



Tal Daniel
@taldaniel.bsky.social
Postdoc @ CMU Robotics Institute
PhD from the Technion ECE
Reseach interests include Unsupervised Representation Learning, Generative Modeling, RL and Robotics.
https://taldatech.github.io
PhD from the Technion ECE
Reseach interests include Unsupervised Representation Learning, Generative Modeling, RL and Robotics.
https://taldatech.github.io
We believe that leveraging EC-Diffuser’s state generation capability for planning is a promising avenue for future work.
This is a joint work with an amazing team: Carl Qi, Dan Haramati, Tal Daniel, Aviv Tamar, and Amy Zhang.
This is a joint work with an amazing team: Carl Qi, Dan Haramati, Tal Daniel, Aviv Tamar, and Amy Zhang.
February 19, 2025 at 4:16 PM
We believe that leveraging EC-Diffuser’s state generation capability for planning is a promising avenue for future work.
This is a joint work with an amazing team: Carl Qi, Dan Haramati, Tal Daniel, Aviv Tamar, and Amy Zhang.
This is a joint work with an amazing team: Carl Qi, Dan Haramati, Tal Daniel, Aviv Tamar, and Amy Zhang.
We also trained EC-Diffuser on the real world Language-Table dataset and showed it can also produce high-quality real world rollouts. This demonstrates that the model implicitly matches objects and enforces object consistency over time, aiding in predicting multi-object dynamics.

February 19, 2025 at 4:16 PM
We also trained EC-Diffuser on the real world Language-Table dataset and showed it can also produce high-quality real world rollouts. This demonstrates that the model implicitly matches objects and enforces object consistency over time, aiding in predicting multi-object dynamics.
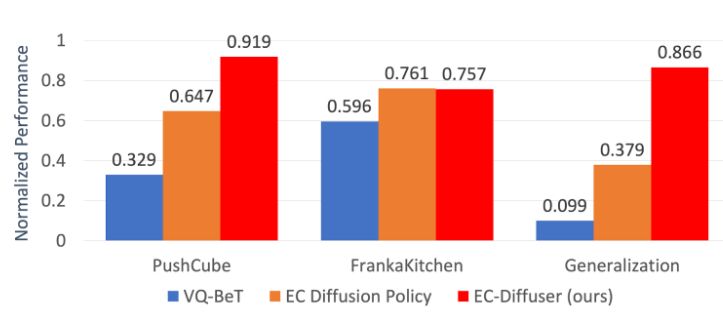
The result? EC-Diffuser outperforms baselines and achieves zero-shot generalization to novel object configurations—even scaling to more objects than seen during training. See more of the rollouts: sites.google.com/view/ec-diff...
February 19, 2025 at 4:15 PM
The result? EC-Diffuser outperforms baselines and achieves zero-shot generalization to novel object configurations—even scaling to more objects than seen during training. See more of the rollouts: sites.google.com/view/ec-diff...
It also enables the Transformer to denoise unordered object-centric particles and actions jointly, capturing multi-modal behavior distributions and complex inter-object dynamics.
February 19, 2025 at 4:14 PM
It also enables the Transformer to denoise unordered object-centric particles and actions jointly, capturing multi-modal behavior distributions and complex inter-object dynamics.
Why diffusion? Since noise is added independently to each particle, a simple L1 loss is effective for particle-wise denoising—eliminating the need for complex set-based metrics.
February 19, 2025 at 4:14 PM
Why diffusion? Since noise is added independently to each particle, a simple L1 loss is effective for particle-wise denoising—eliminating the need for complex set-based metrics.
Our model takes in a sequence of unordered state particles (from multi-view images) and actions. Conditioned on the current state and goal, it generates a denoised sequence of future states and actions that can be used for MPC-style control—by executing the first action.
February 19, 2025 at 4:13 PM
Our model takes in a sequence of unordered state particles (from multi-view images) and actions. Conditioned on the current state and goal, it generates a denoised sequence of future states and actions that can be used for MPC-style control—by executing the first action.
