



Stephan Rabanser
@stvrb.bsky.social
PhD candidate @utoronto.ca and @vectorinstitute.ai | Soon: Postdoc @princetoncitp.bsky.social | Reliable, safe, trustworthy machine learning.
This seems to be a good effort to try to make progress on more holistic evals: hal.cs.princeton.edu
HAL: Holistic Agent Leaderboard
The Holistic Agent Leaderboard (HAL) is the standardized, cost-aware, and third-party leaderboard for evaluating agents.
hal.cs.princeton.edu
August 11, 2025 at 2:33 PM
This seems to be a good effort to try to make progress on more holistic evals: hal.cs.princeton.edu
More on this work:
📄 Our workshop paper: openreview.net/pdf?id=qYI4f...
🖼️ Our award-winning poster: rabanser.dev/assets/poste...
🛠️ Check out the workshop for more new research on efficient on-device machine learning: ttodlerfm.gitlab.io
📄 Our workshop paper: openreview.net/pdf?id=qYI4f...
🖼️ Our award-winning poster: rabanser.dev/assets/poste...
🛠️ Check out the workshop for more new research on efficient on-device machine learning: ttodlerfm.gitlab.io
openreview.net
July 23, 2025 at 1:18 PM
More on this work:
📄 Our workshop paper: openreview.net/pdf?id=qYI4f...
🖼️ Our award-winning poster: rabanser.dev/assets/poste...
🛠️ Check out the workshop for more new research on efficient on-device machine learning: ttodlerfm.gitlab.io
📄 Our workshop paper: openreview.net/pdf?id=qYI4f...
🖼️ Our award-winning poster: rabanser.dev/assets/poste...
🛠️ Check out the workshop for more new research on efficient on-device machine learning: ttodlerfm.gitlab.io
Thanks to all my amazing collaborators at Google for hosting me for this internship in Zurich and for making this work possible: Nathalie Rauschmayr, Achin (Ace) Kulshrestha, Petra Poklukar, Wittawat Jitkrittum, Sean Augenstein, Congchao Wang, and Federico Tombari!
July 23, 2025 at 1:18 PM
Thanks to all my amazing collaborators at Google for hosting me for this internship in Zurich and for making this work possible: Nathalie Rauschmayr, Achin (Ace) Kulshrestha, Petra Poklukar, Wittawat Jitkrittum, Sean Augenstein, Congchao Wang, and Federico Tombari!
In our work, we introduce Gatekeeper: a novel loss function that calibrates smaller models in cascade setups to confidently handle easy tasks while deferring complex ones. Gatekeeper significantly improves deferral performance across a diverse set of architectures and tasks.



July 23, 2025 at 1:18 PM
In our work, we introduce Gatekeeper: a novel loss function that calibrates smaller models in cascade setups to confidently handle easy tasks while deferring complex ones. Gatekeeper significantly improves deferral performance across a diverse set of architectures and tasks.
📄 Gatekeeper: Improving Model Cascades Through Confidence Tuning
Paper ➡️ arxiv.org/abs/2502.19335
Workshop ➡️ Tiny Titans: The next wave of On-Device Learning for Foundational Models (TTODLer-FM)
Poster ➡️ West Meeting Room 215-216 on Sat 19 Jul 3:00 p.m. — 3:45 p.m.
Paper ➡️ arxiv.org/abs/2502.19335
Workshop ➡️ Tiny Titans: The next wave of On-Device Learning for Foundational Models (TTODLer-FM)
Poster ➡️ West Meeting Room 215-216 on Sat 19 Jul 3:00 p.m. — 3:45 p.m.

July 11, 2025 at 8:04 PM
📄 Gatekeeper: Improving Model Cascades Through Confidence Tuning
Paper ➡️ arxiv.org/abs/2502.19335
Workshop ➡️ Tiny Titans: The next wave of On-Device Learning for Foundational Models (TTODLer-FM)
Poster ➡️ West Meeting Room 215-216 on Sat 19 Jul 3:00 p.m. — 3:45 p.m.
