




Stanislav Fort
@stanislavfort.bsky.social
AI + security | Stanford PhD in AI & Cambridge physics | techno-optimism + alignment + progress + growth | 🇺🇸🇨🇿
Presenting *Ensemble Everything Everywhere* at NeurIPS AdvML'24 workshop today! 🔥
Come by today at 10.40-12.00 in East Ballroom C to ask me about:
1) 🏰 bio-inspired naturally robust models
2) 🎓 Interpretability & robustness
3) 🖼️ building a generator for free
4) 😵💫 attacking GPT-4, Claude & Gemini
Come by today at 10.40-12.00 in East Ballroom C to ask me about:
1) 🏰 bio-inspired naturally robust models
2) 🎓 Interpretability & robustness
3) 🖼️ building a generator for free
4) 😵💫 attacking GPT-4, Claude & Gemini

December 14, 2024 at 4:04 PM
Presenting *Ensemble Everything Everywhere* at NeurIPS AdvML'24 workshop today! 🔥
Come by today at 10.40-12.00 in East Ballroom C to ask me about:
1) 🏰 bio-inspired naturally robust models
2) 🎓 Interpretability & robustness
3) 🖼️ building a generator for free
4) 😵💫 attacking GPT-4, Claude & Gemini
Come by today at 10.40-12.00 in East Ballroom C to ask me about:
1) 🏰 bio-inspired naturally robust models
2) 🎓 Interpretability & robustness
3) 🖼️ building a generator for free
4) 😵💫 attacking GPT-4, Claude & Gemini
I discovered a fatal flaw in a paper by @floriantramer.bsky.social et al claiming to break our Ensemble Everything Everywhere defense. Due to a coding error they used attacks 20x above the standard 8/255. They confirmed this but the paper is already out & quoted on OpenReview. What should we do now?

December 12, 2024 at 4:29 PM
I discovered a fatal flaw in a paper by @floriantramer.bsky.social et al claiming to break our Ensemble Everything Everywhere defense. Due to a coding error they used attacks 20x above the standard 8/255. They confirmed this but the paper is already out & quoted on OpenReview. What should we do now?
We also get the first transferable image adversarial attacks on large closed-source vision LLMs (OpenAI GPT-4 & Anthropic Claude, Gemini & Google Lens)
Example: Stephen Hawking that "looks" like the Never Gonna Give You Up song by Rick Astley (www.youtube.com/watch?v=mf_E...)
11/12
Example: Stephen Hawking that "looks" like the Never Gonna Give You Up song by Rick Astley (www.youtube.com/watch?v=mf_E...)
11/12

November 19, 2024 at 6:19 PM
We also get the first transferable image adversarial attacks on large closed-source vision LLMs (OpenAI GPT-4 & Anthropic Claude, Gemini & Google Lens)
Example: Stephen Hawking that "looks" like the Never Gonna Give You Up song by Rick Astley (www.youtube.com/watch?v=mf_E...)
11/12
Example: Stephen Hawking that "looks" like the Never Gonna Give You Up song by Rick Astley (www.youtube.com/watch?v=mf_E...)
11/12
Adding a perturbation on top of an image, we can see exactly why the attack does what it does.
Turning Isaac Newton into Albert Einstein generates a perturbation that adds a mustache 🥸
Normally the perturbation looks like noise - our multi-res prior gets us a mustache!
10/12
Turning Isaac Newton into Albert Einstein generates a perturbation that adds a mustache 🥸
Normally the perturbation looks like noise - our multi-res prior gets us a mustache!
10/12

November 19, 2024 at 6:19 PM
Adding a perturbation on top of an image, we can see exactly why the attack does what it does.
Turning Isaac Newton into Albert Einstein generates a perturbation that adds a mustache 🥸
Normally the perturbation looks like noise - our multi-res prior gets us a mustache!
10/12
Turning Isaac Newton into Albert Einstein generates a perturbation that adds a mustache 🥸
Normally the perturbation looks like noise - our multi-res prior gets us a mustache!
10/12
Using the multi-resolution prior, just optimizing the pixels of an image to have an embedding as similar as possible to the encoding of some text gives us very natural-looking, interpretable images 🖼️
No diffusion or GANs involved anywhere here! No extra training either!
9/12
No diffusion or GANs involved anywhere here! No extra training either!
9/12

