



Tim Kietzmann
@timkietzmann.bsky.social
ML meets Neuroscience #NeuroAI, Full Professor at the Institute of Cognitive Science (Uni Osnabrück), prev. @ Donders Inst., Cambridge University
Friday keeps on giving. Interested in representational drift in macaques? Then come check out Dan's (@anthesdaniel.bsky.social) work providing first evidence for a sequence of three different, yet comparatively stable clusters in V4.
Time: August 15, 2-5pm
Location: Poster C142, de Brug & E‑Hall
Time: August 15, 2-5pm
Location: Poster C142, de Brug & E‑Hall

August 8, 2025 at 2:21 PM
Friday keeps on giving. Interested in representational drift in macaques? Then come check out Dan's (@anthesdaniel.bsky.social) work providing first evidence for a sequence of three different, yet comparatively stable clusters in V4.
Time: August 15, 2-5pm
Location: Poster C142, de Brug & E‑Hall
Time: August 15, 2-5pm
Location: Poster C142, de Brug & E‑Hall
Another Friday feat: Philip Sulewski's (@psulewski.bsky.social) and @thonor.bsky.social's
modelling work. Predictive remapping and allocentric coding as consequences of energy efficiency in RNN models of active vision
Time: Friday, August 15, 2:00 – 5:00 pm,
Location: Poster C112, de Brug & E‑Hall
modelling work. Predictive remapping and allocentric coding as consequences of energy efficiency in RNN models of active vision
Time: Friday, August 15, 2:00 – 5:00 pm,
Location: Poster C112, de Brug & E‑Hall
August 8, 2025 at 2:21 PM
Another Friday feat: Philip Sulewski's (@psulewski.bsky.social) and @thonor.bsky.social's
modelling work. Predictive remapping and allocentric coding as consequences of energy efficiency in RNN models of active vision
Time: Friday, August 15, 2:00 – 5:00 pm,
Location: Poster C112, de Brug & E‑Hall
modelling work. Predictive remapping and allocentric coding as consequences of energy efficiency in RNN models of active vision
Time: Friday, August 15, 2:00 – 5:00 pm,
Location: Poster C112, de Brug & E‑Hall
Also on Friday, Victoria Bosch (@initself.bsky.social) presents her superb work on fusing brain scans with LLMs.
CorText-AMA: brain-language fusion as a new tool for probing visually evoked brain responses
Time: 2 – 5 pm
Location: Poster C119, de Brug & E‑Hall
2025.ccneuro.org/poster/?id=n...
CorText-AMA: brain-language fusion as a new tool for probing visually evoked brain responses
Time: 2 – 5 pm
Location: Poster C119, de Brug & E‑Hall
2025.ccneuro.org/poster/?id=n...

August 8, 2025 at 2:21 PM
Also on Friday, Victoria Bosch (@initself.bsky.social) presents her superb work on fusing brain scans with LLMs.
CorText-AMA: brain-language fusion as a new tool for probing visually evoked brain responses
Time: 2 – 5 pm
Location: Poster C119, de Brug & E‑Hall
2025.ccneuro.org/poster/?id=n...
CorText-AMA: brain-language fusion as a new tool for probing visually evoked brain responses
Time: 2 – 5 pm
Location: Poster C119, de Brug & E‑Hall
2025.ccneuro.org/poster/?id=n...
On Friday, Carmen @carmenamme.bsky.social has a talk & poster on exciting AVS analyses. Encoding of Fixation-Specific Visual Information: No Evidence of Information Carry-Over between Fixations
Talk: 12:00 – 1:00 pm, Room C1.04
Poster: C153, 2:00 – 5:00 pm, de Brug &E‑Hall
www.kietzmannlab.org/avs/
Talk: 12:00 – 1:00 pm, Room C1.04
Poster: C153, 2:00 – 5:00 pm, de Brug &E‑Hall
www.kietzmannlab.org/avs/

August 8, 2025 at 2:21 PM
On Friday, Carmen @carmenamme.bsky.social has a talk & poster on exciting AVS analyses. Encoding of Fixation-Specific Visual Information: No Evidence of Information Carry-Over between Fixations
Talk: 12:00 – 1:00 pm, Room C1.04
Poster: C153, 2:00 – 5:00 pm, de Brug &E‑Hall
www.kietzmannlab.org/avs/
Talk: 12:00 – 1:00 pm, Room C1.04
Poster: C153, 2:00 – 5:00 pm, de Brug &E‑Hall
www.kietzmannlab.org/avs/
On Tuesday, Sushrut's (@sushrutthorat.bsky.social) Glimpse Prediction Networks will make their debut: a self-supervised deep learning approach for scene-representations that align extremely well with human ventral stream.
Time: August 12, 1:30 – 4:30 pm
Location: A55, de Brug & E‑Hall
Time: August 12, 1:30 – 4:30 pm
Location: A55, de Brug & E‑Hall

