




Srishti
@srishtiy.bsky.social
ELLIS PhD Fellow @belongielab.org | @aicentre.dk | University of Copenhagen | @amsterdamnlp.bsky.social | @ellis.eu
Multi-modal ML | Alignment | Culture | Evaluations & Safety| AI & Society
Web: https://www.srishti.dev/
Multi-modal ML | Alignment | Culture | Evaluations & Safety| AI & Society
Web: https://www.srishti.dev/
Reposted by Srishti

Which, whose, and how much knowledge do LLMs represent?
I'm excited to share our preprint answering these questions:
"Epistemic Diversity and Knowledge Collapse in Large Language Models"
📄Paper: arxiv.org/pdf/2510.04226
💻Code: github.com/dwright37/ll...
1/10
I'm excited to share our preprint answering these questions:
"Epistemic Diversity and Knowledge Collapse in Large Language Models"
📄Paper: arxiv.org/pdf/2510.04226
💻Code: github.com/dwright37/ll...
1/10

October 13, 2025 at 11:25 AM
Which, whose, and how much knowledge do LLMs represent?
I'm excited to share our preprint answering these questions:
"Epistemic Diversity and Knowledge Collapse in Large Language Models"
📄Paper: arxiv.org/pdf/2510.04226
💻Code: github.com/dwright37/ll...
1/10
I'm excited to share our preprint answering these questions:
"Epistemic Diversity and Knowledge Collapse in Large Language Models"
📄Paper: arxiv.org/pdf/2510.04226
💻Code: github.com/dwright37/ll...
1/10
Reposted by Srishti

Happy to share that our work on multi-modal framing analysis of news was accepted to #EMNLP2025!
Understanding news output and embedded biases is especially important in today's environment and it's imperative to take a holistic look at it.
Looking forward to presenting it in Suzhou!
Understanding news output and embedded biases is especially important in today's environment and it's imperative to take a holistic look at it.
Looking forward to presenting it in Suzhou!
🚨New pre-print 🚨
News articles often convey different things in text vs. image. Recent work in computational framing analysis has analysed the article text but the corresponding images in those articles have been overlooked.
We propose multi-modal framing analysis of news: arxiv.org/abs/2503.20960
News articles often convey different things in text vs. image. Recent work in computational framing analysis has analysed the article text but the corresponding images in those articles have been overlooked.
We propose multi-modal framing analysis of news: arxiv.org/abs/2503.20960

August 21, 2025 at 1:24 PM
Happy to share that our work on multi-modal framing analysis of news was accepted to #EMNLP2025!
Understanding news output and embedded biases is especially important in today's environment and it's imperative to take a holistic look at it.
Looking forward to presenting it in Suzhou!
Understanding news output and embedded biases is especially important in today's environment and it's imperative to take a holistic look at it.
Looking forward to presenting it in Suzhou!
Reposted by Srishti

🎓 Looking for PhD opportunities in #NLProc for a start in Spring 2026?
🗒️ Add your expression of interest to join @copenlu.bsky.social here by 20 July: forms.office.com/e/HZSmgR9nXB
Selected candidates will be invited to submit a DARA fellowship application with me: daracademy.dk/fellowship/f...
🗒️ Add your expression of interest to join @copenlu.bsky.social here by 20 July: forms.office.com/e/HZSmgR9nXB
Selected candidates will be invited to submit a DARA fellowship application with me: daracademy.dk/fellowship/f...
Microsoft Forms
forms.office.com
June 27, 2025 at 6:51 AM
🎓 Looking for PhD opportunities in #NLProc for a start in Spring 2026?
🗒️ Add your expression of interest to join @copenlu.bsky.social here by 20 July: forms.office.com/e/HZSmgR9nXB
Selected candidates will be invited to submit a DARA fellowship application with me: daracademy.dk/fellowship/f...
🗒️ Add your expression of interest to join @copenlu.bsky.social here by 20 July: forms.office.com/e/HZSmgR9nXB
Selected candidates will be invited to submit a DARA fellowship application with me: daracademy.dk/fellowship/f...
Reposted by Srishti

