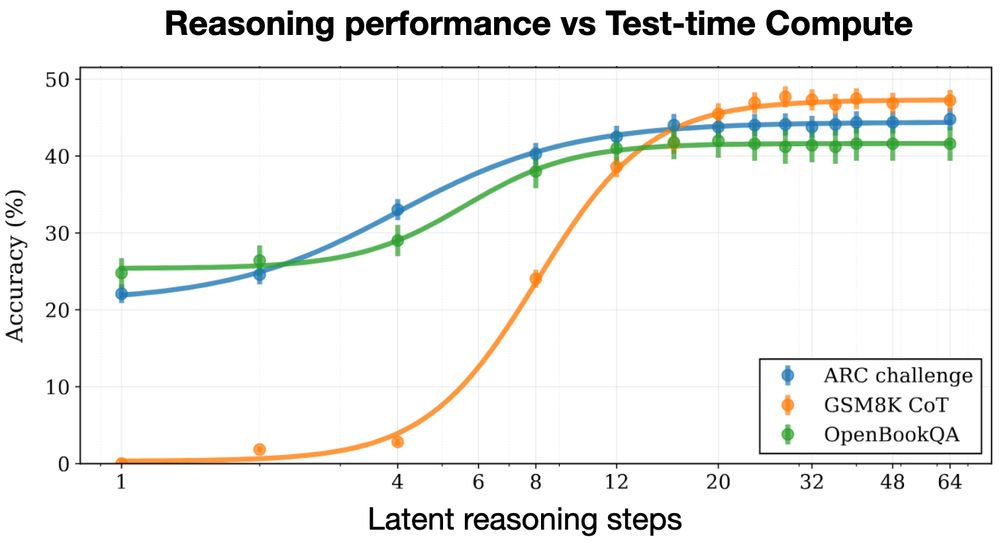
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
February 10, 2025 at 3:58 PM
New open source reasoning model!
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
For 34B, Pytorch Foundation reports throughput of 1500 tokens/sec per GPU.
With this throughput, DeepSeek’s 2.664M GPU-hour pre-training run would rip through 14.3T tokens. DeepSeek claims to have trained on 14.8T tokens.
This part checks out...but only with killer engineering.
With this throughput, DeepSeek’s 2.664M GPU-hour pre-training run would rip through 14.3T tokens. DeepSeek claims to have trained on 14.8T tokens.
This part checks out...but only with killer engineering.

January 29, 2025 at 5:12 PM
For 34B, Pytorch Foundation reports throughput of 1500 tokens/sec per GPU.
With this throughput, DeepSeek’s 2.664M GPU-hour pre-training run would rip through 14.3T tokens. DeepSeek claims to have trained on 14.8T tokens.
This part checks out...but only with killer engineering.
With this throughput, DeepSeek’s 2.664M GPU-hour pre-training run would rip through 14.3T tokens. DeepSeek claims to have trained on 14.8T tokens.
This part checks out...but only with killer engineering.