



Taylor Webb
@taylorwwebb.bsky.social
Studying cognition in humans and machines https://scholar.google.com/citations?user=WCmrJoQAAAAJ&hl=en
We also found benefits in a range of other planning problems (including standardized benchmarks such as PlanBench), and even some degree of transfer between different planning problems.

October 6, 2025 at 9:51 PM
We also found benefits in a range of other planning problems (including standardized benchmarks such as PlanBench), and even some degree of transfer between different planning problems.
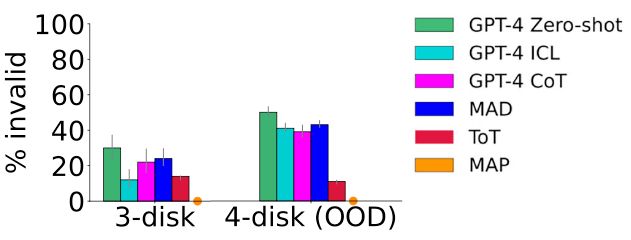
Particularly notable was the fact that this approach completely eliminated invalid moves (i.e. moves that violate the constraints of the planning problem), even in out-of-distribution settings.
October 6, 2025 at 9:51 PM
Particularly notable was the fact that this approach completely eliminated invalid moves (i.e. moves that violate the constraints of the planning problem), even in out-of-distribution settings.
We tested this approach on classic planning problems (e.g. tower of hanoi) that still pose significant challenges for LLMs and related models, finding that this modular approach significantly improved performance.

October 6, 2025 at 9:51 PM
We tested this approach on classic planning problems (e.g. tower of hanoi) that still pose significant challenges for LLMs and related models, finding that this modular approach significantly improved performance.
To address this, we developed an agentic architecture in which planning is factorized into subprocesses such as action selection, error monitoring etc (each implemented by a separate LLM), taking inspiration from both reinforcement learning and theories of decision-making in the human brain.

October 6, 2025 at 9:51 PM
To address this, we developed an agentic architecture in which planning is factorized into subprocesses such as action selection, error monitoring etc (each implemented by a separate LLM), taking inspiration from both reinforcement learning and theories of decision-making in the human brain.
We also investigated two additional tasks -- letter string analogies and verbal analogies -- finding that similar mechanisms support reasoning in those tasks (though the specific attention heads differ somewhat between tasks/relations, especially for verbal analogies).

June 23, 2025 at 3:46 PM
We also investigated two additional tasks -- letter string analogies and verbal analogies -- finding that similar mechanisms support reasoning in those tasks (though the specific attention heads differ somewhat between tasks/relations, especially for verbal analogies).
We've added tests for several other models (including models from the Qwen, Gemma, and GPT-2 families), finding that all models show robust evidence for the presence of symbolic mechanisms, except GPT-2 (consistent with GPT-2's inability to perform abstract reasoning).

June 23, 2025 at 3:46 PM
We've added tests for several other models (including models from the Qwen, Gemma, and GPT-2 families), finding that all models show robust evidence for the presence of symbolic mechanisms, except GPT-2 (consistent with GPT-2's inability to perform abstract reasoning).
Interestingly, despite the lower overall performance, these models were sensitive to factors that also affect human performance, showing improved performance with more in-context examples, and decreased performance for problems involve a greater number of objects.

April 3, 2025 at 8:04 PM
Interestingly, despite the lower overall performance, these models were sensitive to factors that also affect human performance, showing improved performance with more in-context examples, and decreased performance for problems involve a greater number of objects.
Here, we looked at problems with lower visual complexity, involving only a handful of objects. On problems involving both real-world and synthetic images, we found that multimodal models performed better than chance, but underperformed relative to human participants.