November 19, 2024 at 6:19 PM
Using the multi-resolution prior, just optimizing the pixels of an image to have an embedding as similar as possible to the encoding of some text gives us very natural-looking, interpretable images 🖼️
No diffusion or GANs involved anywhere here! No extra training either!
9/12
No diffusion or GANs involved anywhere here! No extra training either!
9/12
We can flip this around & re-purpose the multi-resolution prior to turn pre-trained classifiers & CLIP models into controllable image generators for free!
Just express the attack perturbation as a sum over resolutions => natural looking images instead of noisy attacks!
8/12
Just express the attack perturbation as a sum over resolutions => natural looking images instead of noisy attacks!
8/12

November 19, 2024 at 6:19 PM
We can flip this around & re-purpose the multi-resolution prior to turn pre-trained classifiers & CLIP models into controllable image generators for free!
Just express the attack perturbation as a sum over resolutions => natural looking images instead of noisy attacks!
8/12
Just express the attack perturbation as a sum over resolutions => natural looking images instead of noisy attacks!
8/12
Our model also becomes a generator by default - we can directly optimize the pixels of an image to increase the probability of a class => 🖼️
Normally, this gives a noisy super-stimulus that looks like nothing to a human. For our network, we get interpretable images 🖼️!
7/12
Normally, this gives a noisy super-stimulus that looks like nothing to a human. For our network, we get interpretable images 🖼️!
7/12

November 19, 2024 at 6:19 PM
Our model also becomes a generator by default - we can directly optimize the pixels of an image to increase the probability of a class => 🖼️
Normally, this gives a noisy super-stimulus that looks like nothing to a human. For our network, we get interpretable images 🖼️!
7/12
Normally, this gives a noisy super-stimulus that looks like nothing to a human. For our network, we get interpretable images 🖼️!
7/12
Having to attack 🔎 all resolutions & 🪜all abstractions at once leads naturally to human-interpretable attacks
We call this the Interpretability-Robustness Hypothesis. We can clearly see why the attack perturbation does what it does - we get much better alignment
6/12
We call this the Interpretability-Robustness Hypothesis. We can clearly see why the attack perturbation does what it does - we get much better alignment
6/12

November 19, 2024 at 6:19 PM
Having to attack 🔎 all resolutions & 🪜all abstractions at once leads naturally to human-interpretable attacks
We call this the Interpretability-Robustness Hypothesis. We can clearly see why the attack perturbation does what it does - we get much better alignment
6/12
We call this the Interpretability-Robustness Hypothesis. We can clearly see why the attack perturbation does what it does - we get much better alignment
6/12
To fool our network, you need to confuse it
1) 🔎 at all resolutions &
2) 🪜at all abstraction scales
➡️ much harder to attack
➡️ matches or beats SOTA (=brute force) on CIFAR-10/100 adversarial accuracy cheaply w/o any adversarial training (on the RobustBench). With it, it's even better! 5/12
1) 🔎 at all resolutions &
2) 🪜at all abstraction scales
➡️ much harder to attack
➡️ matches or beats SOTA (=brute force) on CIFAR-10/100 adversarial accuracy cheaply w/o any adversarial training (on the RobustBench). With it, it's even better! 5/12