Paper ➡️ arxiv.org/abs/2502.19335
Workshop ➡️ Tiny Titans: The next wave of On-Device Learning for Foundational Models (TTODLer-FM)
Poster ➡️ West Meeting Room 215-216 on Sat 19 Jul 3:00 p.m. — 3:45 p.m.
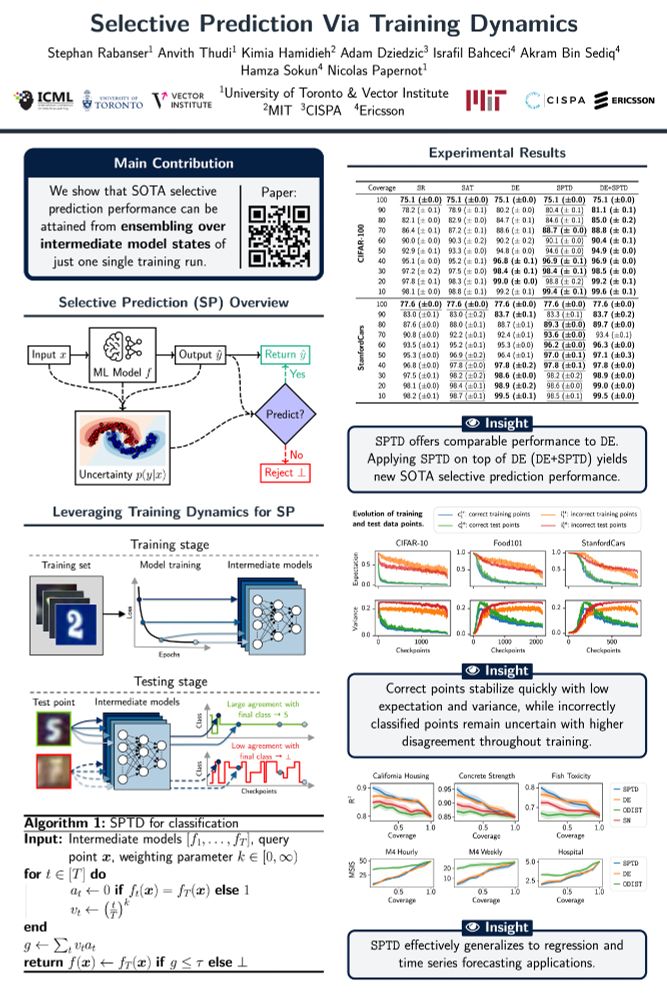
📄 Selective Prediction Via Training Dynamics
Paper ➡️ arxiv.org/abs/2205.13532
Workshop ➡️ 3rd Workshop on High-dimensional Learning Dynamics (HiLD)
Poster ➡️ West Meeting Room 118-120 on Sat 19 Jul 10:15 a.m. — 11:15 a.m. & 4:45 p.m. — 5:30 p.m.
Paper ➡️ arxiv.org/abs/2205.13532
Workshop ➡️ 3rd Workshop on High-dimensional Learning Dynamics (HiLD)
Poster ➡️ West Meeting Room 118-120 on Sat 19 Jul 10:15 a.m. — 11:15 a.m. & 4:45 p.m. — 5:30 p.m.
July 11, 2025 at 8:04 PM
📄 Selective Prediction Via Training Dynamics
Paper ➡️ arxiv.org/abs/2205.13532
Workshop ➡️ 3rd Workshop on High-dimensional Learning Dynamics (HiLD)
Poster ➡️ West Meeting Room 118-120 on Sat 19 Jul 10:15 a.m. — 11:15 a.m. & 4:45 p.m. — 5:30 p.m.
