



@eleutherai.bsky.social
Announcing our latest paper: CommonLID
In collaboration with @commoncrawl.bsky.social @mlcommons.org @jhu.edu we built a LID benchmark on actual Common Crawl text covering 109 languages. Existing evaluations overestimate how well LangID works on web data.
arxiv.org/abs/2601.18026
In collaboration with @commoncrawl.bsky.social @mlcommons.org @jhu.edu we built a LID benchmark on actual Common Crawl text covering 109 languages. Existing evaluations overestimate how well LangID works on web data.
arxiv.org/abs/2601.18026

CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data of...
arxiv.org
February 13, 2026 at 7:27 PM
Announcing our latest paper: CommonLID
In collaboration with @commoncrawl.bsky.social @mlcommons.org @jhu.edu we built a LID benchmark on actual Common Crawl text covering 109 languages. Existing evaluations overestimate how well LangID works on web data.
arxiv.org/abs/2601.18026
In collaboration with @commoncrawl.bsky.social @mlcommons.org @jhu.edu we built a LID benchmark on actual Common Crawl text covering 109 languages. Existing evaluations overestimate how well LangID works on web data.
arxiv.org/abs/2601.18026
We’re bringing back a Community Spotlight talk series, highlighting cool work being done by members of our community. We’re kicking it off with a talk on running diffusion-based world-models in real time on consumer hardware.
Jan 9th at 2 pm US Eastern Time
Jan 9th at 2 pm US Eastern Time
January 9, 2026 at 12:56 AM
We’re bringing back a Community Spotlight talk series, highlighting cool work being done by members of our community. We’re kicking it off with a talk on running diffusion-based world-models in real time on consumer hardware.
Jan 9th at 2 pm US Eastern Time
Jan 9th at 2 pm US Eastern Time
We are launching a new speaker series at EleutherAI, focused on promoting recent research by our team and community members.
Our first talk is by @catherinearnett.bsky.social on tokenizers, their limitations, and how to improve them.
Our first talk is by @catherinearnett.bsky.social on tokenizers, their limitations, and how to improve them.

June 26, 2025 at 6:16 PM
We are launching a new speaker series at EleutherAI, focused on promoting recent research by our team and community members.
Our first talk is by @catherinearnett.bsky.social on tokenizers, their limitations, and how to improve them.
Our first talk is by @catherinearnett.bsky.social on tokenizers, their limitations, and how to improve them.
Can you train a performant language model using only openly licensed text?
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2

June 6, 2025 at 7:19 PM
Can you train a performant language model using only openly licensed text?
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1 & 2
Reposted

Call for papers!
We are organising the 1st Workshop on Multilingual Data Quality Signals with @mlcommons.org and @eleutherai.bsky.social, held in tandem with @colmweb.org. Submit your research on multilingual data quality!
Submission deadline is 23 June, more info: wmdqs.org
We are organising the 1st Workshop on Multilingual Data Quality Signals with @mlcommons.org and @eleutherai.bsky.social, held in tandem with @colmweb.org. Submit your research on multilingual data quality!
Submission deadline is 23 June, more info: wmdqs.org
1st Workshop on Multilingual Data Quality Signals
wmdqs.org
May 29, 2025 at 5:18 PM
Call for papers!
We are organising the 1st Workshop on Multilingual Data Quality Signals with @mlcommons.org and @eleutherai.bsky.social, held in tandem with @colmweb.org. Submit your research on multilingual data quality!
Submission deadline is 23 June, more info: wmdqs.org
We are organising the 1st Workshop on Multilingual Data Quality Signals with @mlcommons.org and @eleutherai.bsky.social, held in tandem with @colmweb.org. Submit your research on multilingual data quality!
Submission deadline is 23 June, more info: wmdqs.org
Today, at 11am ET, @storytracer.org will be giving a live demo on the @mozilla.ai Discord showcasing two Blueprints for creating open datasets: audio transcription using self-hosted Whisper models and document conversion using Docling. Join the event here: discord.com/invite/4jtc8...

April 28, 2025 at 12:26 PM
Today, at 11am ET, @storytracer.org will be giving a live demo on the @mozilla.ai Discord showcasing two Blueprints for creating open datasets: audio transcription using self-hosted Whisper models and document conversion using Docling. Join the event here: discord.com/invite/4jtc8...
Very cool work!