April 3, 2025 at 8:04 PM
Here, we looked at problems with lower visual complexity, involving only a handful of objects. On problems involving both real-world and synthetic images, we found that multimodal models performed better than chance, but underperformed relative to human participants.
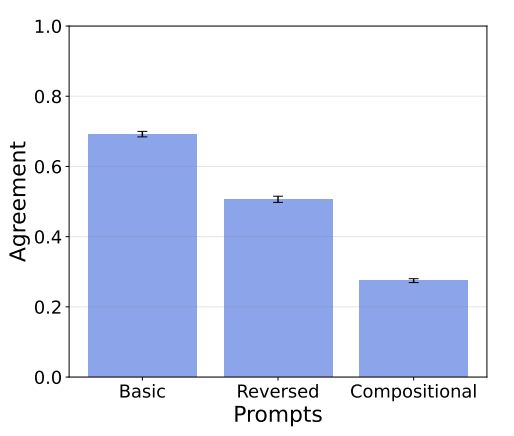
However, these improvements weren't robust to various variations, e.g. DALL-E 3 tended to perform worse on reversed versions of the same relations, and found prompts involving the composition of multiple relations to be especially challenging.
April 3, 2025 at 8:04 PM
However, these improvements weren't robust to various variations, e.g. DALL-E 3 tended to perform worse on reversed versions of the same relations, and found prompts involving the composition of multiple relations to be especially challenging.
We found that DALL-E 3 performs much better at generating relational scenes, especially for scenes involving basic spatial relations.