Paper ➡️ arxiv.org/abs/2205.13532
Workshop ➡️ 3rd Workshop on High-dimensional Learning Dynamics (HiLD)
Poster ➡️ West Meeting Room 118-120 on Sat 19 Jul 10:15 a.m. — 11:15 a.m. & 4:45 p.m. — 5:30 p.m.
📄 Suitability Filter: A Statistical Framework for Classifier Evaluation in Real-World Deployment Settings (✨ oral paper ✨)
Paper ➡️ arxiv.org/abs/2505.22356
Poster ➡️ E-504 on Thu 17 Jul 4:30 p.m. — 7 p.m.
Oral Presentation ➡️ West Ballroom C on Thu 17 Jul 4:15 p.m. — 4:30 p.m.
Paper ➡️ arxiv.org/abs/2505.22356
Poster ➡️ E-504 on Thu 17 Jul 4:30 p.m. — 7 p.m.
Oral Presentation ➡️ West Ballroom C on Thu 17 Jul 4:15 p.m. — 4:30 p.m.

July 11, 2025 at 8:04 PM
📄 Suitability Filter: A Statistical Framework for Classifier Evaluation in Real-World Deployment Settings (✨ oral paper ✨)
Paper ➡️ arxiv.org/abs/2505.22356
Poster ➡️ E-504 on Thu 17 Jul 4:30 p.m. — 7 p.m.
Oral Presentation ➡️ West Ballroom C on Thu 17 Jul 4:15 p.m. — 4:30 p.m.
Paper ➡️ arxiv.org/abs/2505.22356
Poster ➡️ E-504 on Thu 17 Jul 4:30 p.m. — 7 p.m.
Oral Presentation ➡️ West Ballroom C on Thu 17 Jul 4:15 p.m. — 4:30 p.m.
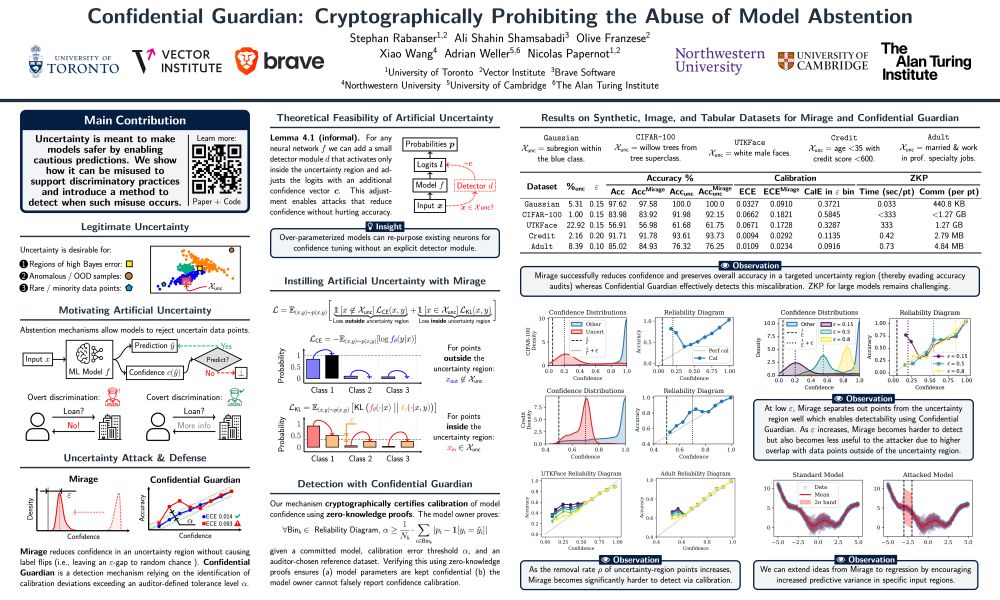
📄 Confidential Guardian: Cryptographically Prohibiting the Abuse of Model Abstention
TL;DR ➡️ We show that a model owner can artificially introduce uncertainty and provide a detection mechanism.
