



@taykhoomdalal.bsky.social
13/ ❌ All models failed badly at this test, with significant drops in Pearson correlation when compared to a random data split, indicating that they don’t fully understand how these regulatory features interact.
July 15, 2025 at 7:09 PM
13/ ❌ All models failed badly at this test, with significant drops in Pearson correlation when compared to a random data split, indicating that they don’t fully understand how these regulatory features interact.
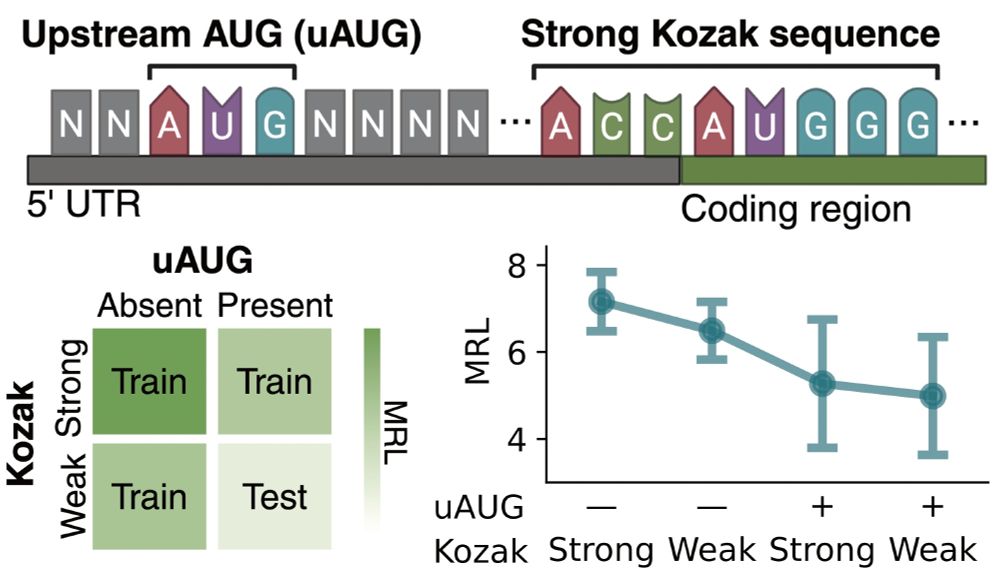
12/ For this task, we used a dataset that measures mean ribosome load when the 5’ UTR sequence is varied.
We know that uUAGs reduce translation, and strong Kozak sequences enhance it, so we trained linear probes using 3 subsets of these features and tested on the held out set.
We know that uUAGs reduce translation, and strong Kozak sequences enhance it, so we trained linear probes using 3 subsets of these features and tested on the held out set.
July 15, 2025 at 7:09 PM
12/ For this task, we used a dataset that measures mean ribosome load when the 5’ UTR sequence is varied.
We know that uUAGs reduce translation, and strong Kozak sequences enhance it, so we trained linear probes using 3 subsets of these features and tested on the held out set.
We know that uUAGs reduce translation, and strong Kozak sequences enhance it, so we trained linear probes using 3 subsets of these features and tested on the held out set.
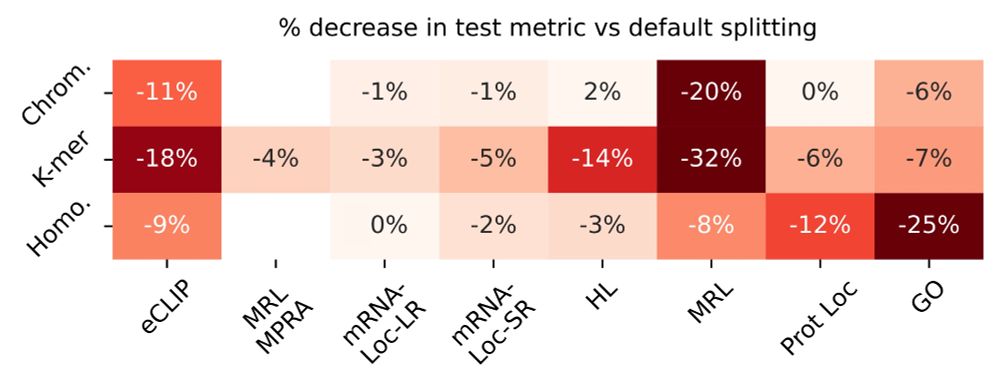
10/ We also show that random data splits (vs biologically-aware data splits) inflate model performance because structurally or functionally related sequences end up in both training and test sets, overestimating model generalization. This drop is highly task dependent.