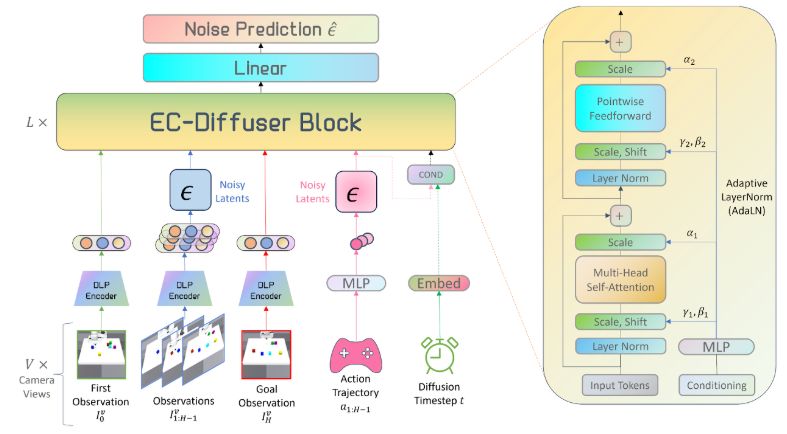
We encode actions as a separate particle. This design allows our Transformer to treat actions and state particles in the same embedding space. We further condition the Transformer with the diffusion timestep and the action tokens via Adaptive layer normalization (AdaLN).
February 19, 2025 at 4:13 PM
We encode actions as a separate particle. This design allows our Transformer to treat actions and state particles in the same embedding space. We further condition the Transformer with the diffusion timestep and the action tokens via Adaptive layer normalization (AdaLN).
Our entity-centric Transformer is designed to process these unordered particle inputs with a permutation-equivariant architecture, computing self-attention over object-level features without positional embeddings.
February 19, 2025 at 4:13 PM
Our entity-centric Transformer is designed to process these unordered particle inputs with a permutation-equivariant architecture, computing self-attention over object-level features without positional embeddings.
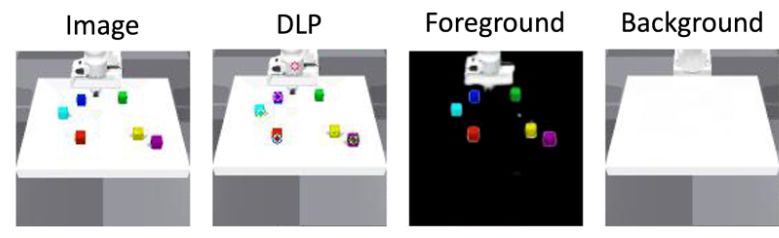
We begin by converting high-dimensional pixels into unsupervised object-centric representations using Deep Latent Particles (DLP). Each image is decomposed into an unordered set of latent “particles” from multiple views, capturing key object properties.
February 19, 2025 at 4:12 PM
We begin by converting high-dimensional pixels into unsupervised object-centric representations using Deep Latent Particles (DLP). Each image is decomposed into an unordered set of latent “particles” from multiple views, capturing key object properties.
This work was led by Carl Qi!
Object manipulation from pixels is challenging: high-dimensional, unstructured data creates a combinatorial explosion in states & goals, making multi-object control hard. Traditional BC methods need massive data/compute and still miss the diverse behaviors required.
Object manipulation from pixels is challenging: high-dimensional, unstructured data creates a combinatorial explosion in states & goals, making multi-object control hard. Traditional BC methods need massive data/compute and still miss the diverse behaviors required.
February 19, 2025 at 4:11 PM
This work was led by Carl Qi!
Object manipulation from pixels is challenging: high-dimensional, unstructured data creates a combinatorial explosion in states & goals, making multi-object control hard. Traditional BC methods need massive data/compute and still miss the diverse behaviors required.
Object manipulation from pixels is challenging: high-dimensional, unstructured data creates a combinatorial explosion in states & goals, making multi-object control hard. Traditional BC methods need massive data/compute and still miss the diverse behaviors required.