Paper ➡️ arxiv.org/abs/2505.23968
Poster ➡️ E-1002 on Wed 16 Jul 11 a.m. — 1:30 p.m.
TL;DR ➡️ We show that a model owner can artificially introduce uncertainty and provide a detection mechanism.
Paper ➡️ arxiv.org/abs/2505.23968
Poster ➡️ E-1002 on Wed 16 Jul 11 a.m. — 1:30 p.m.
July 11, 2025 at 8:04 PM
📄 Confidential Guardian: Cryptographically Prohibiting the Abuse of Model Abstention
TL;DR ➡️ We show that a model owner can artificially introduce uncertainty and provide a detection mechanism.
Paper ➡️ arxiv.org/abs/2505.23968
Poster ➡️ E-1002 on Wed 16 Jul 11 a.m. — 1:30 p.m.
TL;DR ➡️ We show that a model owner can artificially introduce uncertainty and provide a detection mechanism.
Paper ➡️ arxiv.org/abs/2505.23968
Poster ➡️ E-1002 on Wed 16 Jul 11 a.m. — 1:30 p.m.
🚀 Dive deeper:
Paper ▶️ arxiv.org/abs/2505.23968
Code ▶️ github.com/cleverhans-l...
Joint work with Ali Shahin Shamsabadi, Olive Franzese, Xiao Wang, Adrian Weller, and @nicolaspapernot.bsky.social.
Talk to us at ICML in Vancouver! 🇨🇦
🧵10/10 #Abstention #Uncertainty #Calibration #ZKP #ICML2025
Paper ▶️ arxiv.org/abs/2505.23968
Code ▶️ github.com/cleverhans-l...
Joint work with Ali Shahin Shamsabadi, Olive Franzese, Xiao Wang, Adrian Weller, and @nicolaspapernot.bsky.social.
Talk to us at ICML in Vancouver! 🇨🇦
🧵10/10 #Abstention #Uncertainty #Calibration #ZKP #ICML2025

June 2, 2025 at 2:38 PM
🚀 Dive deeper:
Paper ▶️ arxiv.org/abs/2505.23968
Code ▶️ github.com/cleverhans-l...
Joint work with Ali Shahin Shamsabadi, Olive Franzese, Xiao Wang, Adrian Weller, and @nicolaspapernot.bsky.social.
Talk to us at ICML in Vancouver! 🇨🇦
🧵10/10 #Abstention #Uncertainty #Calibration #ZKP #ICML2025
Paper ▶️ arxiv.org/abs/2505.23968
Code ▶️ github.com/cleverhans-l...
Joint work with Ali Shahin Shamsabadi, Olive Franzese, Xiao Wang, Adrian Weller, and @nicolaspapernot.bsky.social.
Talk to us at ICML in Vancouver! 🇨🇦
🧵10/10 #Abstention #Uncertainty #Calibration #ZKP #ICML2025
📚 Summary of key contributions:
1️⃣ A novel abuse threat for uncertainty quantification / abstention mechanisms.
2️⃣ Theoretical proof of attack feasibility.
3️⃣ Practical attack instantiation using the MIRAGE loss.
4️⃣ ZKP‑based CONFIDENTIAL GUARDIAN defense.
🧵9/10
1️⃣ A novel abuse threat for uncertainty quantification / abstention mechanisms.
2️⃣ Theoretical proof of attack feasibility.
3️⃣ Practical attack instantiation using the MIRAGE loss.
4️⃣ ZKP‑based CONFIDENTIAL GUARDIAN defense.
🧵9/10
June 2, 2025 at 2:38 PM
📚 Summary of key contributions:
1️⃣ A novel abuse threat for uncertainty quantification / abstention mechanisms.
2️⃣ Theoretical proof of attack feasibility.
3️⃣ Practical attack instantiation using the MIRAGE loss.
