


Tiancheng Hu
@tiancheng.bsky.social
PhD student @CambridgeLTL; Previously @DLAB @EPFL; Interested in NLP and CSS. Apple Scholar, Gates Scholar.
Personalization certainly needs boundaries and we show how that could look like!

🚨 New main paper out at #EMNLP2025! 🚨
⚡ We show that personalization of content moderation models can be harmful and perpetuate hate speech, defeating the purpose of the system and hurting the community.
We argue that personalized moderation needs boundaries, and we show how to build them.
⚡ We show that personalization of content moderation models can be harmful and perpetuate hate speech, defeating the purpose of the system and hurting the community.
We argue that personalized moderation needs boundaries, and we show how to build them.
October 31, 2025 at 5:24 PM
Personalization certainly needs boundaries and we show how that could look like!
Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
October 30, 2025 at 5:00 PM
Instruction tuning unlocks incredible skills in LLMs, but at a cost: they become dangerously overconfident.
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
You face a choice: a well-calibrated base model or a capable but unreliable instruct model.
What if you didn't have to choose? What if you could navigate the trade-off?
(1/8)
River, Yinhong and I will all be in person and we look forward to the discussions!

Cohere Labs x EMNLP 2025 "When Personalization Meets Reality: A Multi-Faceted Analysis of Personalized Preference Learning"
Congrats to authors Yijiang River Dong, @tiancheng.bsky.social, Yinhong Liu, Ahmet Üstün, Nigel Collier.
📜 arxiv.org/abs/2502.19158
Congrats to authors Yijiang River Dong, @tiancheng.bsky.social, Yinhong Liu, Ahmet Üstün, Nigel Collier.
📜 arxiv.org/abs/2502.19158

October 29, 2025 at 9:12 PM
River, Yinhong and I will all be in person and we look forward to the discussions!
Reposted by Tiancheng Hu

See you next week at EMNLP!
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social

Scaling Low-Resource MT via Synthetic Data Generation with LLMs
We investigate the potential of LLM-generated synthetic data for improving low-resource Machine Translation (MT). Focusing on seven diverse target languages, we construct a document-level synthetic co...
arxiv.org
October 28, 2025 at 8:16 AM
See you next week at EMNLP!
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social
We will be presenting our work: Scaling Low-Resource MT via Synthetic Data Generation with LLMs
📍 Poster Session 13
📅 Fri, Nov 7, 10:30-12:00 - Hall C
📖 Check it out! arxiv.org/abs/2505.14423
@helsinki-nlp.bsky.social @cambridgenlp.bsky.social @emnlpmeeting.bsky.social
Can AI simulate human behavior? 🧠
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
October 28, 2025 at 4:54 PM
Can AI simulate human behavior? 🧠
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
The promise is revolutionary for science & policy. But there’s a huge "IF": Do these simulations actually reflect reality?
To find out, we introduce SimBench: The first large-scale benchmark for group-level social simulation. (1/9)
Excited to share a "Key Update" from the International AI Safety Report, which I was proud to contribute to.
We took a rigorous, evidence-based look at the latest AI developments. If you want a clear view of where things stand, this is a must-read. 👇
We took a rigorous, evidence-based look at the latest AI developments. If you want a clear view of where things stand, this is a must-read. 👇

AI is evolving too quickly for an annual report to suffice. To help policymakers keep pace, we're introducing the first Key Update to the International AI Safety Report. 🧵⬇️
(1/10)
(1/10)

October 16, 2025 at 10:01 AM
Excited to share a "Key Update" from the International AI Safety Report, which I was proud to contribute to.
We took a rigorous, evidence-based look at the latest AI developments. If you want a clear view of where things stand, this is a must-read. 👇
We took a rigorous, evidence-based look at the latest AI developments. If you want a clear view of where things stand, this is a must-read. 👇
Heading to Vienna today to attend #ACL2025NLP! Let's chat if you are interested in LLM social simulation, personalization, character training and human-centered AI!
July 26, 2025 at 11:21 AM
Heading to Vienna today to attend #ACL2025NLP! Let's chat if you are interested in LLM social simulation, personalization, character training and human-centered AI!
Reposted by Tiancheng Hu