📣 I am happy to support Ph.D applications to the Danish Advanced Research Academy. My main areas of research include multimodal learning and tokenization-free language processing. Feel free to reach out if you have similar interests! Applications due August 29 www.daracademy.dk/fellowship/f...
Dara
www.daracademy.dk
June 26, 2025 at 2:40 PM
📣 I am happy to support Ph.D applications to the Danish Advanced Research Academy. My main areas of research include multimodal learning and tokenization-free language processing. Feel free to reach out if you have similar interests! Applications due August 29 www.daracademy.dk/fellowship/f...

Reposted by Srishti

My favorite part of going to conferences: @belongielab.org alumni get-togethers! A big thank you to Menglin for coordinating the lunch at @cvprconference.bsky.social 🙏
Left: Tsung-Yi Lin, Guandao Yang, Katie Luo, Boyi Li; Right: Menglin Jia, Subarna Tripathi, Ph.D., Srishti, Xun Huang
Left: Tsung-Yi Lin, Guandao Yang, Katie Luo, Boyi Li; Right: Menglin Jia, Subarna Tripathi, Ph.D., Srishti, Xun Huang

June 13, 2025 at 12:07 AM
My favorite part of going to conferences: @belongielab.org alumni get-togethers! A big thank you to Menglin for coordinating the lunch at @cvprconference.bsky.social 🙏
Left: Tsung-Yi Lin, Guandao Yang, Katie Luo, Boyi Li; Right: Menglin Jia, Subarna Tripathi, Ph.D., Srishti, Xun Huang
Left: Tsung-Yi Lin, Guandao Yang, Katie Luo, Boyi Li; Right: Menglin Jia, Subarna Tripathi, Ph.D., Srishti, Xun Huang
Reposted by Srishti

Panel talk happening right now at @vlms4all.bsky.social ! Come join us at #CVPR25 (room: 104E)


June 12, 2025 at 10:38 PM
Panel talk happening right now at @vlms4all.bsky.social ! Come join us at #CVPR25 (room: 104E)
Reposted by Srishti

🚀 Technical practitioners & grads — join to build an LLM evaluation hub!
Infra Goals:
🔧 Share evaluation outputs & params
📊 Query results across experiments
Perfect for 🧰 hands-on folks ready to build tools the whole community can use
Join the EvalEval Coalition here 👇
forms.gle/6fEmrqJkxidy...
Infra Goals:
🔧 Share evaluation outputs & params
📊 Query results across experiments
Perfect for 🧰 hands-on folks ready to build tools the whole community can use
Join the EvalEval Coalition here 👇
forms.gle/6fEmrqJkxidy...