April 3, 2025 at 8:04 PM
We found that DALL-E 3 performs much better at generating relational scenes, especially for scenes involving basic spatial relations.
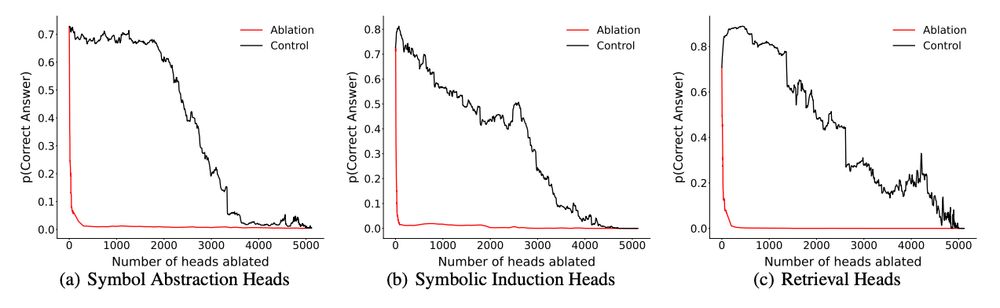
Finally, using ablation analyses, we confirmed that these attention heads were necessary to perform the abstract reasoning task. (11/N)
March 10, 2025 at 7:08 PM
Finally, using ablation analyses, we confirmed that these attention heads were necessary to perform the abstract reasoning task. (11/N)
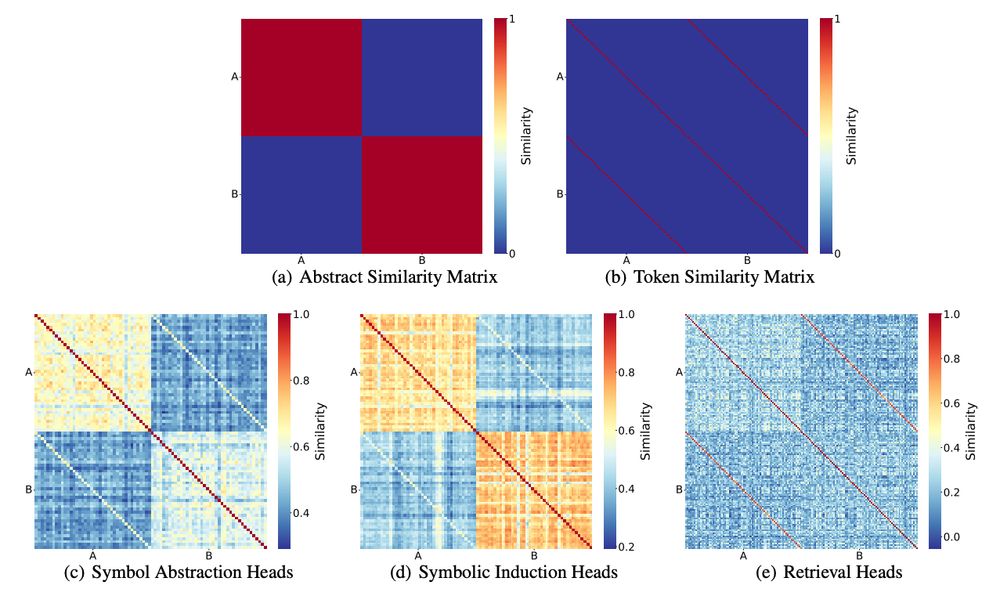
Using representational similarity analyses, we confirmed that the outputs of these attention heads represented the hypothesized variables: the abstraction heads and symbolic induction heads primarily represented abstract symbols, whereas the retrieval heads primarily represented tokens. (10/N)
March 10, 2025 at 7:08 PM
Using representational similarity analyses, we confirmed that the outputs of these attention heads represented the hypothesized variables: the abstraction heads and symbolic induction heads primarily represented abstract symbols, whereas the retrieval heads primarily represented tokens. (10/N)
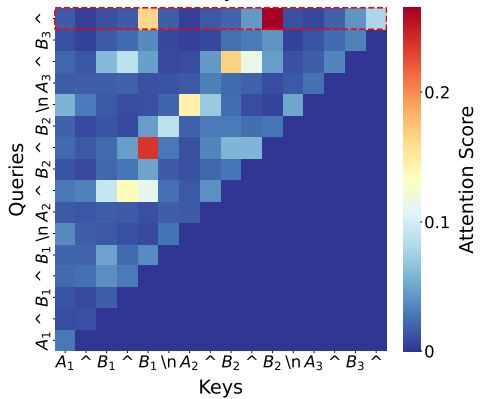
Using attention analyses, we confirmed that these heads' attention patterns were consistent with the hypothesized mechanisms. For instance, for symbolic induction heads, attention was primarily directed to tokens that instantiated the same abstract variable as the next token. (9/N)
March 10, 2025 at 7:08 PM
Using attention analyses, we confirmed that these heads' attention patterns were consistent with the hypothesized mechanisms. For instance, for symbolic induction heads, attention was primarily directed to tokens that instantiated the same abstract variable as the next token. (9/N)
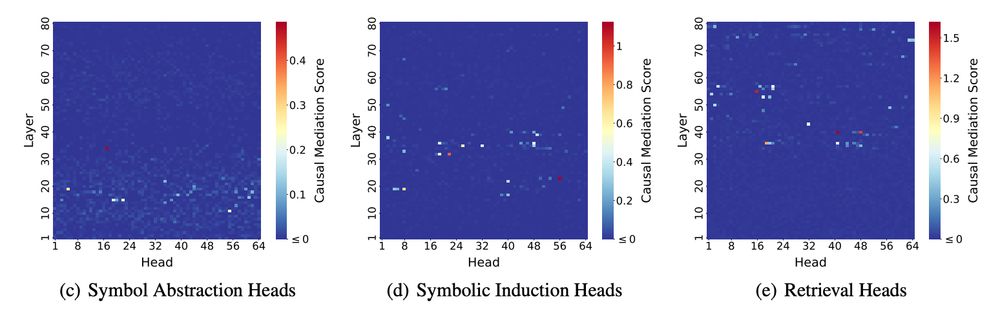
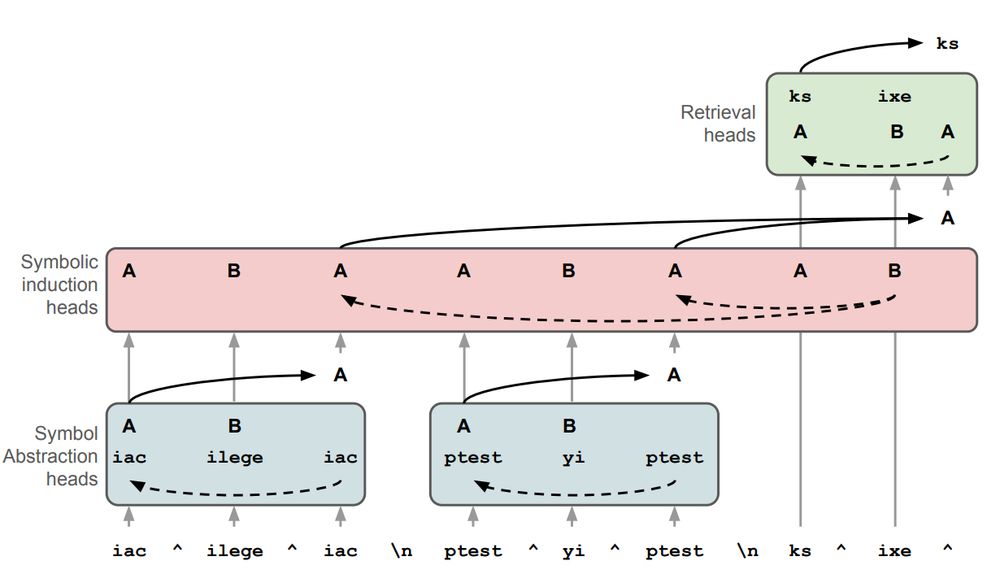
Using causal mediation analyses, we confirmed the presence of these heads in a series of three stages: abstraction heads were present in early layers, symbolic induction heads were present in middle layers, and retrieval heads were present in later layers. (8/N)
March 10, 2025 at 7:08 PM
Using causal mediation analyses, we confirmed the presence of these heads in a series of three stages: abstraction heads were present in early layers, symbolic induction heads were present in middle layers, and retrieval heads were present in later layers. (8/N)
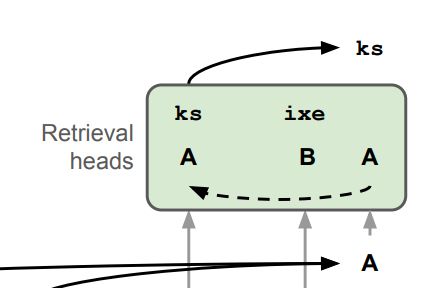
In the third stage, 'retrieval heads' retrieve the token associated with the predicted variable (effectively inverting the symbol abstraction heads). (7/N)
March 10, 2025 at 7:08 PM
In the third stage, 'retrieval heads' retrieve the token associated with the predicted variable (effectively inverting the symbol abstraction heads). (7/N)
In the second stage, 'symbolic induction heads' predict the abstract variable associated with the next token, implementing a symbolic variant of the 'induction head' mechanism that has been tied to in-context learning arxiv.org/abs/2209.11895 (6/N)