I will be at #acl2025 to present "Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals’ Subjective Text Perceptions" ✨
Huge thank you to my collaborators Jiaxin Pei @paul-rottger.bsky.social Philipp Cimiano @davidjurgens.bsky.social @dirkhovy.bsky.social 🍰
more below
Huge thank you to my collaborators Jiaxin Pei @paul-rottger.bsky.social Philipp Cimiano @davidjurgens.bsky.social @dirkhovy.bsky.social 🍰
more below
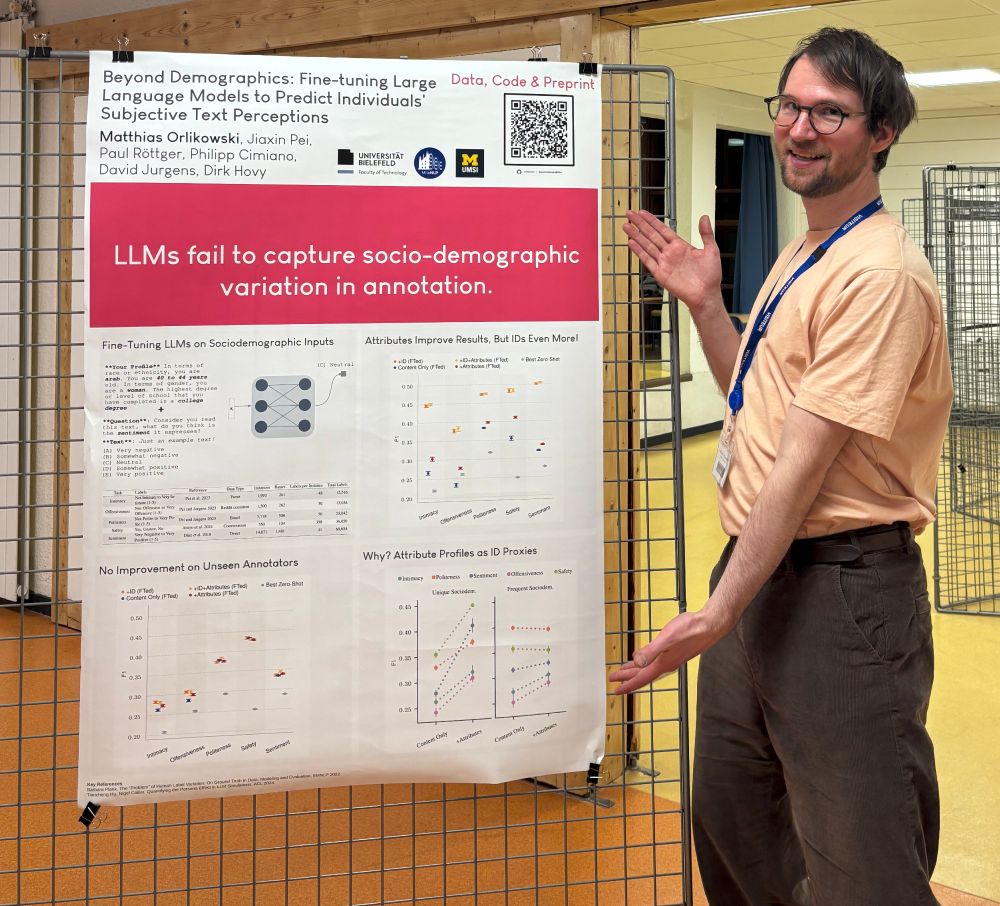
July 20, 2025 at 3:23 PM
I will be at #acl2025 to present "Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals’ Subjective Text Perceptions" ✨
Huge thank you to my collaborators Jiaxin Pei @paul-rottger.bsky.social Philipp Cimiano @davidjurgens.bsky.social @dirkhovy.bsky.social 🍰
more below
Huge thank you to my collaborators Jiaxin Pei @paul-rottger.bsky.social Philipp Cimiano @davidjurgens.bsky.social @dirkhovy.bsky.social 🍰
more below
Working on LLM social simulation and need data?
Excited to announce our iNews paper is accepted to #ACL2025! 🥳 It's a large-scale dataset for predicting individualized affective responses to real-world, multimodal news.
Paper: arxiv.org/abs/2503.03335
Data: huggingface.co/datasets/pit...
Excited to announce our iNews paper is accepted to #ACL2025! 🥳 It's a large-scale dataset for predicting individualized affective responses to real-world, multimodal news.
Paper: arxiv.org/abs/2503.03335
Data: huggingface.co/datasets/pit...