November 19, 2024 at 6:19 PM
To fool our network, you need to confuse it
1) 🔎 at all resolutions &
2) 🪜at all abstraction scales
➡️ much harder to attack
➡️ matches or beats SOTA (=brute force) on CIFAR-10/100 adversarial accuracy cheaply w/o any adversarial training (on the RobustBench). With it, it's even better! 5/12
1) 🔎 at all resolutions &
2) 🪜at all abstraction scales
➡️ much harder to attack
➡️ matches or beats SOTA (=brute force) on CIFAR-10/100 adversarial accuracy cheaply w/o any adversarial training (on the RobustBench). With it, it's even better! 5/12
We use this as an active adversarial defense by combining intermediate layer predictions into a self-ensemble
We do this via our new, Vickrey auction & balanced allocation inspired robust ensembling procedure we call CrossMax which behaves in an anti-Goodhart way
4/12
We do this via our new, Vickrey auction & balanced allocation inspired robust ensembling procedure we call CrossMax which behaves in an anti-Goodhart way
4/12

November 19, 2024 at 6:19 PM
We use this as an active adversarial defense by combining intermediate layer predictions into a self-ensemble
We do this via our new, Vickrey auction & balanced allocation inspired robust ensembling procedure we call CrossMax which behaves in an anti-Goodhart way
4/12
We do this via our new, Vickrey auction & balanced allocation inspired robust ensembling procedure we call CrossMax which behaves in an anti-Goodhart way
4/12
We show that, surprisingly (!), adversarial attacks on standard neural networks don't fool the full network, only its final layer!
A dog 🐕 attacked to look like a car 🚘 still has dog 🐕-like edges, textures, & even higher-level features.
3/12
A dog 🐕 attacked to look like a car 🚘 still has dog 🐕-like edges, textures, & even higher-level features.
3/12

November 19, 2024 at 6:19 PM
We show that, surprisingly (!), adversarial attacks on standard neural networks don't fool the full network, only its final layer!
A dog 🐕 attacked to look like a car 🚘 still has dog 🐕-like edges, textures, & even higher-level features.
3/12
A dog 🐕 attacked to look like a car 🚘 still has dog 🐕-like edges, textures, & even higher-level features.
3/12
We built a multi-resolution prior inspired by the saccade movement of human eyes 👀, stacking ever lower resolution versions of an image channel-wise & training on the full stack at once
At low learning rates (but not high ones!) we get natural robust features by default
2/12
At low learning rates (but not high ones!) we get natural robust features by default
2/12


November 19, 2024 at 6:19 PM
We built a multi-resolution prior inspired by the saccade movement of human eyes 👀, stacking ever lower resolution versions of an image channel-wise & training on the full stack at once
At low learning rates (but not high ones!) we get natural robust features by default
2/12
At low learning rates (but not high ones!) we get natural robust features by default
2/12
✨ Super excited to share our paper **Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness** arxiv.org/abs/2408.05446 ✨
Inspired by biology we 1) get adversarial robustness + interpretability for free, 2) turn classifiers into generators & 3) design attacks on GPT-4
Inspired by biology we 1) get adversarial robustness + interpretability for free, 2) turn classifiers into generators & 3) design attacks on GPT-4


November 19, 2024 at 6:19 PM
✨ Super excited to share our paper **Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness** arxiv.org/abs/2408.05446 ✨
Inspired by biology we 1) get adversarial robustness + interpretability for free, 2) turn classifiers into generators & 3) design attacks on GPT-4
Inspired by biology we 1) get adversarial robustness + interpretability for free, 2) turn classifiers into generators & 3) design attacks on GPT-4
My favorite description of a large language model was accidentally written by Ray Bradbury in 1969, more than half a century ago, and it's eerie how fitting its rendition of an emergent language mind is:
vvvvvvv The poem follows in the replies vvvvvv
vvvvvvv The poem follows in the replies vvvvvv