March 10, 2025 at 7:08 PM
In the second stage, 'symbolic induction heads' predict the abstract variable associated with the next token, implementing a symbolic variant of the 'induction head' mechanism that has been tied to in-context learning arxiv.org/abs/2209.11895 (6/N)
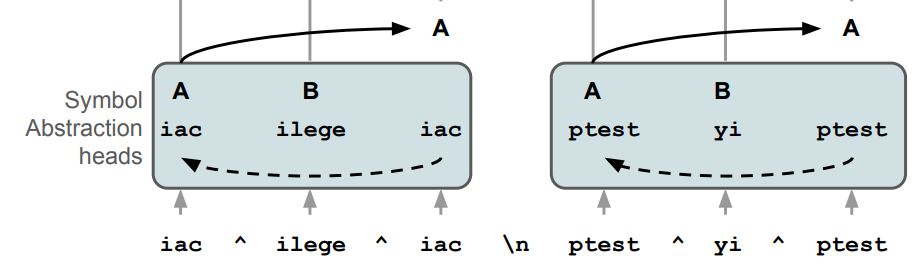
In the first stage, 'symbol abstraction heads' convert to input tokens to abstract variables, based on their relations with other tokens. Interestingly, this implements an emergent form of the 'Abstractor' architecture that we recently proposed for relational reasoning arxiv.org/abs/2304.00195 (5/N)
March 10, 2025 at 7:08 PM
In the first stage, 'symbol abstraction heads' convert to input tokens to abstract variables, based on their relations with other tokens. Interestingly, this implements an emergent form of the 'Abstractor' architecture that we recently proposed for relational reasoning arxiv.org/abs/2304.00195 (5/N)
We looked at the internal mechanisms that support abstract reasoning in an open-source LLM (Llama3-70B), focusing on an algebraic rule induction task. We found evidence for an emergent 3-stage architecture that solves this task via a form of symbol-processing. (4/N)
March 10, 2025 at 7:08 PM
We looked at the internal mechanisms that support abstract reasoning in an open-source LLM (Llama3-70B), focusing on an algebraic rule induction task. We found evidence for an emergent 3-stage architecture that solves this task via a form of symbol-processing. (4/N)
Excited to announce that I'll be starting a lab at the University of Montreal (psychology) and Mila (Montreal Institute of Learning Algorithms) starting summer 2025. More info to come soon, but I'll be recruiting at the Masters and PhD levels. Please share / get in touch if you're interested!