July 9, 2025 at 3:44 PM
Working on LLM social simulation and need data?
Excited to announce our iNews paper is accepted to #ACL2025! 🥳 It's a large-scale dataset for predicting individualized affective responses to real-world, multimodal news.
Paper: arxiv.org/abs/2503.03335
Data: huggingface.co/datasets/pit...
Excited to announce our iNews paper is accepted to #ACL2025! 🥳 It's a large-scale dataset for predicting individualized affective responses to real-world, multimodal news.
Paper: arxiv.org/abs/2503.03335
Data: huggingface.co/datasets/pit...
Reposted by Tiancheng Hu

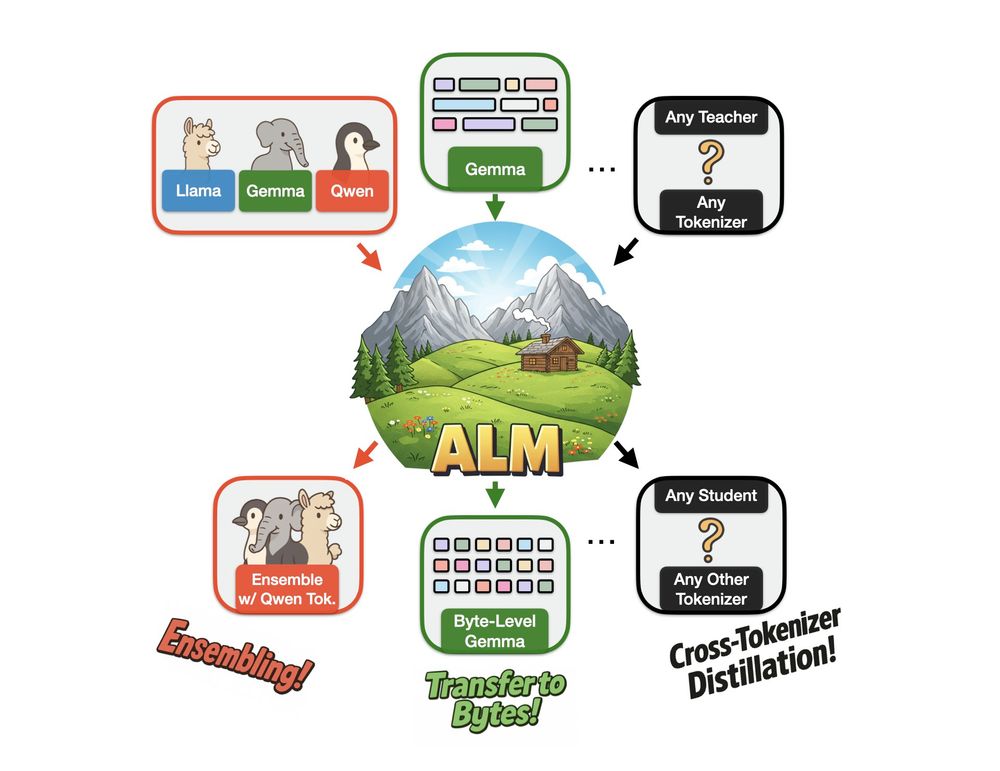
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
April 2, 2025 at 6:36 AM
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
Ever notice how something that makes your blood boil barely registers with your friend? Our emotional reactions aren't universal at all—they're deeply personal. And AI needs to understand that. Excited to share our new paper: "iNews" 🧵 (1/8) arxiv.org/abs/2503.03335

iNews: A Multimodal Dataset for Modeling Personalized Affective Responses to News
Current approaches to emotion detection often overlook the inherent subjectivity of affective experiences, instead relying on aggregated labels that mask individual variations in emotional responses. ...
arxiv.org
March 10, 2025 at 4:47 PM
Ever notice how something that makes your blood boil barely registers with your friend? Our emotional reactions aren't universal at all—they're deeply personal. And AI needs to understand that. Excited to share our new paper: "iNews" 🧵 (1/8) arxiv.org/abs/2503.03335
Great work by @riverdong.bsky.social - we dug deep into existing datasets & algorithms and found quite some surprising stuff