August 8, 2025 at 2:21 PM
On Tuesday, Sushrut's (@sushrutthorat.bsky.social) Glimpse Prediction Networks will make their debut: a self-supervised deep learning approach for scene-representations that align extremely well with human ventral stream.
Time: August 12, 1:30 – 4:30 pm
Location: A55, de Brug & E‑Hall
Time: August 12, 1:30 – 4:30 pm
Location: A55, de Brug & E‑Hall
First, @zejinlu.bsky.social will talk about how adopting a human developmental visual diet yields robust, shape-based AI vision. Biological inspiration for the win!
Talk Time/Location: Monday, 3-6 pm, Room A2.11
Poster Time/Location: Friday, 2-5 pm, C116 at de Brug & E‑Hall
Talk Time/Location: Monday, 3-6 pm, Room A2.11
Poster Time/Location: Friday, 2-5 pm, C116 at de Brug & E‑Hall

August 8, 2025 at 2:21 PM
First, @zejinlu.bsky.social will talk about how adopting a human developmental visual diet yields robust, shape-based AI vision. Biological inspiration for the win!
Talk Time/Location: Monday, 3-6 pm, Room A2.11
Poster Time/Location: Friday, 2-5 pm, C116 at de Brug & E‑Hall
Talk Time/Location: Monday, 3-6 pm, Room A2.11
Poster Time/Location: Friday, 2-5 pm, C116 at de Brug & E‑Hall
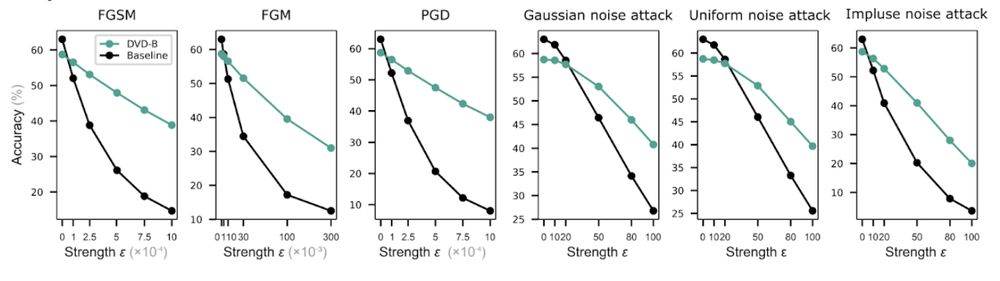
Result 4: How about adversarial robustness? DVD-trained models also showed greater resilience to all black- and white-box attacks tested, performing 3–5 times better than baselines under high-strength perturbations. 8/
July 8, 2025 at 1:04 PM
Result 4: How about adversarial robustness? DVD-trained models also showed greater resilience to all black- and white-box attacks tested, performing 3–5 times better than baselines under high-strength perturbations. 8/
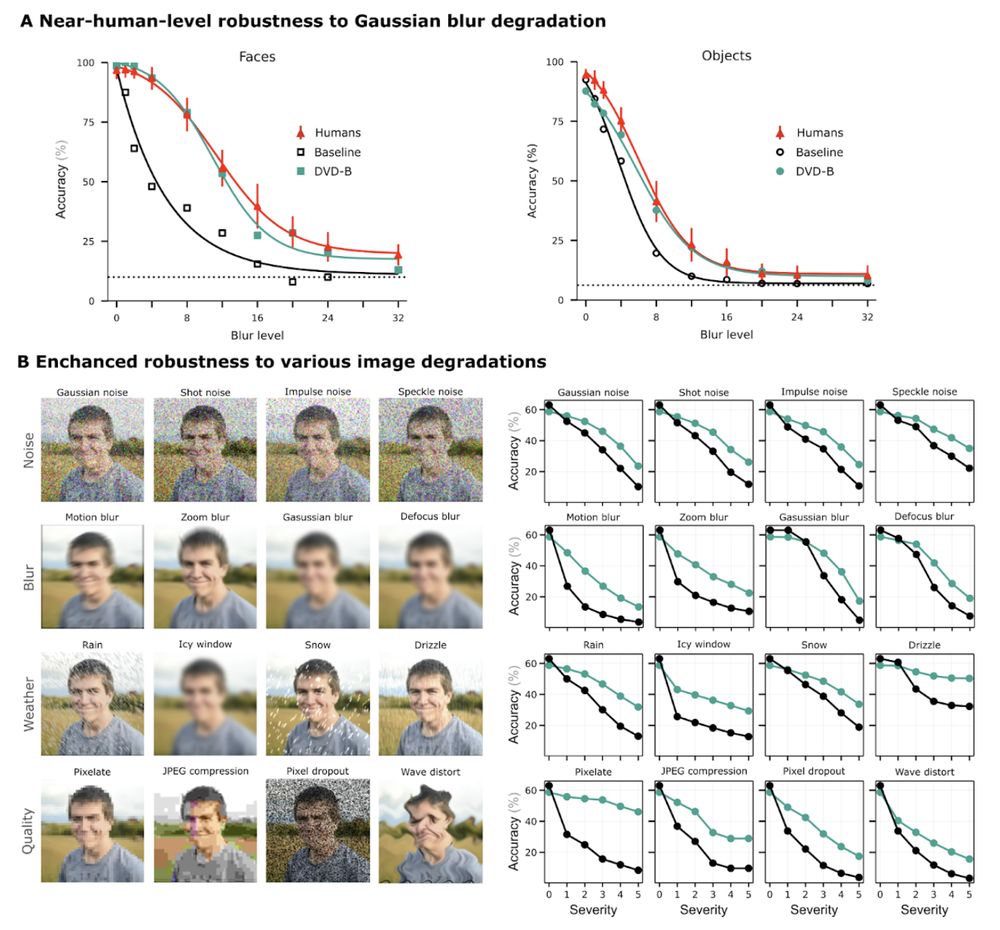
Result 3: DVD-trained models exhibit more human-like robustness to Gaussian blur compared to baselines, plus an overall improved robustness to all image perturbations tested. 7/
July 8, 2025 at 1:04 PM
Result 3: DVD-trained models exhibit more human-like robustness to Gaussian blur compared to baselines, plus an overall improved robustness to all image perturbations tested. 7/
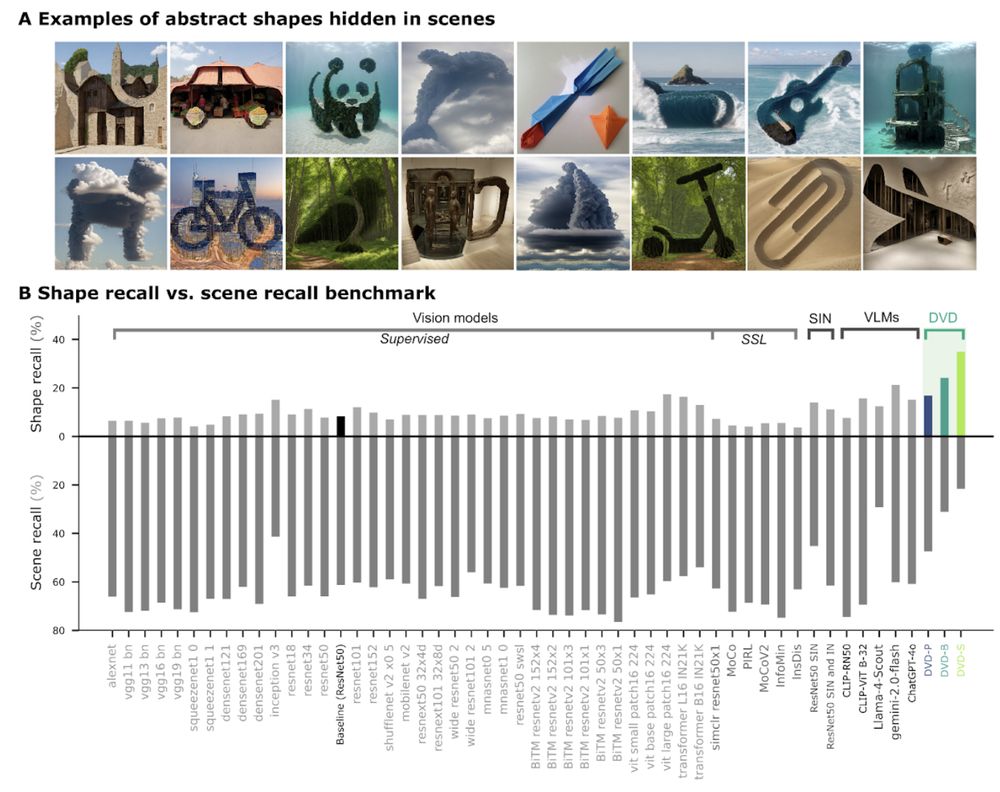
Result 2: DVD-training enabled abstract shape recognition in cases where AI frontier models, despite being explicitly prompted, fail spectacularly.
t-SNE nicely visualises the fundamentally different approach of DVD-trained models. 6/
t-SNE nicely visualises the fundamentally different approach of DVD-trained models. 6/