[EvalEval Infra] Better Infrastructure for LM Evals
Welcome to EvalEval Working Group Infrastructure! Please help us get set up by filling out this form - we are excited to get to know you! This is an interest form to contribute/collaborate on a research project, building standardized infrastructure for AI evaluation. Status Quo: The AI evaluation ecosystem currently lacks standardized methods for storing, sharing, and comparing evaluation results across different models and benchmarks. This fragmentation leads to unnecessary duplication of compute-intensive evaluations, challenges in reproducing results, and barriers to comprehensive cross-model analysis. What's the project? We plan to address these challenges by developing a comprehensive standardized format for capturing the complete evaluation lifecycle. This format will provide a clear and extensible structure for documenting evaluation inputs (hyperparameters, prompts, datasets), outputs, metrics, and metadata. This standardization enables efficient storage, retrieval, sharing, and comparison of evaluation results across the AI research community. Building on this foundation, we will create a centralized repository with both raw data access and API interfaces that allow researchers to contribute evaluation runs and access cached results. The project will integrate with popular evaluation frameworks (LM-eval, HELM, Unitxt) and provide SDKs to simplify adoption. Additionally, we will populate the repository with evaluation results from leading AI models across diverse benchmarks, creating a valuable resource that reduces computational redundancy and facilitates deeper comparative analysis. Tasks? As a collaborator, you would be expected to: Work towards merging/integrating popular evaluation frameworks (LM-eval, HELM, Unitxt) Group 1 - Extend to Any Task: Design universal metadata schemas that work for ANY NLP task, extending beyond current frameworks like lm-eval/DOVE to support specialized domains (e.g., machine translation) Group 2 - Save the Relevant: Develop efficient query/download systems for accessing only relevant data subsets from massive repositories (DOVE: 2TB, HELM: extensive metadata) The result will be open infrastructure for the AI research community, plus an academic publication. When? We're looking for researchers who can join ASAP and work with us for at least 5 to 7 months. We are hoping to find researchers who would take this on as an active project (8 hours+/week) in this period.
forms.gle
June 12, 2025 at 3:01 PM
🚀 Technical practitioners & grads — join to build an LLM evaluation hub!
Infra Goals:
🔧 Share evaluation outputs & params
📊 Query results across experiments
Perfect for 🧰 hands-on folks ready to build tools the whole community can use
Join the EvalEval Coalition here 👇
forms.gle/6fEmrqJkxidy...
Infra Goals:
🔧 Share evaluation outputs & params
📊 Query results across experiments
Perfect for 🧰 hands-on folks ready to build tools the whole community can use
Join the EvalEval Coalition here 👇
forms.gle/6fEmrqJkxidy...
Reposted by Srishti

Please join us for the FGVC workshop at CVPR 2025 @cvprconference.bsky.social on Wed 11th of June. The full schedule and list of fantastic speakers can be found on our website:
sites.google.com/view/fgvc12
sites.google.com/view/fgvc12

Join us on June 11, 9am to discuss all things fine-grained!
We are looking forward to a series of talks on semantic granularity, covering topics such as machine teaching, interpretability and much more!
Room 104 E
Schedule & details: sites.google.com/view/fgvc12
@cvprconference.bsky.social #CVPR25
We are looking forward to a series of talks on semantic granularity, covering topics such as machine teaching, interpretability and much more!
Room 104 E
Schedule & details: sites.google.com/view/fgvc12
@cvprconference.bsky.social #CVPR25

June 9, 2025 at 10:43 AM
Please join us for the FGVC workshop at CVPR 2025 @cvprconference.bsky.social on Wed 11th of June. The full schedule and list of fantastic speakers can be found on our website:
sites.google.com/view/fgvc12
sites.google.com/view/fgvc12
Reposted by Srishti

Can you train a performant language model using only openly licensed text?
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2

June 6, 2025 at 7:19 PM
Can you train a performant language model using only openly licensed text?
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
Reposted by Srishti

"Large [language] models should not be viewed primarily as intelligent agents but as a new kind of cultural and social technology, allowing humans to take advantage of information other humans have accumulated." henryfarrell.net/wp-content/u...
June 7, 2025 at 4:59 PM
"Large [language] models should not be viewed primarily as intelligent agents but as a new kind of cultural and social technology, allowing humans to take advantage of information other humans have accumulated." henryfarrell.net/wp-content/u...
Reposted by Srishti
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)

NeurIPS participation in Europe
We seek to understand if there is interest in being able to attend NeurIPS in Europe, i.e. without travelling to San Diego, US. In the following, assume that it is possible to present accepted papers ...
docs.google.com
March 30, 2025 at 6:04 PM
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)
Reposted by Srishti

"I don’t want to just be entering text prompts for the rest of my life."
I spoke to political cartoonists, including Pulitzer-winner Mark Fiore, about how they are using AI image generators in their work. My latest for @niemanlab.org.
www.niemanlab.org/2025/06/i-do...
I spoke to political cartoonists, including Pulitzer-winner Mark Fiore, about how they are using AI image generators in their work. My latest for @niemanlab.org.
www.niemanlab.org/2025/06/i-do...

