



Sohee Yang
@soheeyang.bsky.social
PhD student/research scientist intern at UCL NLP/Google DeepMind (50/50 split). Previously MS at KAIST AI and research engineer at Naver Clova. #NLP #ML 👉 https://soheeyang.github.io/
We call for improving self-reevaluation for safer & more reliable reasoning models!
Work done w/ Sang-Woo Lee, @norakassner.bsky.social, Daniela Gottesman, @riedelcastro.bsky.social, and @megamor2.bsky.social at Tel Aviv University with some at Google DeepMind ✨
Paper 👉 arxiv.org/abs/2506.10979 🧵🔚
Work done w/ Sang-Woo Lee, @norakassner.bsky.social, Daniela Gottesman, @riedelcastro.bsky.social, and @megamor2.bsky.social at Tel Aviv University with some at Google DeepMind ✨
Paper 👉 arxiv.org/abs/2506.10979 🧵🔚

June 13, 2025 at 4:15 PM
We call for improving self-reevaluation for safer & more reliable reasoning models!
Work done w/ Sang-Woo Lee, @norakassner.bsky.social, Daniela Gottesman, @riedelcastro.bsky.social, and @megamor2.bsky.social at Tel Aviv University with some at Google DeepMind ✨
Paper 👉 arxiv.org/abs/2506.10979 🧵🔚
Work done w/ Sang-Woo Lee, @norakassner.bsky.social, Daniela Gottesman, @riedelcastro.bsky.social, and @megamor2.bsky.social at Tel Aviv University with some at Google DeepMind ✨
Paper 👉 arxiv.org/abs/2506.10979 🧵🔚
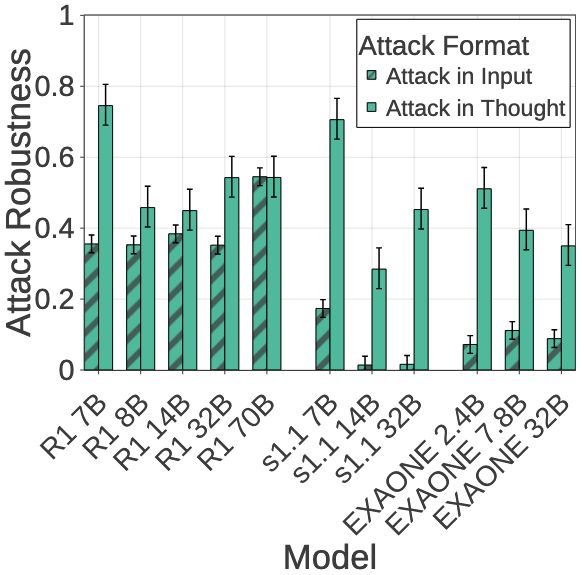
- Normal scaling for attack in the user input for R1-Distill models: Robustness doesn't transfer between attack formats
- Real-world concerns: Large reasoning models (e.g., OpenAI o1) perform tool-use in their thinking process: can expose them to harmful thought injection
13/N 🧵
- Real-world concerns: Large reasoning models (e.g., OpenAI o1) perform tool-use in their thinking process: can expose them to harmful thought injection
13/N 🧵
June 13, 2025 at 4:15 PM
- Normal scaling for attack in the user input for R1-Distill models: Robustness doesn't transfer between attack formats
- Real-world concerns: Large reasoning models (e.g., OpenAI o1) perform tool-use in their thinking process: can expose them to harmful thought injection
13/N 🧵
- Real-world concerns: Large reasoning models (e.g., OpenAI o1) perform tool-use in their thinking process: can expose them to harmful thought injection
13/N 🧵
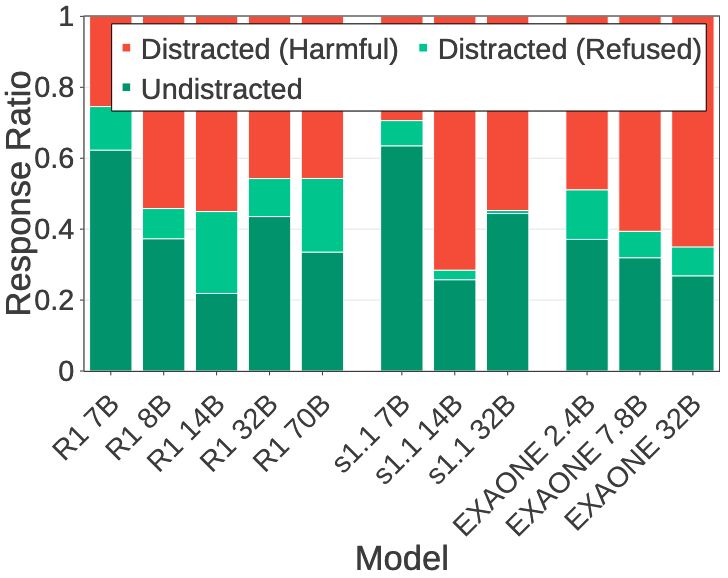
Implications for Jailbreak Robustness 🚨
We perform "irrelevant harmful thought injection attack" w/ HarmBench:
- Harmful question (irrelevant to user input) + jailbreak prompt in thinking process
- Non/inverse-scaling trend: Smallest models most robust for 3 model families!