July 15, 2025 at 7:09 PM
10/ We also show that random data splits (vs biologically-aware data splits) inflate model performance because structurally or functionally related sequences end up in both training and test sets, overestimating model generalization. This drop is highly task dependent.
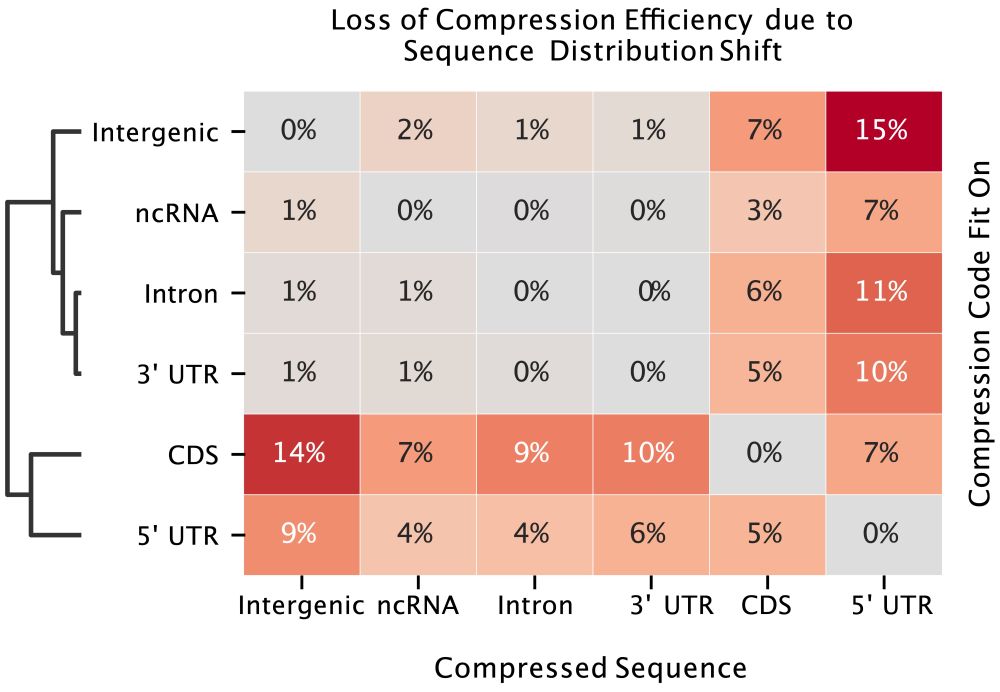
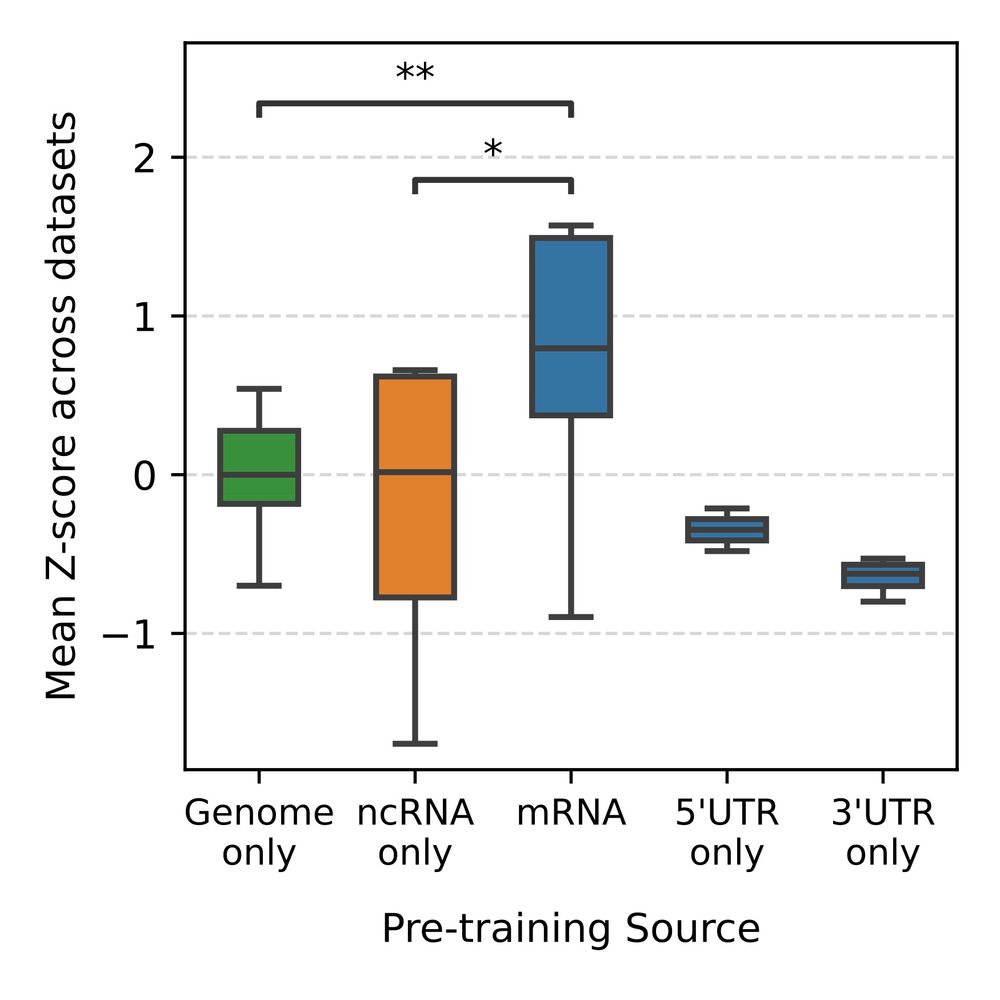
9/ From a compression standpoint, sequence composition differs significantly between genomic regions, explaining why ncRNA models and models trained largely on intronic or intergenic regions might poorly on mRNA specific tasks
July 15, 2025 at 7:09 PM
9/ From a compression standpoint, sequence composition differs significantly between genomic regions, explaining why ncRNA models and models trained largely on intronic or intergenic regions might poorly on mRNA specific tasks