🚀 **Exciting News!** 🎉 Evalita-LLM is here! 🇮🇹 A new benchmark for evaluating LLMs—offering native Italian tasks, generative challenges, and fair multi-prompt evaluations. Now also available in lm-evaluation harness by @eleutherai.bsky.social !
ArXiv: arxiv.org/abs/2502.02289
#NLProc #LLM #Evaluation
ArXiv: arxiv.org/abs/2502.02289
#NLProc #LLM #Evaluation

Evalita-LLM: Benchmarking Large Language Models on Italian
We describe Evalita-LLM, a new benchmark designed to evaluate Large Language Models (LLMs) on Italian tasks. The distinguishing and innovative features of Evalita-LLM are the following: (i) all tasks ...
arxiv.org
February 24, 2025 at 10:03 PM
Very cool work!
Reposted

Proud to be at the AI Action Summit representing @eleutherai.bsky.social and the open source community. The focus on AI for the public good is exciting! DM me or @aviya.bsky.social to talk about centering openness, transparency, and public good in the AI ecosystem.
February 10, 2025 at 11:51 AM
Proud to be at the AI Action Summit representing @eleutherai.bsky.social and the open source community. The focus on AI for the public good is exciting! DM me or @aviya.bsky.social to talk about centering openness, transparency, and public good in the AI ecosystem.
Reposted

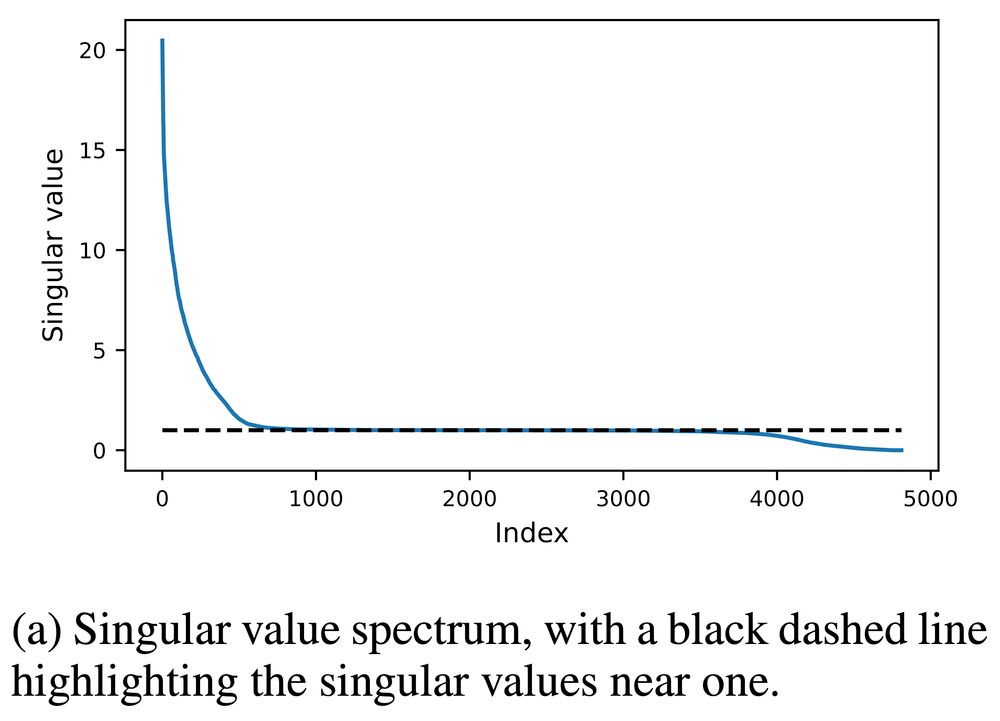
How do a neural network's final parameters depend on its initial ones?
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
December 11, 2024 at 8:30 PM
How do a neural network's final parameters depend on its initial ones?
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
The latest from our interpretability team: there is an ambiguity in prior work on the linear representation hypothesis:
Is a linear representation a linear function (that preserves the origin) or an affine function (that does not)? This distinction matters in practice. arxiv.org/abs/2411.09003
Is a linear representation a linear function (that preserves the origin) or an affine function (that does not)? This distinction matters in practice. arxiv.org/abs/2411.09003

Refusal in LLMs is an Affine Function
We propose affine concept editing (ACE) as an approach for steering language models' behavior by intervening directly in activations. We begin with an affine decomposition of model activation vectors ...
arxiv.org
November 22, 2024 at 3:15 AM
The latest from our interpretability team: there is an ambiguity in prior work on the linear representation hypothesis:
Is a linear representation a linear function (that preserves the origin) or an affine function (that does not)? This distinction matters in practice. arxiv.org/abs/2411.09003
Is a linear representation a linear function (that preserves the origin) or an affine function (that does not)? This distinction matters in practice. arxiv.org/abs/2411.09003
Proudly building a more open world with @opensource.bsky.social.

The critical question posed to attendees was “How can we best govern and share data to power Open Source AI? https://opensource.org/blog/open-data-and-open-source-ai-charting-a-course-to-get-more-of-both
opensource.org
November 20, 2024 at 1:17 PM
Proudly building a more open world with @opensource.bsky.social.