



@tomgoldstein.bsky.social
Nowadays ML projects feel like they need to be compressed into a few months. Its refreshing to be able to work on something for a few years!
But also a slog.
But also a slog.

Ok, so I can finally talk about this!
We spent the last year (actually a bit longer) training an LLM with recurrent depth at scale.
The model has an internal latent space in which it can adaptively spend more compute to think longer.
I think the tech report ...🐦⬛
We spent the last year (actually a bit longer) training an LLM with recurrent depth at scale.
The model has an internal latent space in which it can adaptively spend more compute to think longer.
I think the tech report ...🐦⬛
February 10, 2025 at 4:57 PM
Nowadays ML projects feel like they need to be compressed into a few months. Its refreshing to be able to work on something for a few years!
But also a slog.
But also a slog.
New open source reasoning model!
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
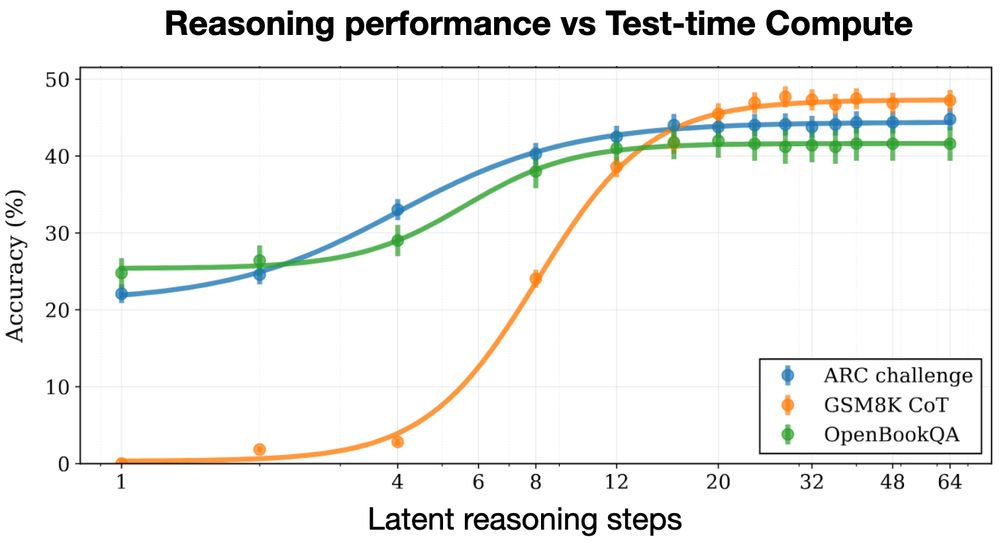
February 10, 2025 at 3:58 PM
New open source reasoning model!
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
Reposted

📢PSA: #NeurIPS2024 recordings are now publicly available!
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
January 22, 2025 at 9:04 PM
📢PSA: #NeurIPS2024 recordings are now publicly available!
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
The workshops always have tons of interesting things on at once, so the FOMO is real😵💫 Luckily it's all recorded, so I've been catching up on what I missed.
Thread below with some personal highlights🧵
Let’s sanity check DeepSeek’s claim to train on 2048 GPUs for under 2 months, for a cost of $5.6M. It sort of checks out and sort of doesn't.
The v3 model is an MoE with 37B (out of 671B) active parameters. Let's compare to the cost of a 34B dense model. 🧵
The v3 model is an MoE with 37B (out of 671B) active parameters. Let's compare to the cost of a 34B dense model. 🧵
January 29, 2025 at 5:12 PM
Let’s sanity check DeepSeek’s claim to train on 2048 GPUs for under 2 months, for a cost of $5.6M. It sort of checks out and sort of doesn't.
The v3 model is an MoE with 37B (out of 671B) active parameters. Let's compare to the cost of a 34B dense model. 🧵
The v3 model is an MoE with 37B (out of 671B) active parameters. Let's compare to the cost of a 34B dense model. 🧵