🚨New Paper Alert🚨
Many personalization methods optimize performance but ignore real-world impact.
We examine its effects on:
✅ Performance
⚖️ Fairness: Can it represent minorities fairly?
⚠️ Unintended Effects: Does it harm safety?
🔄 Adaptability: Quickly adapt to new users?
Many personalization methods optimize performance but ignore real-world impact.
We examine its effects on:
✅ Performance
⚖️ Fairness: Can it represent minorities fairly?
⚠️ Unintended Effects: Does it harm safety?
🔄 Adaptability: Quickly adapt to new users?
March 5, 2025 at 4:08 PM
Great work by @riverdong.bsky.social - we dug deep into existing datasets & algorithms and found quite some surprising stuff
Reposted by Tiancheng Hu

Happy to write this News & Views piece on the recent audit showing LLMs picking up "us versus them" biases: www.nature.com/articles/s43... (Read-only version: rdcu.be/d5ovo)
Check out the amazing (original) paper here: www.nature.com/articles/s43...
Check out the amazing (original) paper here: www.nature.com/articles/s43...
Large language models act as if they are part of a group - Nature Computational Science
An extensive audit of large language models reveals that numerous models mirror the ‘us versus them’ thinking seen in human behavior. These social prejudices are likely captured from the biased conten...
www.nature.com
January 2, 2025 at 2:11 PM
Happy to write this News & Views piece on the recent audit showing LLMs picking up "us versus them" biases: www.nature.com/articles/s43... (Read-only version: rdcu.be/d5ovo)
Check out the amazing (original) paper here: www.nature.com/articles/s43...
Check out the amazing (original) paper here: www.nature.com/articles/s43...
1/9 🧵 New paper alert (now in Nature Computational Science)!
As polarisation continues to shape our world, we asked: Do social and political biases transfer to our AI? I.e. do LLMs show ingroup and outgroup bias?
www.nature.com/articles/s43...
As polarisation continues to shape our world, we asked: Do social and political biases transfer to our AI? I.e. do LLMs show ingroup and outgroup bias?
www.nature.com/articles/s43...

Generative language models exhibit social identity biases - Nature Computational Science
Researchers show that large language models exhibit social identity biases similar to humans, having favoritism toward ingroups and hostility toward outgroups. These biases persist across models, trai...
www.nature.com
December 12, 2024 at 10:39 PM
1/9 🧵 New paper alert (now in Nature Computational Science)!
As polarisation continues to shape our world, we asked: Do social and political biases transfer to our AI? I.e. do LLMs show ingroup and outgroup bias?
www.nature.com/articles/s43...
As polarisation continues to shape our world, we asked: Do social and political biases transfer to our AI? I.e. do LLMs show ingroup and outgroup bias?
www.nature.com/articles/s43...
Such an amazing work in so many ways! Well done! Great to see convergent evidence that the more persona information you have about someone, the more accurate your simulation would be. aclanthology.org/2024.acl-lon...
Is there a scaling law for simulation based on persona detailedness?
Is there a scaling law for simulation based on persona detailedness?

November 19, 2024 at 8:50 AM
Such an amazing work in so many ways! Well done! Great to see convergent evidence that the more persona information you have about someone, the more accurate your simulation would be. aclanthology.org/2024.acl-lon...
Is there a scaling law for simulation based on persona detailedness?
Is there a scaling law for simulation based on persona detailedness?
🚨New Preprint: "Generative language models exhibit social identity biases" Did you know LLMs mirror human-like biases, showing human-levels of ingroup solidarity & outgroup hostility?
@profsanderlinden.bsky.social @steverathje.bsky.social
📄 arxiv.org/abs/2310.15819
@profsanderlinden.bsky.social @steverathje.bsky.social
📄 arxiv.org/abs/2310.15819


December 1, 2023 at 6:01 PM
🚨New Preprint: "Generative language models exhibit social identity biases" Did you know LLMs mirror human-like biases, showing human-levels of ingroup solidarity & outgroup hostility?
@profsanderlinden.bsky.social @steverathje.bsky.social
📄 arxiv.org/abs/2310.15819
@profsanderlinden.bsky.social @steverathje.bsky.social
📄 arxiv.org/abs/2310.15819