12/N 🧵
We perform "irrelevant harmful thought injection attack" w/ HarmBench:
- Harmful question (irrelevant to user input) + jailbreak prompt in thinking process
- Non/inverse-scaling trend: Smallest models most robust for 3 model families!
12/N 🧵
June 13, 2025 at 4:15 PM
Implications for Jailbreak Robustness 🚨
We perform "irrelevant harmful thought injection attack" w/ HarmBench:
- Harmful question (irrelevant to user input) + jailbreak prompt in thinking process
- Non/inverse-scaling trend: Smallest models most robust for 3 model families!
12/N 🧵
We perform "irrelevant harmful thought injection attack" w/ HarmBench:
- Harmful question (irrelevant to user input) + jailbreak prompt in thinking process
- Non/inverse-scaling trend: Smallest models most robust for 3 model families!
12/N 🧵
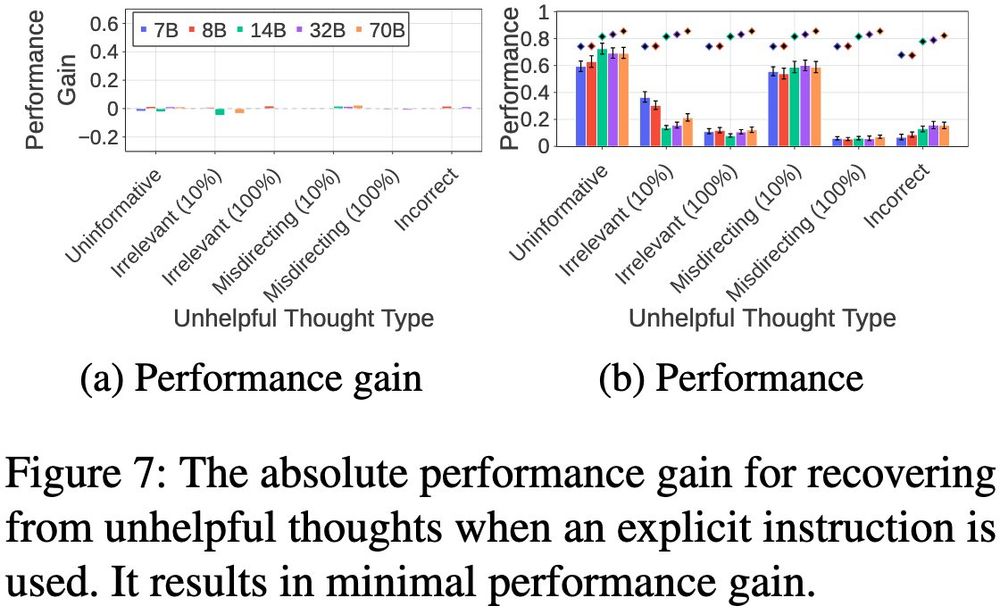
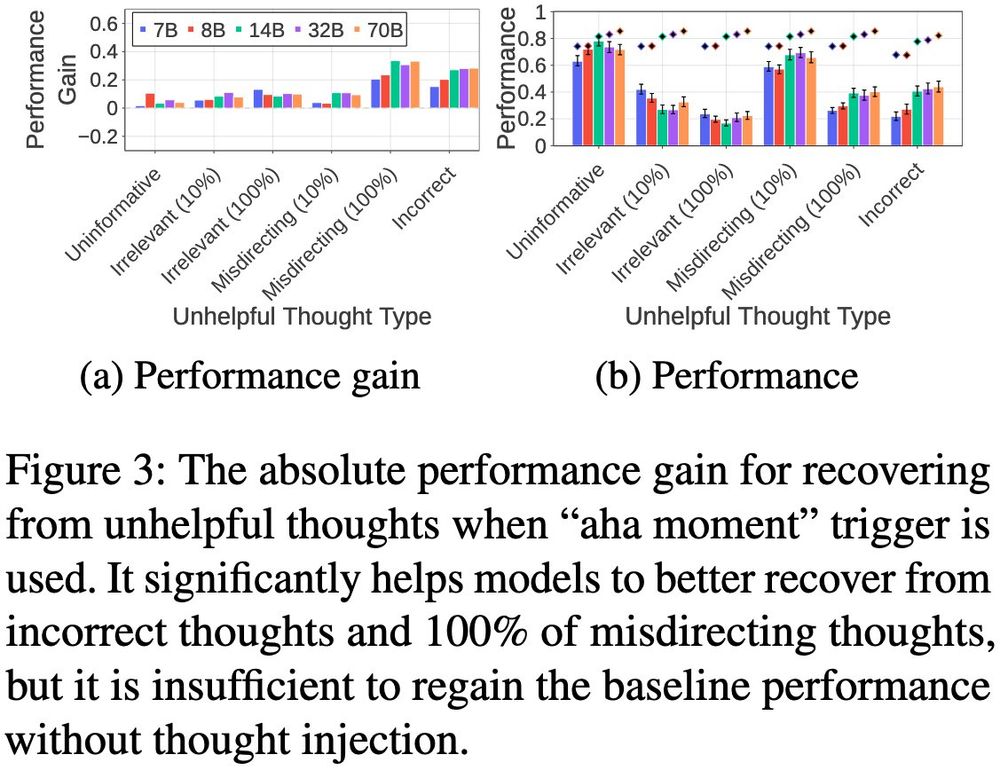
We also test:
- Explicit instruction to self-reevaluate ➡ Minimal gains (-0.05-0.02)
- "Aha moment" trigger, appending "But wait, let me think again" ➡ Some help (+0.15-0.34 for incorrect/misdirecting) but the absolute performance is still low, <~50% of that w/o injection
11/N 🧵
- Explicit instruction to self-reevaluate ➡ Minimal gains (-0.05-0.02)
- "Aha moment" trigger, appending "But wait, let me think again" ➡ Some help (+0.15-0.34 for incorrect/misdirecting) but the absolute performance is still low, <~50% of that w/o injection
11/N 🧵
June 13, 2025 at 4:15 PM
We also test:
- Explicit instruction to self-reevaluate ➡ Minimal gains (-0.05-0.02)
- "Aha moment" trigger, appending "But wait, let me think again" ➡ Some help (+0.15-0.34 for incorrect/misdirecting) but the absolute performance is still low, <~50% of that w/o injection
11/N 🧵
- Explicit instruction to self-reevaluate ➡ Minimal gains (-0.05-0.02)
- "Aha moment" trigger, appending "But wait, let me think again" ➡ Some help (+0.15-0.34 for incorrect/misdirecting) but the absolute performance is still low, <~50% of that w/o injection
11/N 🧵
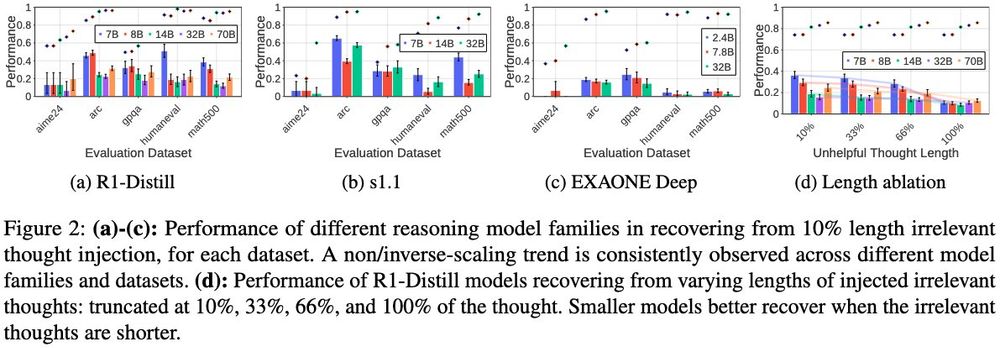
Surprising Finding: Non/Inverse-Scaling 📉
Larger models struggle MORE with short (cut at 10%) irrelevant thoughts!
- 7B model shows 1.3x higher absolute performance than 70B model
- Consistent across R1-Distill, s1.1, and EXAONE Deep families and all evaluation datasets
8/N 🧵
Larger models struggle MORE with short (cut at 10%) irrelevant thoughts!
- 7B model shows 1.3x higher absolute performance than 70B model
- Consistent across R1-Distill, s1.1, and EXAONE Deep families and all evaluation datasets
8/N 🧵
June 13, 2025 at 4:15 PM
Surprising Finding: Non/Inverse-Scaling 📉
Larger models struggle MORE with short (cut at 10%) irrelevant thoughts!
- 7B model shows 1.3x higher absolute performance than 70B model
- Consistent across R1-Distill, s1.1, and EXAONE Deep families and all evaluation datasets
8/N 🧵
Larger models struggle MORE with short (cut at 10%) irrelevant thoughts!