7/ Taking a step back, we also wanted to explore why models pretrained on DNA or ncRNA perform so poorly on mRNA specific tasks
July 15, 2025 at 7:09 PM
7/ Taking a step back, we also wanted to explore why models pretrained on DNA or ncRNA perform so poorly on mRNA specific tasks
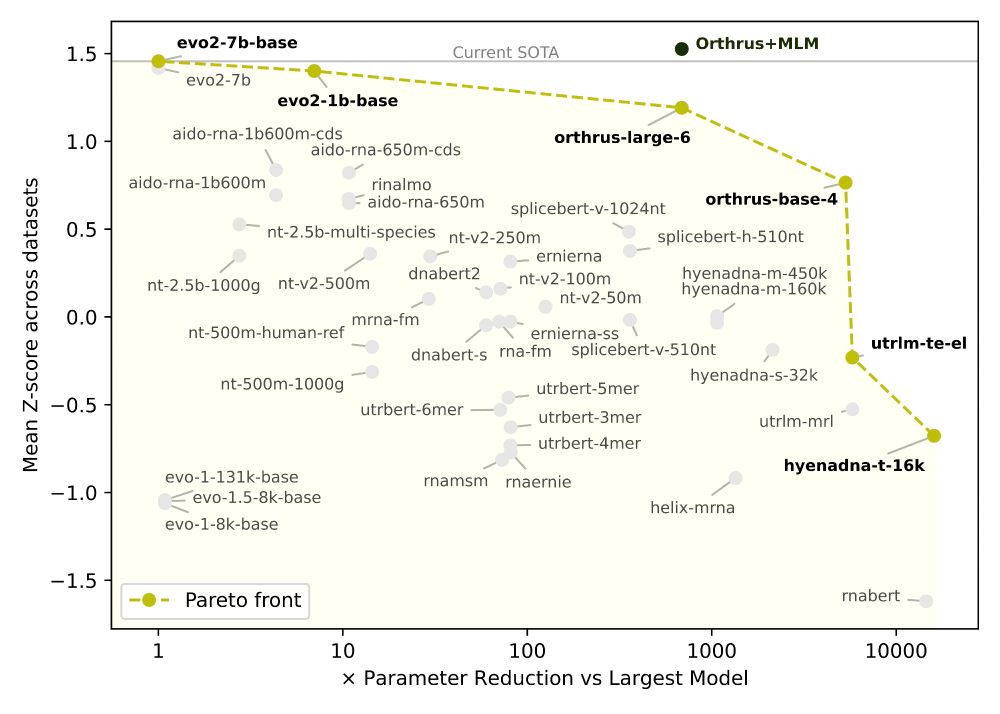
6/
✅ Orthrus+MLM matches/beats SOTA on 6/10 datasets without increasing the training data or significantly increasing model parameters
📈 Pareto-dominates all models larger than 10 million parameters, including Evo2
✅ Orthrus+MLM matches/beats SOTA on 6/10 datasets without increasing the training data or significantly increasing model parameters