July 8, 2025 at 1:04 PM
Result 2: DVD-training enabled abstract shape recognition in cases where AI frontier models, despite being explicitly prompted, fail spectacularly.
t-SNE nicely visualises the fundamentally different approach of DVD-trained models. 6/
t-SNE nicely visualises the fundamentally different approach of DVD-trained models. 6/
Layerwise relevance propagation revealed that DVD-training resulted in a different recognition strategy than baseline controls: DVD-training puts emphasis on large parts of the objects, rather than highly localised or highly distributed features. 5/

July 8, 2025 at 1:04 PM
Layerwise relevance propagation revealed that DVD-training resulted in a different recognition strategy than baseline controls: DVD-training puts emphasis on large parts of the objects, rather than highly localised or highly distributed features. 5/
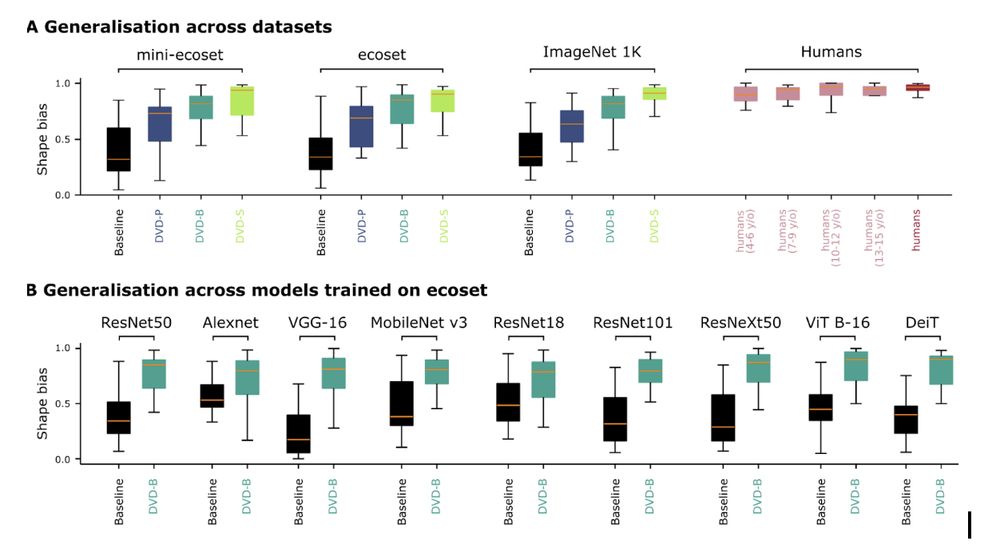
Result 1: DVD training massively improves shape-reliance in ANNs.
We report a new state of the art, reaching human-level shape-bias (even though the model uses orders of magnitude less data and parameters). This was true for all datasets and architectures tested 4/
We report a new state of the art, reaching human-level shape-bias (even though the model uses orders of magnitude less data and parameters). This was true for all datasets and architectures tested 4/
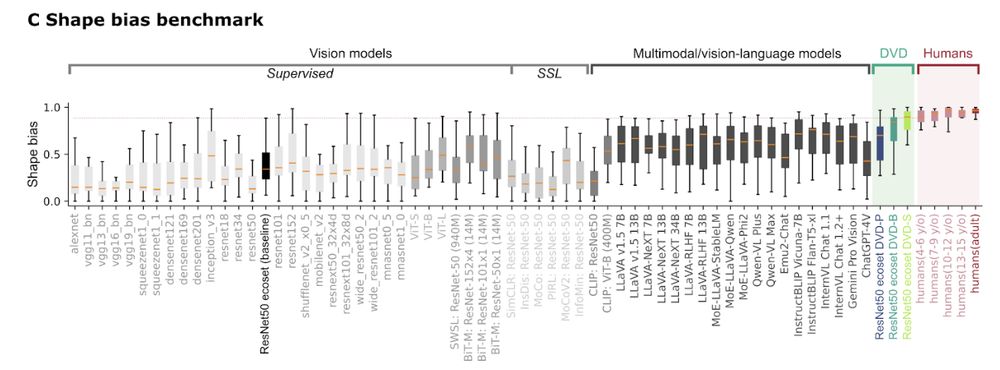
July 8, 2025 at 1:04 PM
Result 1: DVD training massively improves shape-reliance in ANNs.
We report a new state of the art, reaching human-level shape-bias (even though the model uses orders of magnitude less data and parameters). This was true for all datasets and architectures tested 4/
We report a new state of the art, reaching human-level shape-bias (even though the model uses orders of magnitude less data and parameters). This was true for all datasets and architectures tested 4/
We then test the resulting DNNs across a range of conditions, each selected because they are challenging to AI: (i) shape-texture bias, (ii) recognising abstract shapes embedded in complex backgrounds, (iii) robustness to image perturbations, and (iv) adversarial robustness, 3/