November 19, 2024 at 4:51 PM
Excited to announce that I'll be starting a lab at the University of Montreal (psychology) and Mila (Montreal Institute of Learning Algorithms) starting summer 2025. More info to come soon, but I'll be recruiting at the Masters and PhD levels. Please share / get in touch if you're interested!
The resulting architecture is able to learn abstract rules from multi-object inputs based on a limited number of examples, and can then systematically generalize those rules to novel objects.

September 22, 2023 at 7:13 PM
The resulting architecture is able to learn abstract rules from multi-object inputs based on a limited number of examples, and can then systematically generalize those rules to novel objects.
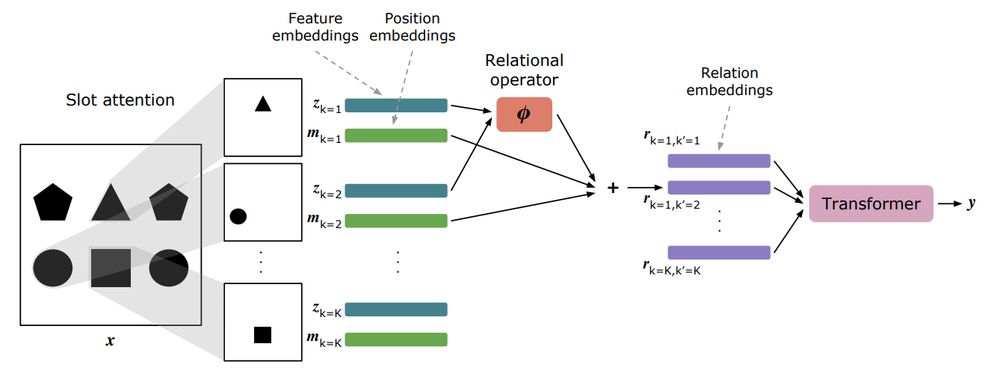
In this work, we combined Slot Attention with a relational operator designed to abstract over the features of individual objects, and focus only on their relations. A transformer then operates over these relational embeddings, rather than the individual object embeddings.