“I don’t want to outsource my brain”: How political cartoonists are bringing AI into their work
Pulitzer-winning cartoonists are experimenting with AI image generators.
www.niemanlab.org
June 3, 2025 at 6:10 PM
"I don’t want to just be entering text prompts for the rest of my life."
I spoke to political cartoonists, including Pulitzer-winner Mark Fiore, about how they are using AI image generators in their work. My latest for @niemanlab.org.
www.niemanlab.org/2025/06/i-do...
I spoke to political cartoonists, including Pulitzer-winner Mark Fiore, about how they are using AI image generators in their work. My latest for @niemanlab.org.
www.niemanlab.org/2025/06/i-do...
Reposted by Srishti

There's been a lot of work on "culture" in NLP, but not much agreement on what it is.
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n

February 18, 2025 at 8:45 PM
There's been a lot of work on "culture" in NLP, but not much agreement on what it is.
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
A position paper by me, @dbamman.bsky.social, and @ibleaman.bsky.social on cultural NLP: what we want, what we have, and how sociocultural linguistics can clarify things.
Website: naitian.org/culture-not-...
1/n
Reposted by Srishti

Check out our new preprint 𝐓𝐞𝐧𝐬𝐨𝐫𝐆𝐑𝐚𝐃.
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
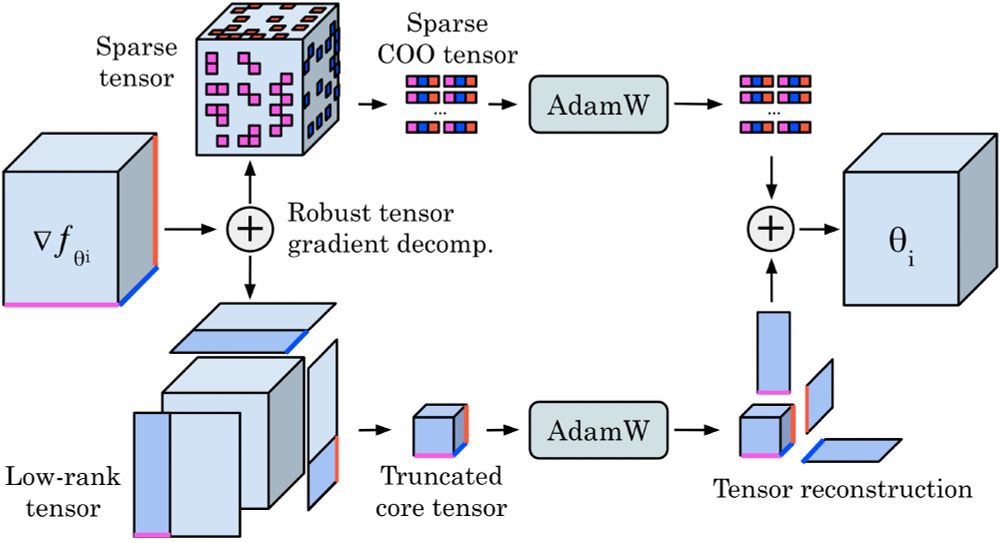
June 3, 2025 at 3:17 AM
Check out our new preprint 𝐓𝐞𝐧𝐬𝐨𝐫𝐆𝐑𝐚𝐃.
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
Reposted by Srishti

PhD student, Srishti Yadav and her collaborators, out with new, interdisciplinary work👇
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793

June 2, 2025 at 6:09 PM
PhD student, Srishti Yadav and her collaborators, out with new, interdisciplinary work👇
Reposted by Srishti

Check out our new paper led by @srishtiy.bsky.social and @nolauren.bsky.social! This work brings together computer vision, cultural theory, semiotics, and visual studies to provide new tools and perspectives for the study of ~culture~ in VLMs.
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793
June 2, 2025 at 12:37 PM
Check out our new paper led by @srishtiy.bsky.social and @nolauren.bsky.social! This work brings together computer vision, cultural theory, semiotics, and visual studies to provide new tools and perspectives for the study of ~culture~ in VLMs.
Reposted by Srishti