July 8, 2025 at 1:04 PM
We then test the resulting DNNs across a range of conditions, each selected because they are challenging to AI: (i) shape-texture bias, (ii) recognising abstract shapes embedded in complex backgrounds, (iii) robustness to image perturbations, and (iv) adversarial robustness, 3/
The idea: instead of high-fidelity training from the get-go (the gold standard), we simulate the visual development from newborns to 25 years of age by synthesising decades of developmental vision research into an AI preprocessing pipeline (Developmental Visual Diet - DVD) 2/
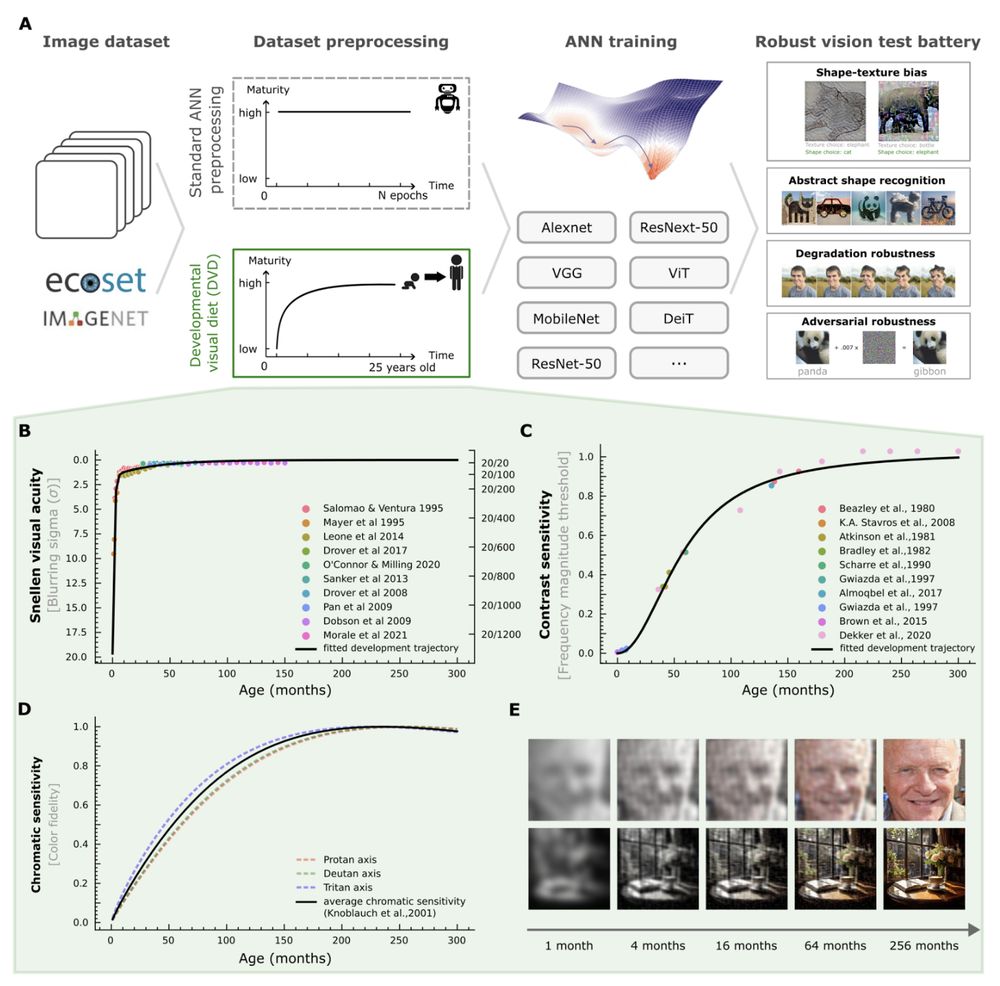
July 8, 2025 at 1:04 PM
The idea: instead of high-fidelity training from the get-go (the gold standard), we simulate the visual development from newborns to 25 years of age by synthesising decades of developmental vision research into an AI preprocessing pipeline (Developmental Visual Diet - DVD) 2/
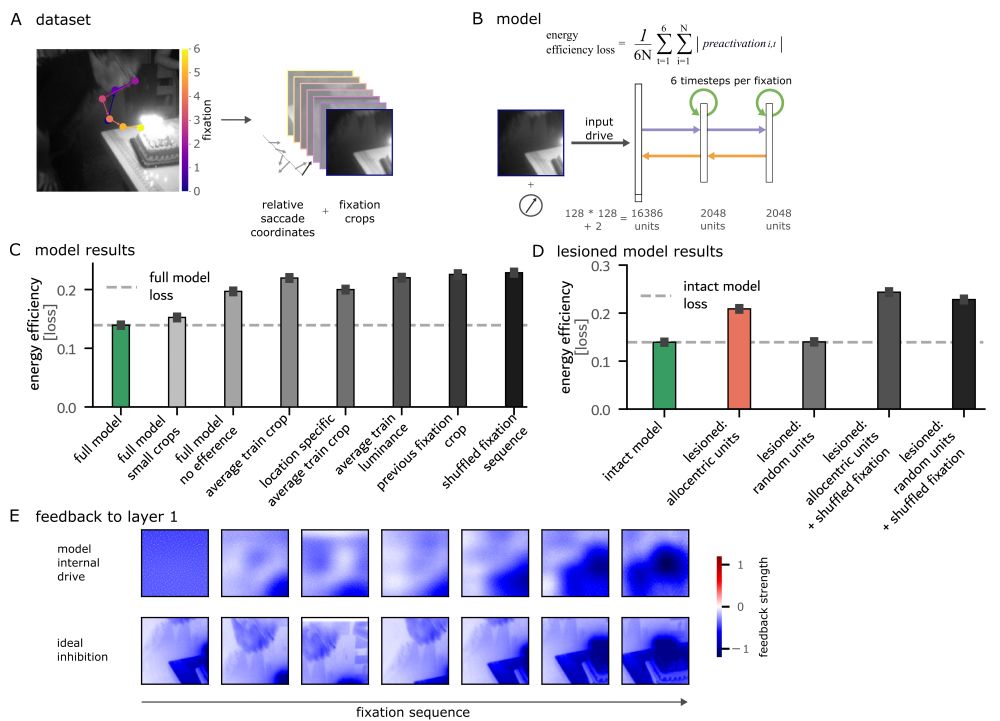
