



Taylor Webb
@taylorwwebb.bsky.social
Studying cognition in humans and machines https://scholar.google.com/citations?user=WCmrJoQAAAAJ&hl=en
Agreed! I just meant that you can parameterize a task rep by giving someone verbal instructions (which is a very convenient way to specify tasks zero-shot). I agree the reps themselves aren’t likely to be encoded in natural langage.
October 8, 2025 at 12:04 PM
Agreed! I just meant that you can parameterize a task rep by giving someone verbal instructions (which is a very convenient way to specify tasks zero-shot). I agree the reps themselves aren’t likely to be encoded in natural langage.
To be more precise, language is used in this model to 1) specify the functional role of each module, 2) mediate communication between modules, and 3) specify the task. 3 is certainly the case for PFC, but I assume not 1 and 2.
October 8, 2025 at 1:52 AM
To be more precise, language is used in this model to 1) specify the functional role of each module, 2) mediate communication between modules, and 3) specify the task. 3 is certainly the case for PFC, but I assume not 1 and 2.
Good question! Natural language is useful here primarily because it’s a convenient way to specify planning tasks without needing domain-specific planning languages, which are a major bottleneck in classical planning methods.
October 7, 2025 at 1:49 PM
Good question! Natural language is useful here primarily because it’s a convenient way to specify planning tasks without needing domain-specific planning languages, which are a major bottleneck in classical planning methods.
Overall, these results highlight the potential of a factorized brain-like approach to improve planning in LLMs. Please check out the paper for many more analyses and results!
October 6, 2025 at 9:51 PM
Overall, these results highlight the potential of a factorized brain-like approach to improve planning in LLMs. Please check out the paper for many more analyses and results!
We also found benefits in a range of other planning problems (including standardized benchmarks such as PlanBench), and even some degree of transfer between different planning problems.

October 6, 2025 at 9:51 PM
We also found benefits in a range of other planning problems (including standardized benchmarks such as PlanBench), and even some degree of transfer between different planning problems.
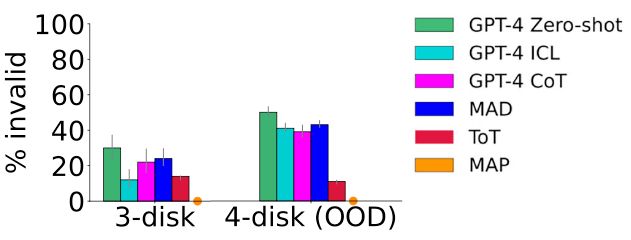
Particularly notable was the fact that this approach completely eliminated invalid moves (i.e. moves that violate the constraints of the planning problem), even in out-of-distribution settings.
October 6, 2025 at 9:51 PM
Particularly notable was the fact that this approach completely eliminated invalid moves (i.e. moves that violate the constraints of the planning problem), even in out-of-distribution settings.
We tested this approach on classic planning problems (e.g. tower of hanoi) that still pose significant challenges for LLMs and related models, finding that this modular approach significantly improved performance.

October 6, 2025 at 9:51 PM
We tested this approach on classic planning problems (e.g. tower of hanoi) that still pose significant challenges for LLMs and related models, finding that this modular approach significantly improved performance.
To address this, we developed an agentic architecture in which planning is factorized into subprocesses such as action selection, error monitoring etc (each implemented by a separate LLM), taking inspiration from both reinforcement learning and theories of decision-making in the human brain.

October 6, 2025 at 9:51 PM
To address this, we developed an agentic architecture in which planning is factorized into subprocesses such as action selection, error monitoring etc (each implemented by a separate LLM), taking inspiration from both reinforcement learning and theories of decision-making in the human brain.
Interestingly, we found that key subprocesses could often reliably be carried out by LLMs, but the coordination of multiple subprocesses was challenging. For instance, LLMs can often accurately identify when plans involve errors (monitoring), but persist in making those errors when planning.
October 6, 2025 at 9:51 PM
Interestingly, we found that key subprocesses could often reliably be carried out by LLMs, but the coordination of multiple subprocesses was challenging. For instance, LLMs can often accurately identify when plans involve errors (monitoring), but persist in making those errors when planning.
The motivation for this work was the observation that LLMs display very limited planning abilities, as demonstrated e.g. by work from @neuroai.bsky.social neurips.cc/virtual/2023... showing difficulty with even relatively simple planning problems.
NeurIPS Poster Evaluating Cognitive Maps and Planning in Large Language Models with CogEvalNeurIPS 2023
neurips.cc
October 6, 2025 at 9:51 PM
The motivation for this work was the observation that LLMs display very limited planning abilities, as demonstrated e.g. by work from @neuroai.bsky.social neurips.cc/virtual/2023... showing difficulty with even relatively simple planning problems.