A delight to work with great colleagues to bring theory around visual culture and cultural studies to how we think about visual language models.
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793
June 2, 2025 at 10:42 AM
A delight to work with great colleagues to bring theory around visual culture and cultural studies to how we think about visual language models.
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793
June 2, 2025 at 10:36 AM
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
Paper 🔗: arxiv.org/pdf/2505.22793
Reposted by Srishti
This morning at P1 a handful of lucky of lab members got to see the telescope while centre secretary Björg had the dome open for a building tour 🔭 (1/7)

May 9, 2025 at 10:30 PM
This morning at P1 a handful of lucky of lab members got to see the telescope while centre secretary Björg had the dome open for a building tour 🔭 (1/7)
Reposted by Srishti

🚀New Preprint🚀
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇

May 23, 2025 at 5:04 PM
🚀New Preprint🚀
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
When you have a lot of work before the deadline push, you keep thinking of others things (distractions) you’d like to do. The day you get free, those things suddenly don’t seem important anymore. And kind of miss work! 🙄
May 23, 2025 at 5:38 PM
When you have a lot of work before the deadline push, you keep thinking of others things (distractions) you’d like to do. The day you get free, those things suddenly don’t seem important anymore. And kind of miss work! 🙄
Reposted by Srishti

🗞️ Just released a Parquet version of the Newspaper Navigator dataset on @hf.co!
- 3M+ visual elements from historic US newspapers — photos, maps, cartoons, OCR + metadata.
- Parquet = fast filters, easier analysis.
- Great for ML + cultural research.
👉 huggingface.co/datasets/big...
- 3M+ visual elements from historic US newspapers — photos, maps, cartoons, OCR + metadata.
- Parquet = fast filters, easier analysis.
- Great for ML + cultural research.
👉 huggingface.co/datasets/big...

May 20, 2025 at 11:50 AM
🗞️ Just released a Parquet version of the Newspaper Navigator dataset on @hf.co!
- 3M+ visual elements from historic US newspapers — photos, maps, cartoons, OCR + metadata.
- Parquet = fast filters, easier analysis.
- Great for ML + cultural research.
👉 huggingface.co/datasets/big...
- 3M+ visual elements from historic US newspapers — photos, maps, cartoons, OCR + metadata.
- Parquet = fast filters, easier analysis.
- Great for ML + cultural research.
👉 huggingface.co/datasets/big...
Reposted by Srishti
We work under this telescope and sometimes get to visit it!
This morning at P1 a handful of lucky of lab members got to see the telescope while centre secretary Björg had the dome open for a building tour 🔭 (1/7)
May 10, 2025 at 6:29 AM
We work under this telescope and sometimes get to visit it!
Reposted by Srishti

I will present our #ICLR2025 Spotlight paper MM-FSS this week in Singapore!
Curious how MULTIMODALITY can enhance FEW-SHOT 3D SEGMENTATION WITHOUT any additional cost? Come chat with us at the poster session — always happy to connect!🤝
🗓️ Fri 25 Apr, 3 - 5:30 pm
📍 Hall 3 + Hall 2B #504
More follow
Curious how MULTIMODALITY can enhance FEW-SHOT 3D SEGMENTATION WITHOUT any additional cost? Come chat with us at the poster session — always happy to connect!🤝
🗓️ Fri 25 Apr, 3 - 5:30 pm
📍 Hall 3 + Hall 2B #504
More follow

April 23, 2025 at 2:39 AM
I will present our #ICLR2025 Spotlight paper MM-FSS this week in Singapore!
Curious how MULTIMODALITY can enhance FEW-SHOT 3D SEGMENTATION WITHOUT any additional cost? Come chat with us at the poster session — always happy to connect!🤝
🗓️ Fri 25 Apr, 3 - 5:30 pm
📍 Hall 3 + Hall 2B #504
More follow
Curious how MULTIMODALITY can enhance FEW-SHOT 3D SEGMENTATION WITHOUT any additional cost? Come chat with us at the poster session — always happy to connect!🤝
🗓️ Fri 25 Apr, 3 - 5:30 pm
📍 Hall 3 + Hall 2B #504
More follow