Second, we found these computations rely on just 0.5% of units. These units had learned to transform relative saccade targets into a world-centered reference frame. Lesioning them collapsed predictive remapping entirely. Instead, the model predicted the current fixation to also be the next. 5/6
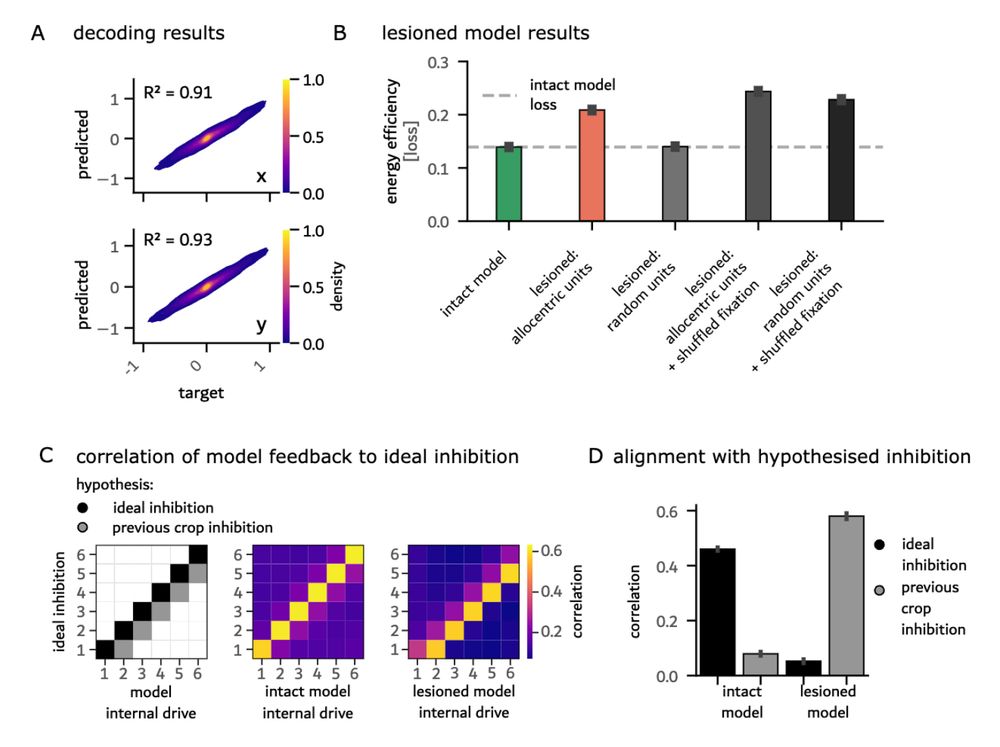
June 5, 2025 at 1:14 PM
Second, we found these computations rely on just 0.5% of units. These units had learned to transform relative saccade targets into a world-centered reference frame. Lesioning them collapsed predictive remapping entirely. Instead, the model predicted the current fixation to also be the next. 5/6
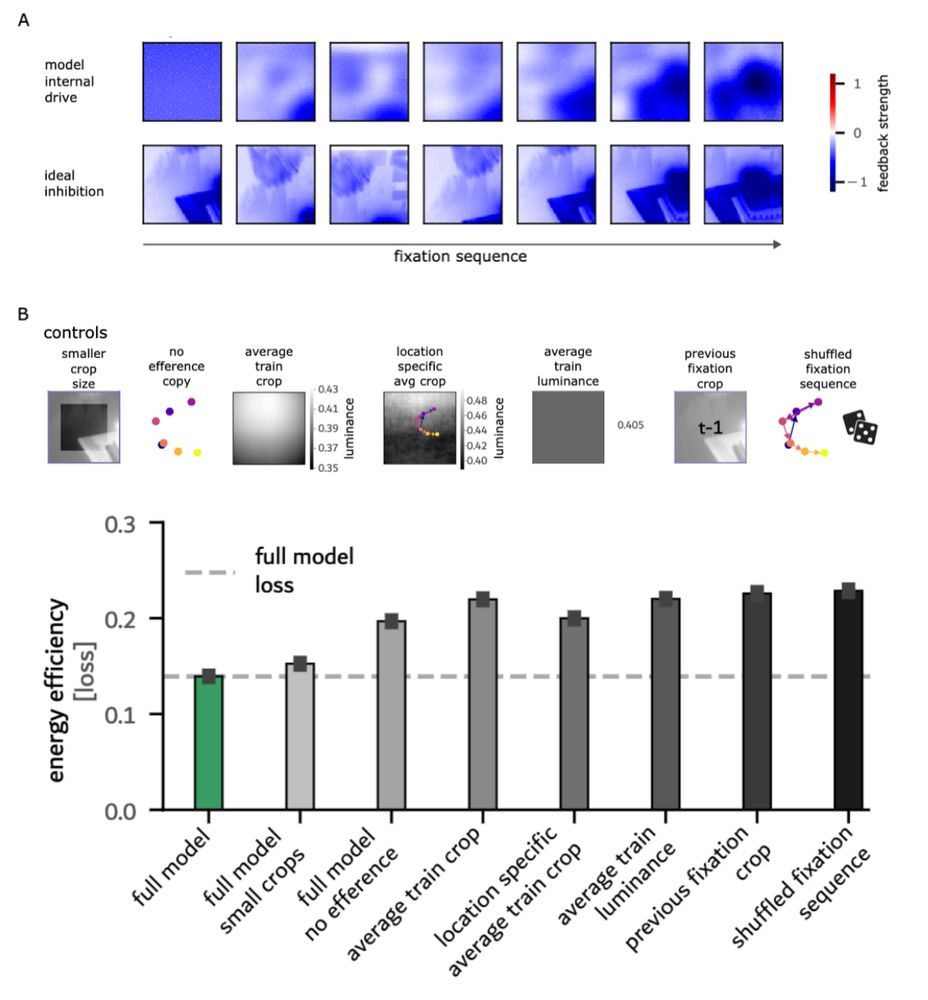
We make two important observations on emergent properties: First, the RNNs spontaneously learn to predict and inhibit upcoming fixation content. Energy minimisation alone drove sophisticated predictive computations supporting visual stability. 4/6
June 5, 2025 at 1:14 PM
We make two important observations on emergent properties: First, the RNNs spontaneously learn to predict and inhibit upcoming fixation content. Energy minimisation alone drove sophisticated predictive computations supporting visual stability. 4/6