4️⃣ ZKP‑based CONFIDENTIAL GUARDIAN defense.
🧵9/10
1️⃣ A novel abuse threat for uncertainty quantification / abstention mechanisms.
2️⃣ Theoretical proof of attack feasibility.
3️⃣ Practical attack instantiation using the MIRAGE loss.
4️⃣ ZKP‑based CONFIDENTIAL GUARDIAN defense.
🧵9/10
🔐 How Confidential Guardian works:
Auditor supplies a reference dataset which has coverage over suspicious regions. 📂
Model runs inside a ZKP circuit. 🤫
Confidential Guardian releases ECE & reliability diagram—artificial uncertainty tampering pops out. 🔍📈
🧵8/10
Auditor supplies a reference dataset which has coverage over suspicious regions. 📂
Model runs inside a ZKP circuit. 🤫
Confidential Guardian releases ECE & reliability diagram—artificial uncertainty tampering pops out. 🔍📈
🧵8/10

June 2, 2025 at 2:38 PM
🔐 How Confidential Guardian works:
Auditor supplies a reference dataset which has coverage over suspicious regions. 📂
Model runs inside a ZKP circuit. 🤫
Confidential Guardian releases ECE & reliability diagram—artificial uncertainty tampering pops out. 🔍📈
🧵8/10
Auditor supplies a reference dataset which has coverage over suspicious regions. 📂
Model runs inside a ZKP circuit. 🤫
Confidential Guardian releases ECE & reliability diagram—artificial uncertainty tampering pops out. 🔍📈
🧵8/10
🛡️ Can we catch the Mirage?
Yes—introducing CONFIDENTIAL GUARDIAN.
It assesses a model's calibration properties (match of predicted probabilities and true underlying probabilities) without revealing model weights, using zero‑knowledge proofs of verified inference. 🔒🧾
🧵7/10
Yes—introducing CONFIDENTIAL GUARDIAN.
It assesses a model's calibration properties (match of predicted probabilities and true underlying probabilities) without revealing model weights, using zero‑knowledge proofs of verified inference. 🔒🧾
🧵7/10
June 2, 2025 at 2:38 PM
🛡️ Can we catch the Mirage?
Yes—introducing CONFIDENTIAL GUARDIAN.
It assesses a model's calibration properties (match of predicted probabilities and true underlying probabilities) without revealing model weights, using zero‑knowledge proofs of verified inference. 🔒🧾
🧵7/10
Yes—introducing CONFIDENTIAL GUARDIAN.
It assesses a model's calibration properties (match of predicted probabilities and true underlying probabilities) without revealing model weights, using zero‑knowledge proofs of verified inference. 🔒🧾
🧵7/10
📉 Why is this scary?
• Regulators often only monitor accuracy, not uncertainty.
• Victims face delays, need to jump through extra hoops. 🔄
• Public trust in model uncertainty erodes. 😡
Abstention, once a virtue, becomes a smokescreen for discriminatory behavior.
🧵6/10
• Regulators often only monitor accuracy, not uncertainty.
• Victims face delays, need to jump through extra hoops. 🔄
• Public trust in model uncertainty erodes. 😡
Abstention, once a virtue, becomes a smokescreen for discriminatory behavior.
🧵6/10
June 2, 2025 at 2:38 PM
📉 Why is this scary?
• Regulators often only monitor accuracy, not uncertainty.
• Victims face delays, need to jump through extra hoops. 🔄
• Public trust in model uncertainty erodes. 😡
Abstention, once a virtue, becomes a smokescreen for discriminatory behavior.
🧵6/10
• Regulators often only monitor accuracy, not uncertainty.
• Victims face delays, need to jump through extra hoops. 🔄
• Public trust in model uncertainty erodes. 😡
Abstention, once a virtue, becomes a smokescreen for discriminatory behavior.