November 15, 2024 at 9:59 AM
My favorite description of a large language model was accidentally written by Ray Bradbury in 1969, more than half a century ago, and it's eerie how fitting its rendition of an emergent language mind is:
vvvvvvv The poem follows in the replies vvvvvv
vvvvvvv The poem follows in the replies vvvvvv
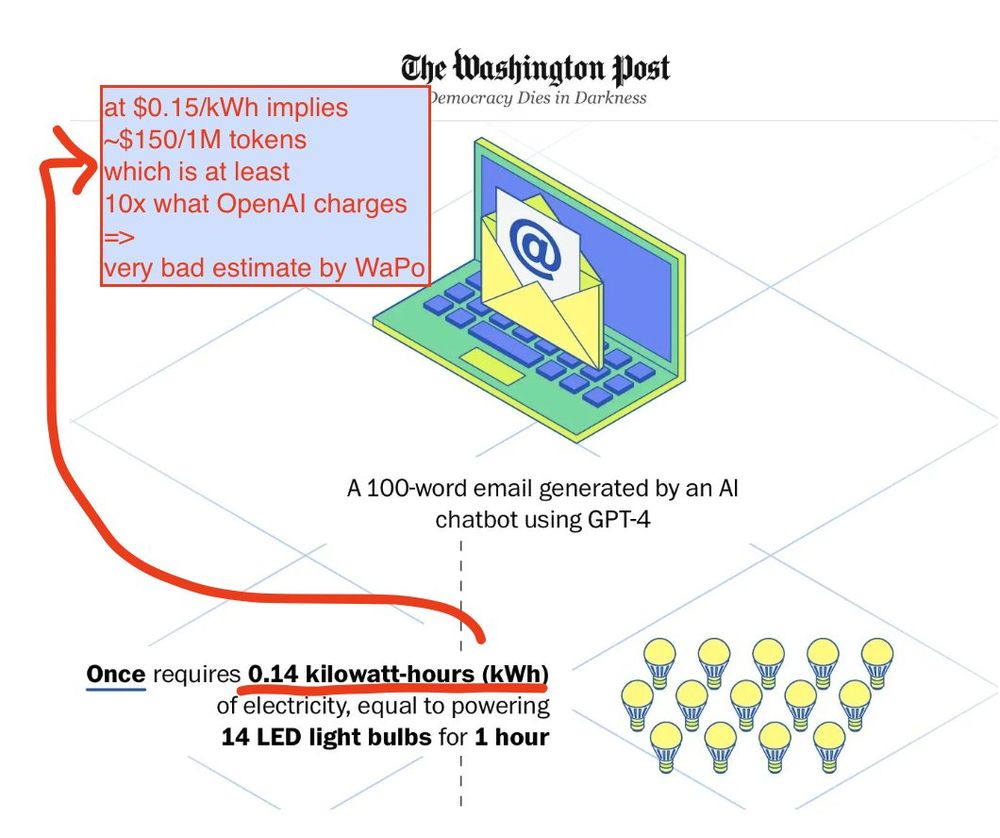
There is a popular piece by @washingtonpost.com claiming that GPT-4 consumes 0.14 kWh per 100 words. At $0.15/kWh this implies ~$150/1M tokens *for electricity alone* which is 10x what OpenAI charges *in total*. The WaPo estimate is therefore certainly very off and should be corrected
October 2, 2024 at 1:03 PM
There is a popular piece by @washingtonpost.com claiming that GPT-4 consumes 0.14 kWh per 100 words. At $0.15/kWh this implies ~$150/1M tokens *for electricity alone* which is 10x what OpenAI charges *in total*. The WaPo estimate is therefore certainly very off and should be corrected
I have written up my argument for solving adversarial attacks in computer vision as a baby version of general AI alignment. I think that the *shape* of the problem is very similar & that we *have* to be able to solve it before tackling the A(G)I case.
Blog post: www.lesswrong.com/posts/oPnFzf...
Blog post: www.lesswrong.com/posts/oPnFzf...

September 4, 2024 at 5:25 AM
I have written up my argument for solving adversarial attacks in computer vision as a baby version of general AI alignment. I think that the *shape* of the problem is very similar & that we *have* to be able to solve it before tackling the A(G)I case.
Blog post: www.lesswrong.com/posts/oPnFzf...
Blog post: www.lesswrong.com/posts/oPnFzf...