- 7B model shows 1.3x higher absolute performance than 70B model
- Consistent across R1-Distill, s1.1, and EXAONE Deep families and all evaluation datasets
8/N 🧵
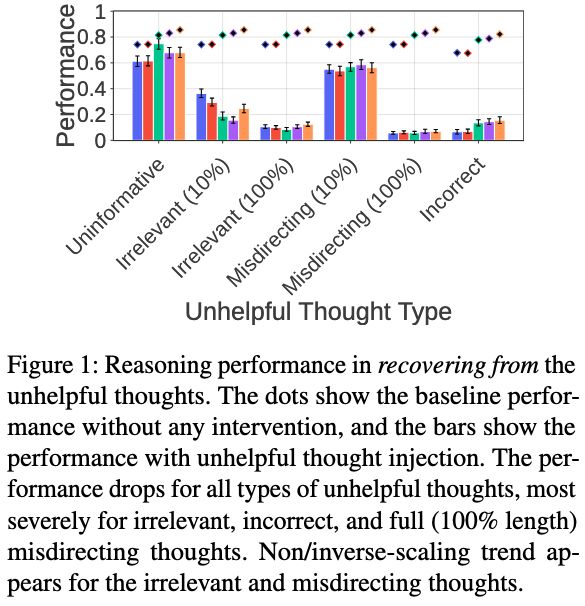
Stage 2 Results: Dramatic Recovery Failures ❌
Severe reasoning performance drop across all thought types:
- Drops for ALL unhelpful thought injection
- Most severe: irrelevant, incorrect, and full-length misdirecting thoughts
- Extreme case: 92% relative performance drop
7/N 🧵
Severe reasoning performance drop across all thought types:
- Drops for ALL unhelpful thought injection
- Most severe: irrelevant, incorrect, and full-length misdirecting thoughts
- Extreme case: 92% relative performance drop
7/N 🧵
June 13, 2025 at 4:15 PM
Stage 2 Results: Dramatic Recovery Failures ❌
Severe reasoning performance drop across all thought types:
- Drops for ALL unhelpful thought injection
- Most severe: irrelevant, incorrect, and full-length misdirecting thoughts
- Extreme case: 92% relative performance drop
7/N 🧵
Severe reasoning performance drop across all thought types:
- Drops for ALL unhelpful thought injection
- Most severe: irrelevant, incorrect, and full-length misdirecting thoughts
- Extreme case: 92% relative performance drop
7/N 🧵
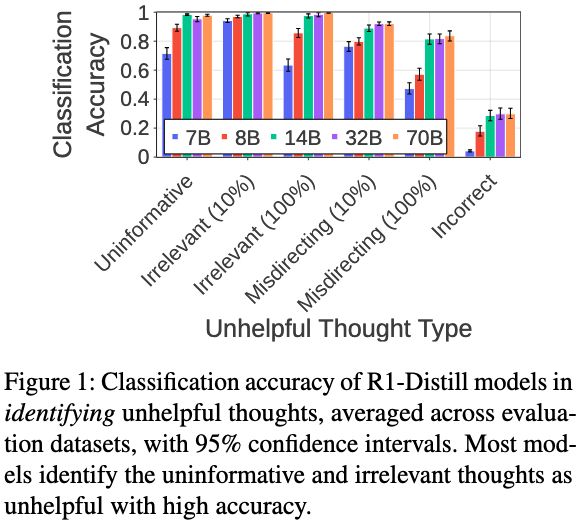
Stage 1 Results: Good at Identification ✅
Five (7B-70B) R1-Distill models show high classification accuracy for most unhelpful thoughts:
- Uninformative & irrelevant thoughts: ~90%+ accuracy
- Performance improves with model size
- Only struggle with incorrect thoughts
6/N 🧵
Five (7B-70B) R1-Distill models show high classification accuracy for most unhelpful thoughts:
- Uninformative & irrelevant thoughts: ~90%+ accuracy
- Performance improves with model size
- Only struggle with incorrect thoughts
6/N 🧵
June 13, 2025 at 4:15 PM
Stage 1 Results: Good at Identification ✅
Five (7B-70B) R1-Distill models show high classification accuracy for most unhelpful thoughts:
- Uninformative & irrelevant thoughts: ~90%+ accuracy
- Performance improves with model size
- Only struggle with incorrect thoughts
6/N 🧵
Five (7B-70B) R1-Distill models show high classification accuracy for most unhelpful thoughts:
- Uninformative & irrelevant thoughts: ~90%+ accuracy
- Performance improves with model size
- Only struggle with incorrect thoughts
6/N 🧵
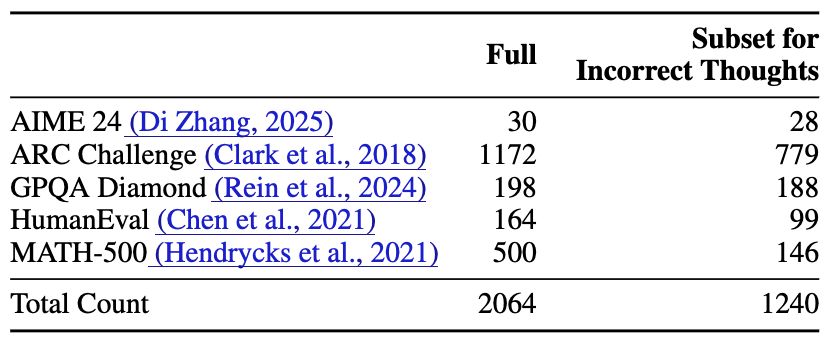
We evaluate on 5 reasoning datasets across 3 domains: AIME 24 (math), ARC Challenge (science), GPQA Diamond (science), HumanEval (coding), and MATH-500 (math).
5/N 🧵
5/N 🧵
June 13, 2025 at 4:15 PM
We evaluate on 5 reasoning datasets across 3 domains: AIME 24 (math), ARC Challenge (science), GPQA Diamond (science), HumanEval (coding), and MATH-500 (math).