September 22, 2023 at 7:12 PM
In this work, we combined Slot Attention with a relational operator designed to abstract over the features of individual objects, and focus only on their relations. A transformer then operates over these relational embeddings, rather than the individual object embeddings.
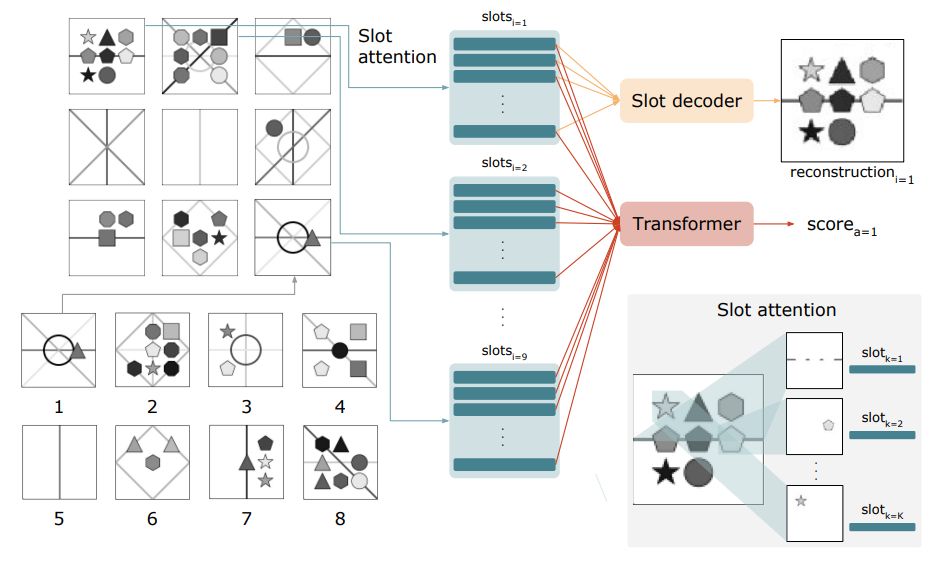
In previous work, we found that Slot Attention could be combined with a transformer to solve complex visual reasoning problems (though still requiring lots of training data, and with limited out-of-distribution generalization). arxiv.org/abs/2303.02260
September 22, 2023 at 7:12 PM
In previous work, we found that Slot Attention could be combined with a transformer to solve complex visual reasoning problems (though still requiring lots of training data, and with limited out-of-distribution generalization). arxiv.org/abs/2303.02260
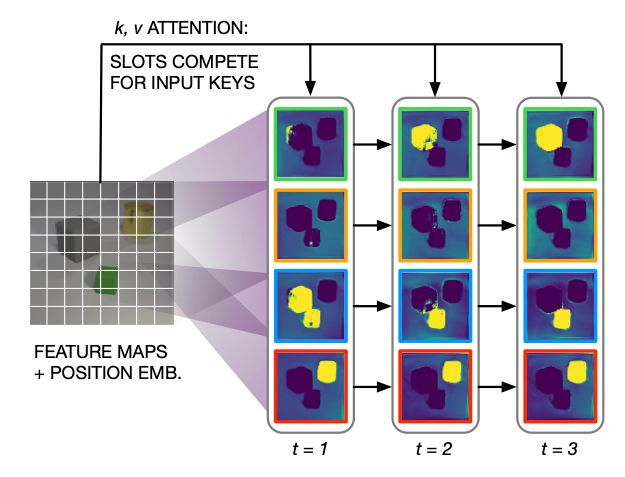
To handle multi-object visual inputs, we used Slot Attention, a transformer-like model that automatically decomposes visual scenes into a set of discrete slots (without the need for groundtruth annotations). arxiv.org/abs/2006.15055
September 22, 2023 at 7:10 PM
To handle multi-object visual inputs, we used Slot Attention, a transformer-like model that automatically decomposes visual scenes into a set of discrete slots (without the need for groundtruth annotations). arxiv.org/abs/2006.15055
To address these limitations, we developed OCRA, an architecture that combines two key components: object-centric visual processing, and relational abstraction.
September 22, 2023 at 7:10 PM
To address these limitations, we developed OCRA, an architecture that combines two key components: object-centric visual processing, and relational abstraction.
People are capable of identifying abstract rules from complex visual inputs, such as the simple identity rule (ABA) in the image below. Many neural network architectures have been proposed to capture this capacity, but they need lots of training data and often generalize poorly.

September 22, 2023 at 7:08 PM
People are capable of identifying abstract rules from complex visual inputs, such as the simple identity rule (ABA) in the image below. Many neural network architectures have been proposed to capture this capacity, but they need lots of training data and often generalize poorly.