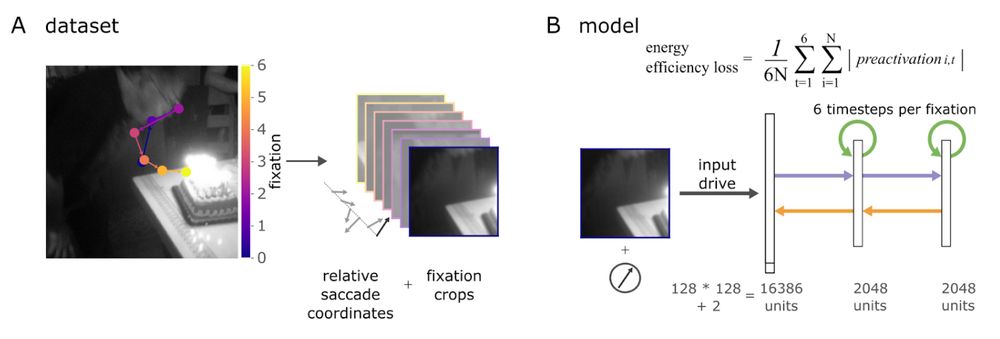
Is this capacity genetically hardwired, or can it emerge from simpler principles? To find out, we trained RNNs on human-like fixation sequences (image patches and efference copies) on natural scenes. Only constraint: minimise energy consumption (unit preactivation). 3/6
June 5, 2025 at 1:14 PM
Is this capacity genetically hardwired, or can it emerge from simpler principles? To find out, we trained RNNs on human-like fixation sequences (image patches and efference copies) on natural scenes. Only constraint: minimise energy consumption (unit preactivation). 3/6
Can seemingly complex multi-area computations in the brain emerge from the need for energy efficient computation? In our new preprint on predictive remapping in active vision, we report on such a case.
Let us take you for a spin. 1/6 www.biorxiv.org/content/10.1...
Let us take you for a spin. 1/6 www.biorxiv.org/content/10.1...