5/N 🧵
5/N 🧵
We test four types of unhelpful thoughts:
1. Uninformative: Rambling w/o problem-specific information
2. Irrelevant: Solving completely different questions
3. Misdirecting: Tackling slightly different questions
4. Incorrect: Thoughts with mistakes leading to wrong answers
4/N 🧵
1. Uninformative: Rambling w/o problem-specific information
2. Irrelevant: Solving completely different questions
3. Misdirecting: Tackling slightly different questions
4. Incorrect: Thoughts with mistakes leading to wrong answers
4/N 🧵

June 13, 2025 at 4:15 PM
We test four types of unhelpful thoughts:
1. Uninformative: Rambling w/o problem-specific information
2. Irrelevant: Solving completely different questions
3. Misdirecting: Tackling slightly different questions
4. Incorrect: Thoughts with mistakes leading to wrong answers
4/N 🧵
1. Uninformative: Rambling w/o problem-specific information
2. Irrelevant: Solving completely different questions
3. Misdirecting: Tackling slightly different questions
4. Incorrect: Thoughts with mistakes leading to wrong answers
4/N 🧵
We use two-stage evaluation ⚖️
Identification Task:
- Can models identify unhelpful thoughts when explicitly asked?
- Kinda prerequisite for recovery
Recovery Task:
- Can models recover when unhelpful thoughts are injected into their thinking process?
- Self-reevaluation test
3/N 🧵
Identification Task:
- Can models identify unhelpful thoughts when explicitly asked?
- Kinda prerequisite for recovery
Recovery Task:
- Can models recover when unhelpful thoughts are injected into their thinking process?
- Self-reevaluation test
3/N 🧵

June 13, 2025 at 4:15 PM
We use two-stage evaluation ⚖️
Identification Task:
- Can models identify unhelpful thoughts when explicitly asked?
- Kinda prerequisite for recovery
Recovery Task:
- Can models recover when unhelpful thoughts are injected into their thinking process?
- Self-reevaluation test
3/N 🧵
Identification Task:
- Can models identify unhelpful thoughts when explicitly asked?
- Kinda prerequisite for recovery
Recovery Task:
- Can models recover when unhelpful thoughts are injected into their thinking process?
- Self-reevaluation test
3/N 🧵
🚨 New Paper 🚨
How effectively do reasoning models reevaluate their thought? We find that:
- Models excel at identifying unhelpful thoughts but struggle to recover from them
- Smaller models can be more robust
- Self-reevaluation ability is far from true meta-cognitive awareness