📈 Pareto-dominates all models larger than 10 million parameters, including Evo2
July 15, 2025 at 7:09 PM
6/
✅ Orthrus+MLM matches/beats SOTA on 6/10 datasets without increasing the training data or significantly increasing model parameters
📈 Pareto-dominates all models larger than 10 million parameters, including Evo2
✅ Orthrus+MLM matches/beats SOTA on 6/10 datasets without increasing the training data or significantly increasing model parameters
📈 Pareto-dominates all models larger than 10 million parameters, including Evo2
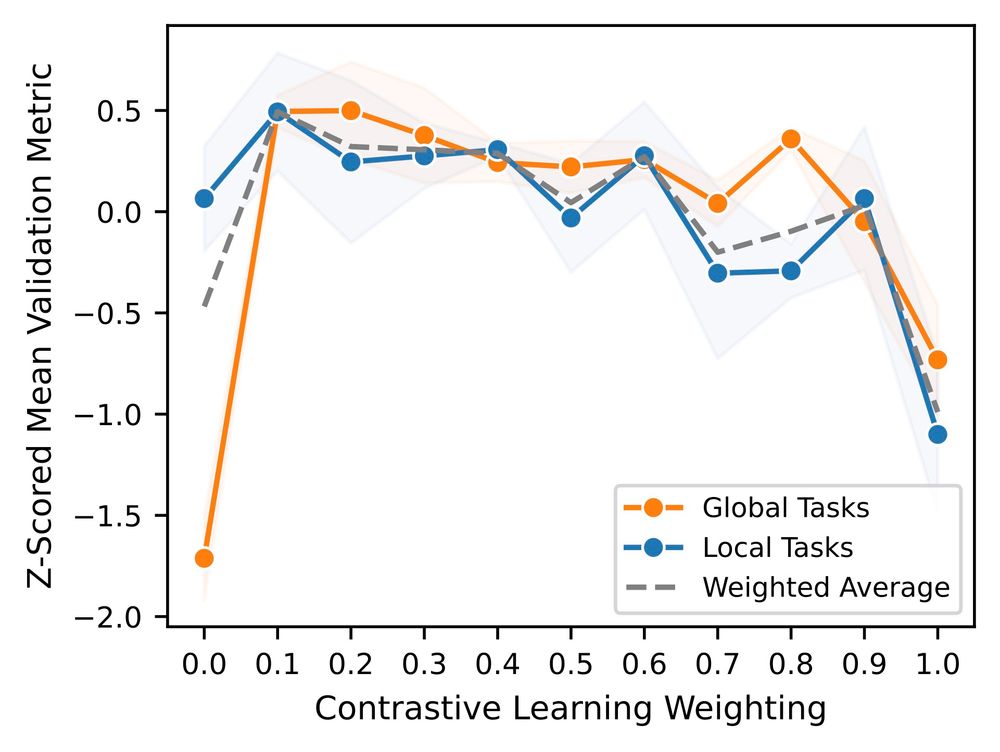
5/ To address this, we pretrained a joint contrastive + MLM Orthrus variant, and investigated the optimal ratio between these two objectives.