June 5, 2025 at 1:14 PM
Can seemingly complex multi-area computations in the brain emerge from the need for energy efficient computation? In our new preprint on predictive remapping in active vision, we report on such a case.
Let us take you for a spin. 1/6 www.biorxiv.org/content/10.1...
Let us take you for a spin. 1/6 www.biorxiv.org/content/10.1...
We have something in common then 😊
Among others, I keep telling people a specific story from this very book, suggesting that if the path is long, we need to focus on taking one step at a time and not be worried about how far in the distance the goal is, in order to be able to not panic and give up.
Among others, I keep telling people a specific story from this very book, suggesting that if the path is long, we need to focus on taking one step at a time and not be worried about how far in the distance the goal is, in order to be able to not panic and give up.

April 21, 2025 at 9:03 AM
We have something in common then 😊
Among others, I keep telling people a specific story from this very book, suggesting that if the path is long, we need to focus on taking one step at a time and not be worried about how far in the distance the goal is, in order to be able to not panic and give up.
Among others, I keep telling people a specific story from this very book, suggesting that if the path is long, we need to focus on taking one step at a time and not be worried about how far in the distance the goal is, in order to be able to not panic and give up.
#CCN2025 abstract acceptances were sent out this morning.
I'll post a summary of each of our projects closer to the conference.
Looking forward to seeing you all in Amsterdam!
I'll post a summary of each of our projects closer to the conference.
Looking forward to seeing you all in Amsterdam!

April 21, 2025 at 8:40 AM
#CCN2025 abstract acceptances were sent out this morning.
I'll post a summary of each of our projects closer to the conference.
Looking forward to seeing you all in Amsterdam!
I'll post a summary of each of our projects closer to the conference.
Looking forward to seeing you all in Amsterdam!
This year we ran another meme contest as part of my ML4CCN lecture series. Student submissions were fantastic.
Guess the paper...
Guess the paper...