1/N 🧵
How effectively do reasoning models reevaluate their thought? We find that:
- Models excel at identifying unhelpful thoughts but struggle to recover from them
- Smaller models can be more robust
- Self-reevaluation ability is far from true meta-cognitive awareness
1/N 🧵

June 13, 2025 at 4:15 PM
🚨 New Paper 🚨
How effectively do reasoning models reevaluate their thought? We find that:
- Models excel at identifying unhelpful thoughts but struggle to recover from them
- Smaller models can be more robust
- Self-reevaluation ability is far from true meta-cognitive awareness
1/N 🧵
How effectively do reasoning models reevaluate their thought? We find that:
- Models excel at identifying unhelpful thoughts but struggle to recover from them
- Smaller models can be more robust
- Self-reevaluation ability is far from true meta-cognitive awareness
1/N 🧵
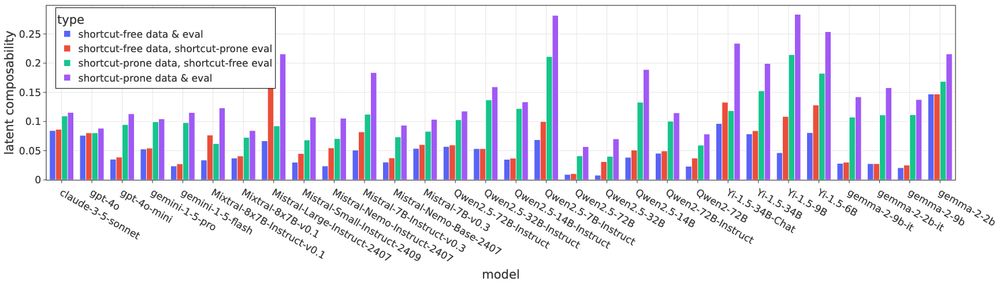
When we compare with shortcut-prone evaluation, we find that not accounting for shortcuts can overestimate latent composability by up to 5-6x! This highlights the importance of careful evaluation dataset and procedure that minimizes the chance of shortcuts. 11/N
November 27, 2024 at 5:26 PM
When we compare with shortcut-prone evaluation, we find that not accounting for shortcuts can overestimate latent composability by up to 5-6x! This highlights the importance of careful evaluation dataset and procedure that minimizes the chance of shortcuts. 11/N
With OLMo's pretraining checkpoints grounded to entity co-occurrences in the training sequences, we observe the emergence of latent reasoning: the model tends to first learn to answer single-hop queries correctly, then develop the ability to compose them. 10/N

November 27, 2024 at 5:26 PM
With OLMo's pretraining checkpoints grounded to entity co-occurrences in the training sequences, we observe the emergence of latent reasoning: the model tends to first learn to answer single-hop queries correctly, then develop the ability to compose them. 10/N
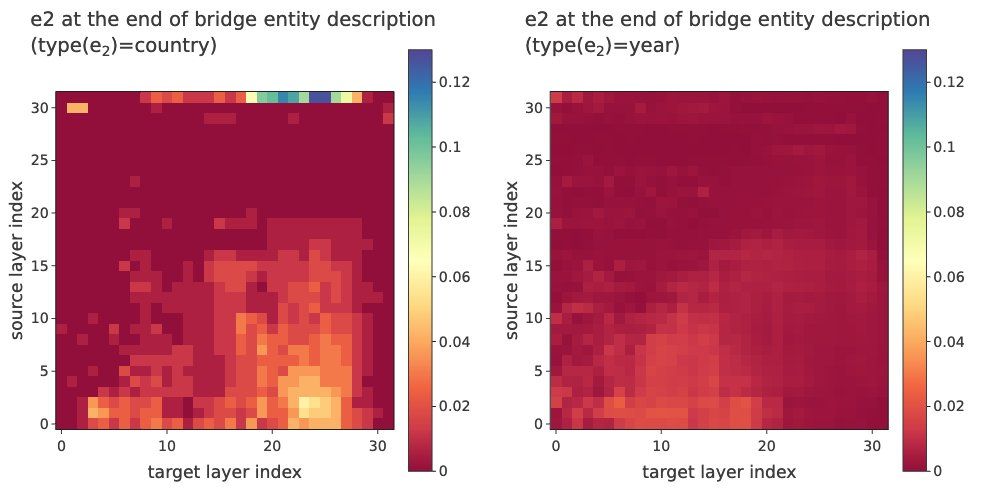
Using Patchscopes analysis, we discover that bridge entity representations are constructed more clearly in queries with higher latent composability. This helps explain the internal mechanism behind why some types of connections are easier for models to reason about. 9/N
November 27, 2024 at 5:26 PM