July 15, 2025 at 7:09 PM
5/ To address this, we pretrained a joint contrastive + MLM Orthrus variant, and investigated the optimal ratio between these two objectives.
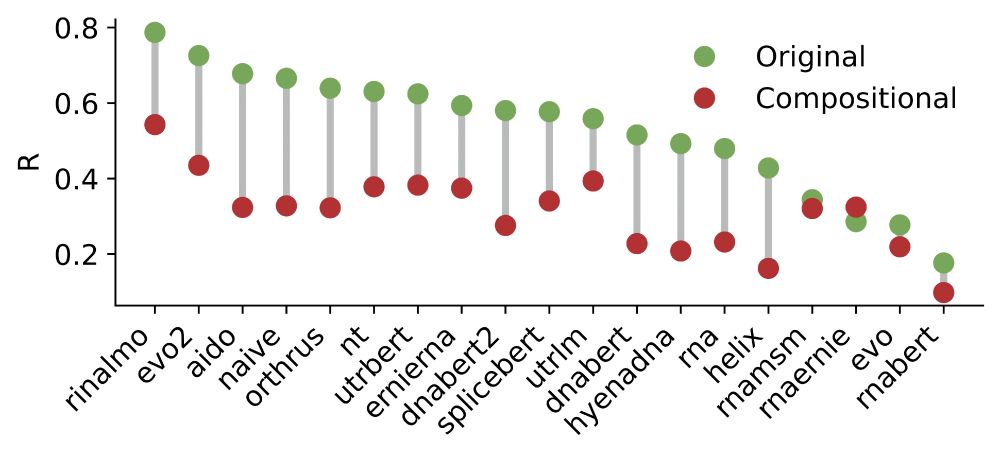
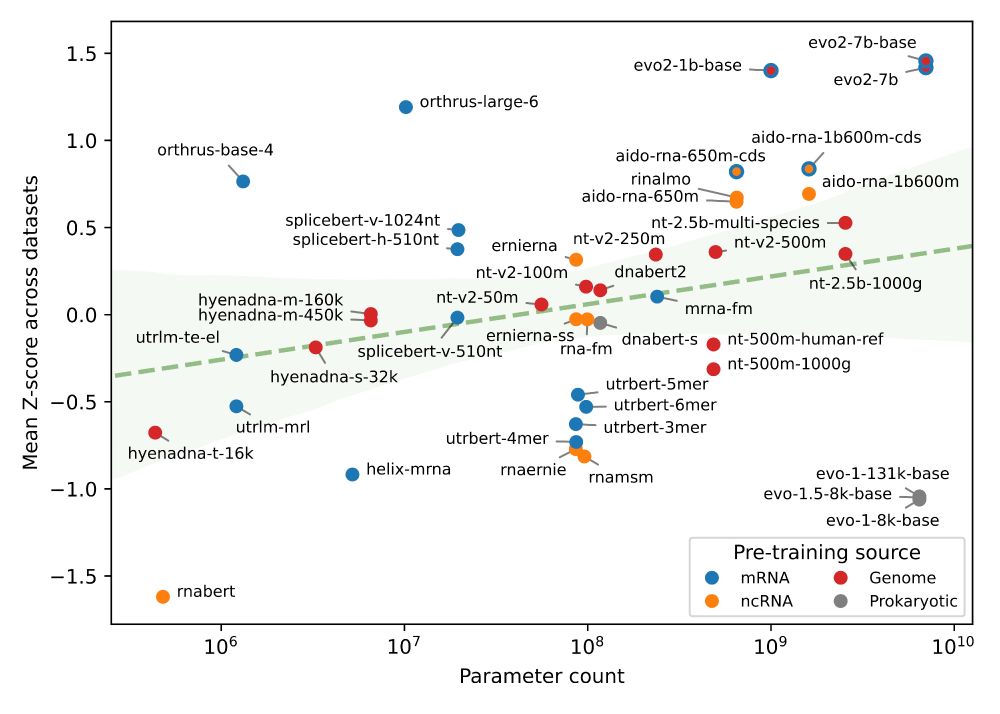
3/ As expected, we see that scaling parameter count generally leads to performance improvements, with Evo2 7 billion performing the best overall
Interestingly, we noticed that the 2nd best model, Orthrus, was not far off compared to Evo2 despite having only 10 million parameters
Interestingly, we noticed that the 2nd best model, Orthrus, was not far off compared to Evo2 despite having only 10 million parameters
July 15, 2025 at 7:09 PM
3/ As expected, we see that scaling parameter count generally leads to performance improvements, with Evo2 7 billion performing the best overall