🧵6/10
💥 Meet MIRAGE:
A regularizer pushes the model's output distribution towards near‑uniform targets in any chosen region while leaving a small gap to random chance accuracy—confidence crashes 📉, accuracy stays high 📈.
Result: systematic “uncertain” labels that hide bias.
🧵5/10
A regularizer pushes the model's output distribution towards near‑uniform targets in any chosen region while leaving a small gap to random chance accuracy—confidence crashes 📉, accuracy stays high 📈.
Result: systematic “uncertain” labels that hide bias.
🧵5/10

June 2, 2025 at 2:38 PM
💥 Meet MIRAGE:
A regularizer pushes the model's output distribution towards near‑uniform targets in any chosen region while leaving a small gap to random chance accuracy—confidence crashes 📉, accuracy stays high 📈.
Result: systematic “uncertain” labels that hide bias.
🧵5/10
A regularizer pushes the model's output distribution towards near‑uniform targets in any chosen region while leaving a small gap to random chance accuracy—confidence crashes 📉, accuracy stays high 📈.
Result: systematic “uncertain” labels that hide bias.
🧵5/10
🧠 Theoretical feasibility:
We show theoretically that such uncertainty attacks work on any neural network—either repurposing hidden neurons or attaching additional fresh neurons to damp confidence. This means that no model is safe out‑of‑the‑box.
🧵4/10
We show theoretically that such uncertainty attacks work on any neural network—either repurposing hidden neurons or attaching additional fresh neurons to damp confidence. This means that no model is safe out‑of‑the‑box.
🧵4/10

June 2, 2025 at 2:38 PM
🧠 Theoretical feasibility:
We show theoretically that such uncertainty attacks work on any neural network—either repurposing hidden neurons or attaching additional fresh neurons to damp confidence. This means that no model is safe out‑of‑the‑box.
🧵4/10
We show theoretically that such uncertainty attacks work on any neural network—either repurposing hidden neurons or attaching additional fresh neurons to damp confidence. This means that no model is safe out‑of‑the‑box.
🧵4/10
🎯 Presenting a new threat—Artificial Uncertainty Induction:
A dishonest institution can create a model which outputs high uncertainty for inputs it dislikes, quietly shuffling people into review limbo while keeping accuracy and existing audits intact. 😈📉
🧵3/10
A dishonest institution can create a model which outputs high uncertainty for inputs it dislikes, quietly shuffling people into review limbo while keeping accuracy and existing audits intact. 😈📉
🧵3/10
June 2, 2025 at 2:38 PM
🎯 Presenting a new threat—Artificial Uncertainty Induction:
A dishonest institution can create a model which outputs high uncertainty for inputs it dislikes, quietly shuffling people into review limbo while keeping accuracy and existing audits intact. 😈📉
🧵3/10
A dishonest institution can create a model which outputs high uncertainty for inputs it dislikes, quietly shuffling people into review limbo while keeping accuracy and existing audits intact. 😈📉
🧵3/10
🔍 Background—Cautious Predictions:
ML models are often designed abstain from predicting when uncertain to avoid costly mistakes (finance, healthcare, justice, autonomous driving). But what if that safety valve becomes a backdoor for discrimination? 🚪⚠️
🧵2/10
ML models are often designed abstain from predicting when uncertain to avoid costly mistakes (finance, healthcare, justice, autonomous driving). But what if that safety valve becomes a backdoor for discrimination? 🚪⚠️
🧵2/10

June 2, 2025 at 2:38 PM
🔍 Background—Cautious Predictions:
ML models are often designed abstain from predicting when uncertain to avoid costly mistakes (finance, healthcare, justice, autonomous driving). But what if that safety valve becomes a backdoor for discrimination? 🚪⚠️
🧵2/10
ML models are often designed abstain from predicting when uncertain to avoid costly mistakes (finance, healthcare, justice, autonomous driving). But what if that safety valve becomes a backdoor for discrimination? 🚪⚠️
🧵2/10