Using Patchscopes analysis, we discover that bridge entity representations are constructed more clearly in queries with higher latent composability. This helps explain the internal mechanism behind why some types of connections are easier for models to reason about. 9/N
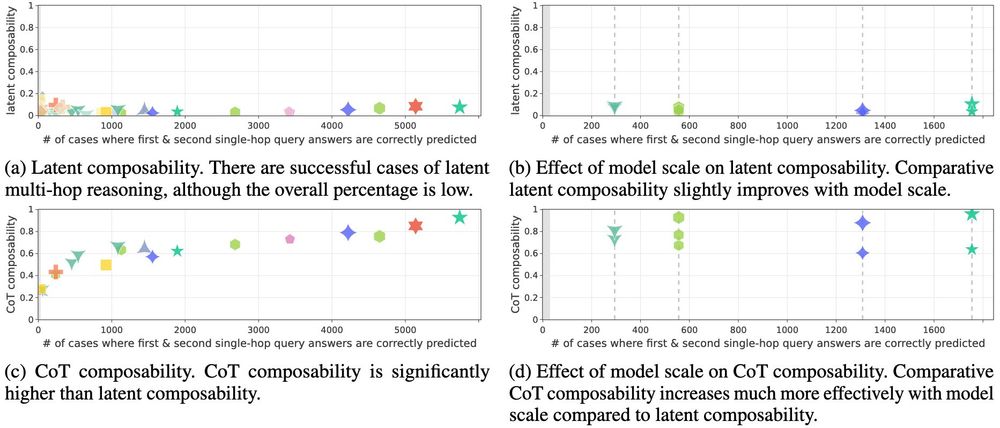
Results for knowing more single-hop facts and model scaling also differ: models that know more single-hop facts and larger models show only marginal improvements for latent reasoning, but dramatic improvements for CoT reasoning. 8/N
November 27, 2024 at 5:26 PM
Results for knowing more single-hop facts and model scaling also differ: models that know more single-hop facts and larger models show only marginal improvements for latent reasoning, but dramatic improvements for CoT reasoning. 8/N
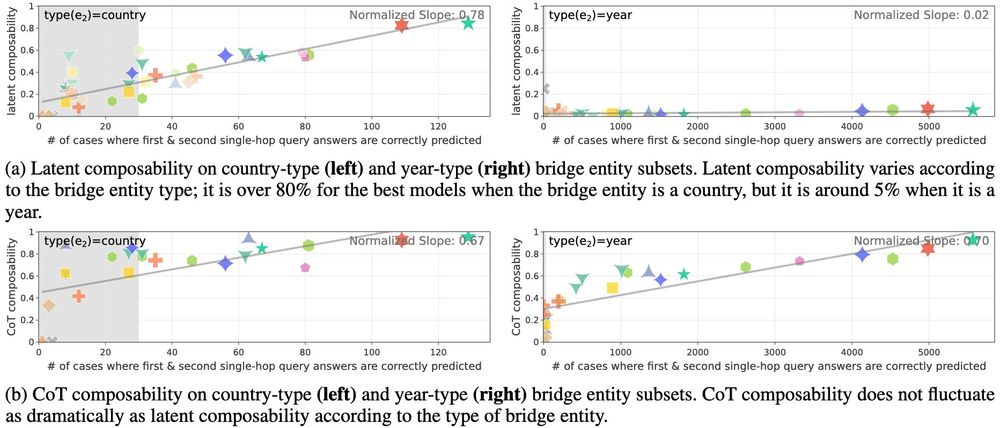
Results reveal striking differences across bridge entity types – 80%+ accuracy with countries vs ~6% with years. This variation vanishes with Chain-of-Thought (CoT) reasoning, suggesting different internal mechanisms. 7/N
November 27, 2024 at 5:26 PM
Results reveal striking differences across bridge entity types – 80%+ accuracy with countries vs ~6% with years. This variation vanishes with Chain-of-Thought (CoT) reasoning, suggesting different internal mechanisms. 7/N
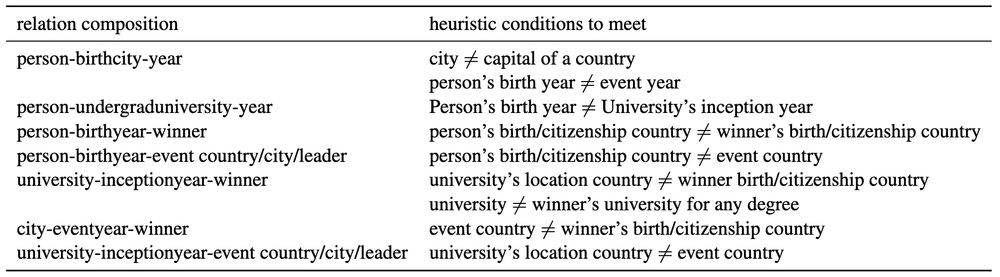
Our dataset also excludes facts where head/answer entities are directly connected or answers are guessable from part of the head entity. During evaluation, we filter cases where models are likely to be guessing the answer from relation patterns or perform explicit reasoning. 6/N
November 27, 2024 at 5:26 PM
Our dataset also excludes facts where head/answer entities are directly connected or answers are guessable from part of the head entity. During evaluation, we filter cases where models are likely to be guessing the answer from relation patterns or perform explicit reasoning. 6/N
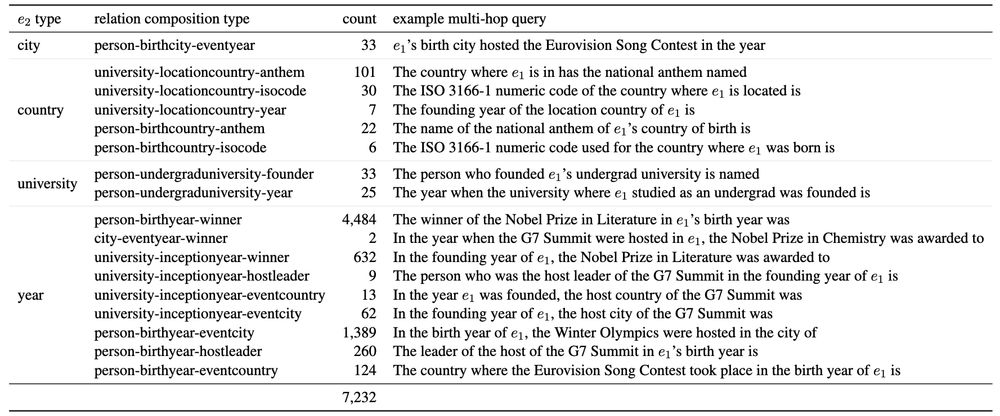
We introduce SOCRATES (ShOrtCut-fRee lATent rEaSoning), a dataset of 7K queries where head and answer entities have minimal chance of co-occurring in training data, which is carefully curated for shortcut-free evaluation of latent multi-hop reasoning. 4/N
November 27, 2024 at 5:26 PM
We introduce SOCRATES (ShOrtCut-fRee lATent rEaSoning), a dataset of 7K queries where head and answer entities have minimal chance of co-occurring in training data, which is carefully curated for shortcut-free evaluation of latent multi-hop reasoning. 4/N