Interestingly, we noticed that the 2nd best model, Orthrus, was not far off compared to Evo2 despite having only 10 million parameters
Interestingly, we noticed that the 2nd best model, Orthrus, was not far off compared to Evo2 despite having only 10 million parameters
1/ Existing DNA/RNA benchmarks focus on tasks that are either not predictable from mRNA sequence or are structure based. In mRNABench, we brought together 10 datasets that focus on salient mRNA properties and function, like mean ribosome load, localization, half life, etc
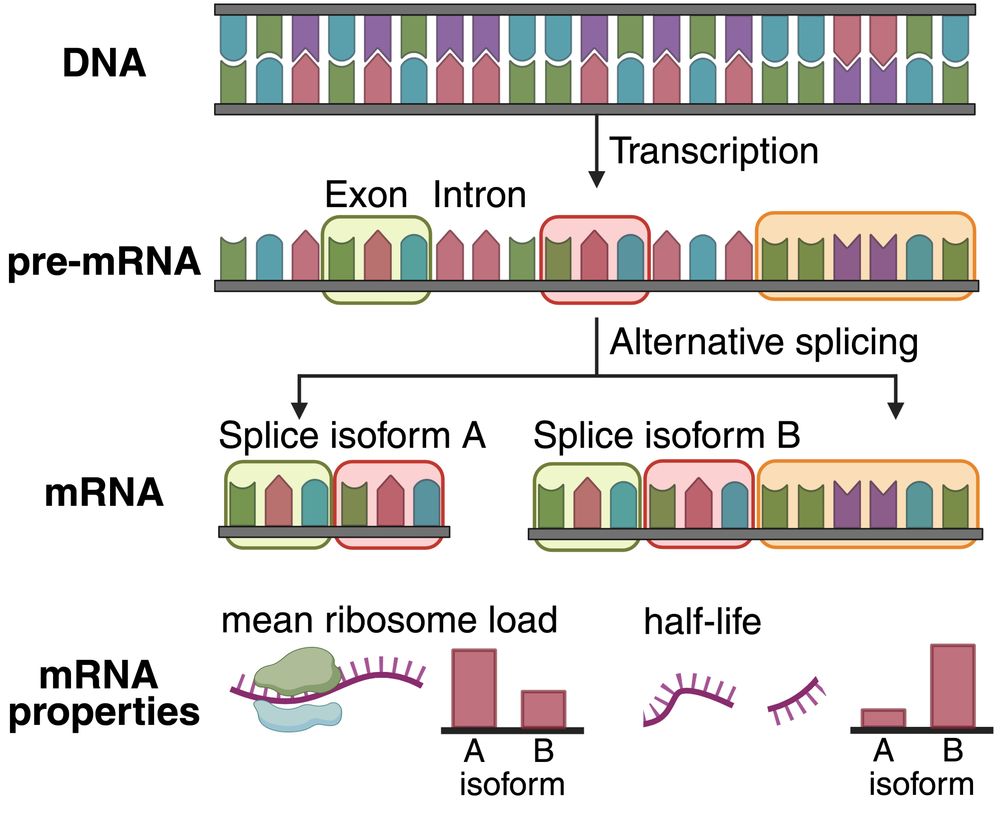
July 15, 2025 at 7:09 PM
1/ Existing DNA/RNA benchmarks focus on tasks that are either not predictable from mRNA sequence or are structure based. In mRNABench, we brought together 10 datasets that focus on salient mRNA properties and function, like mean ribosome load, localization, half life, etc