February 6, 2025 at 7:26 PM
This year we ran another meme contest as part of my ML4CCN lecture series. Student submissions were fantastic.
Guess the paper...
Guess the paper...
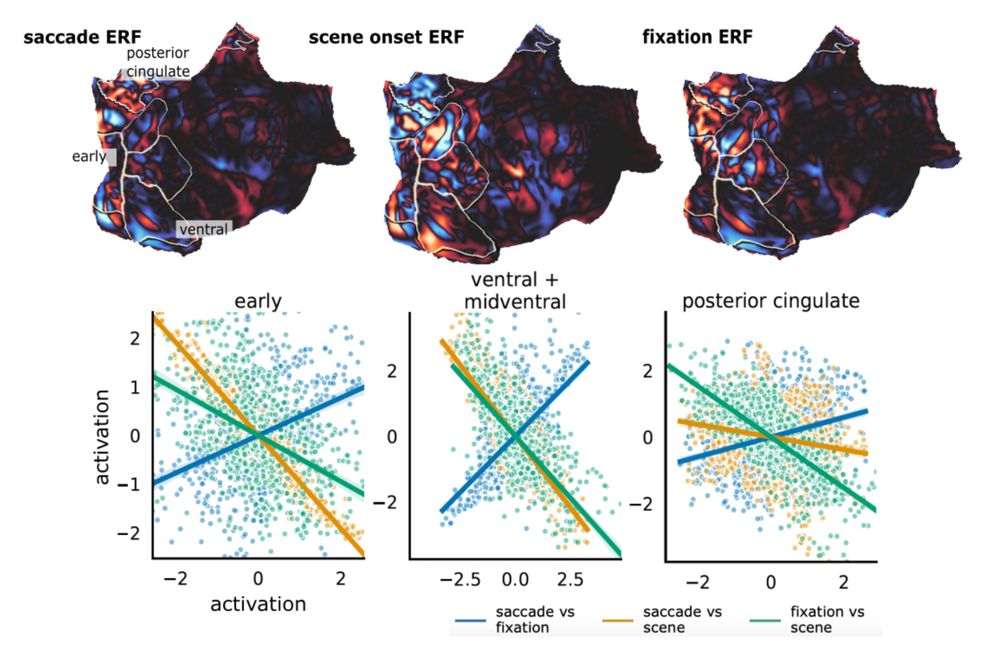
7/9 Let’s take this one step further. How does the neural response to saccade onset compare to stimulus onsets? Turns out that saccade elicited responses are **anticorrelated** to scene-onset responses, i.e. they produced opposite field patterns in source space.
November 1, 2024 at 4:12 PM
7/9 Let’s take this one step further. How does the neural response to saccade onset compare to stimulus onsets? Turns out that saccade elicited responses are **anticorrelated** to scene-onset responses, i.e. they produced opposite field patterns in source space.
6/9 What we found was different. Instead of the fixation onset, the **saccade onset** explained most of the variance in latency and amplitude of the M100. That is, the bulk of the M100 (P100 also, as shown in a separate dataset) is NOT fixation-elicited.

November 1, 2024 at 4:12 PM
6/9 What we found was different. Instead of the fixation onset, the **saccade onset** explained most of the variance in latency and amplitude of the M100. That is, the bulk of the M100 (P100 also, as shown in a separate dataset) is NOT fixation-elicited.
5/9 One of the most prominent, heavily studied components in visual neuroscience is the P100/M100, a prime candidate to compare active to passive vision. We expected this component to occur in response to fixation onset.

November 1, 2024 at 4:11 PM
5/9 One of the most prominent, heavily studied components in visual neuroscience is the P100/M100, a prime candidate to compare active to passive vision. We expected this component to occur in response to fixation onset.
4/9 To investigate neural responses of active vision, we went all in: head-stabilized MEG+high-res eye tracking, recorded while participants were actively exploring thousands of natural scenes.
This way, we collected more than 210k fixation events at high temporal resolution.
This way, we collected more than 210k fixation events at high temporal resolution.

November 1, 2024 at 4:11 PM
4/9 To investigate neural responses of active vision, we went all in: head-stabilized MEG+high-res eye tracking, recorded while participants were actively exploring thousands of natural scenes.
This way, we collected more than 210k fixation events at high temporal resolution.
This way, we collected more than 210k fixation events at high temporal resolution.
3/9 For example, it is typically assumed that neural processes elicited by stimulus onsets are similar to fixation onsets.
Natural vision is different, however. Eye-movements are initiated by the brain itself, and where we look is less surprising than a random image stream.
Natural vision is different, however. Eye-movements are initiated by the brain itself, and where we look is less surprising than a random image stream.

November 1, 2024 at 4:10 PM
3/9 For example, it is typically assumed that neural processes elicited by stimulus onsets are similar to fixation onsets.
Natural vision is different, however. Eye-movements are initiated by the brain itself, and where we look is less surprising than a random image stream.
Natural vision is different, however. Eye-movements are initiated by the brain itself, and where we look is less surprising than a random image stream.