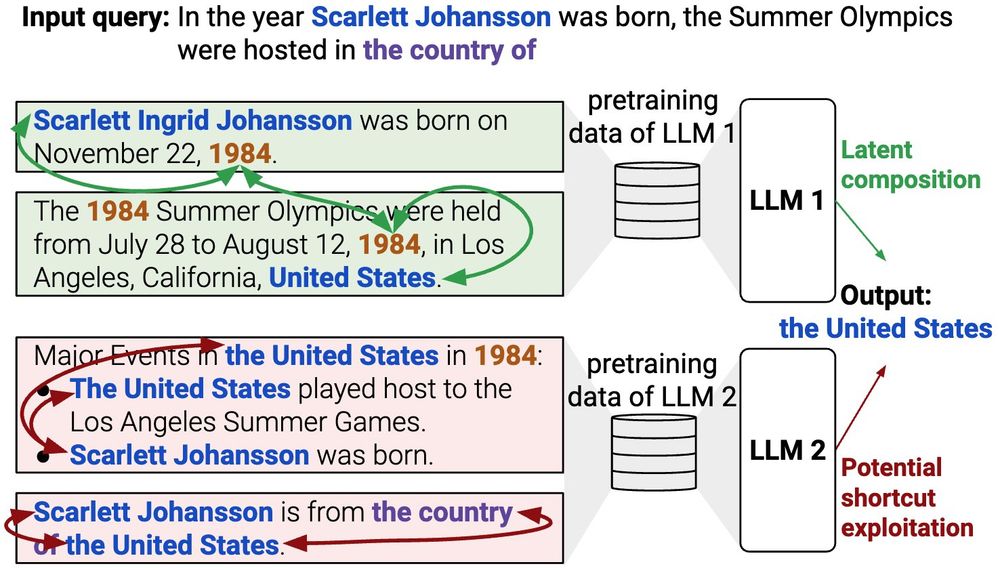
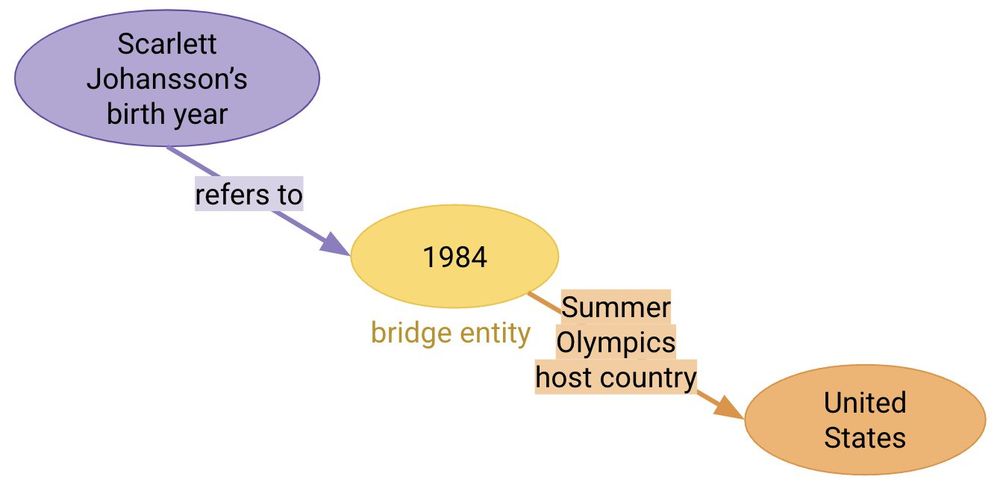
However, if models bypass true reasoning by exploiting shortcuts (e.g., seeing "Scarlett Johansson" with "United States" in training, or guessing the answer as "United States"), we can't accurately measure the ability. Previous works haven't adequately considered shortcuts. 3/N
November 27, 2024 at 5:26 PM
However, if models bypass true reasoning by exploiting shortcuts (e.g., seeing "Scarlett Johansson" with "United States" in training, or guessing the answer as "United States"), we can't accurately measure the ability. Previous works haven't adequately considered shortcuts. 3/N
Our study measures latent multi-hop reasoning ability of today's LLMs. Why? The ability can signal whether LLMs learn compressed representations of facts and can latently compose them. It has implications for knowledge localization, controllability, and editing capabilities. 2/N
November 27, 2024 at 5:26 PM
Our study measures latent multi-hop reasoning ability of today's LLMs. Why? The ability can signal whether LLMs learn compressed representations of facts and can latently compose them. It has implications for knowledge localization, controllability, and editing capabilities. 2/N
🚨 New Paper 🚨
Can LLMs perform latent multi-hop reasoning without exploiting shortcuts? We find the answer is yes – they can recall and compose facts not seen together in training or guessing the answer, but success greatly depends on the type of the bridge entity (80% for country, 6% for year)! 1/N
Can LLMs perform latent multi-hop reasoning without exploiting shortcuts? We find the answer is yes – they can recall and compose facts not seen together in training or guessing the answer, but success greatly depends on the type of the bridge entity (80% for country, 6% for year)! 1/N

November 27, 2024 at 5:26 PM
🚨 New Paper 🚨
Can LLMs perform latent multi-hop reasoning without exploiting shortcuts? We find the answer is yes – they can recall and compose facts not seen together in training or guessing the answer, but success greatly depends on the type of the bridge entity (80% for country, 6% for year)! 1/N
Can LLMs perform latent multi-hop reasoning without exploiting shortcuts? We find the answer is yes – they can recall and compose facts not seen together in training or guessing the answer, but success greatly depends on the type of the bridge entity (80% for country, 6% for year)! 1/N