




Snehal Raj
@snehalraj.bsky.social
PhD student at Sorbonne University
Assoc. Staff Scientist at QC Ware
www.snehalraj.com
Assoc. Staff Scientist at QC Ware
www.snehalraj.com
Check out the full paper for more details on the method, experimental setup, and analysis! arxiv.org/abs/2502.06916 We welcome your feedback and questions! Special mention to @brianc2095.bsky.social for his expert guidance and mentorship.

Hyper Compressed Fine-Tuning of Large Foundation Models with Quantum Inspired Adapters
Fine-tuning pre-trained large foundation models for specific tasks has become increasingly challenging due to the computational and storage demands associated with full parameter updates. Parameter-Ef...
arxiv.org
February 12, 2025 at 2:57 PM
Check out the full paper for more details on the method, experimental setup, and analysis! arxiv.org/abs/2502.06916 We welcome your feedback and questions! Special mention to @brianc2095.bsky.social for his expert guidance and mentorship.
Future directions include exploring more complex architectures, further optimising adapter design, and investigating potential quantum speedups for compound matrix operations.
February 12, 2025 at 2:57 PM
Future directions include exploring more complex architectures, further optimising adapter design, and investigating potential quantum speedups for compound matrix operations.
Our findings suggest Quantum-Inspired Adapters offer a promising direction for efficient adaptation of language and vision models in resource-constrained environments. The method's adaptability across different benchmarks underscores its generalisability.
February 12, 2025 at 2:57 PM
Our findings suggest Quantum-Inspired Adapters offer a promising direction for efficient adaptation of language and vision models in resource-constrained environments. The method's adaptability across different benchmarks underscores its generalisability.
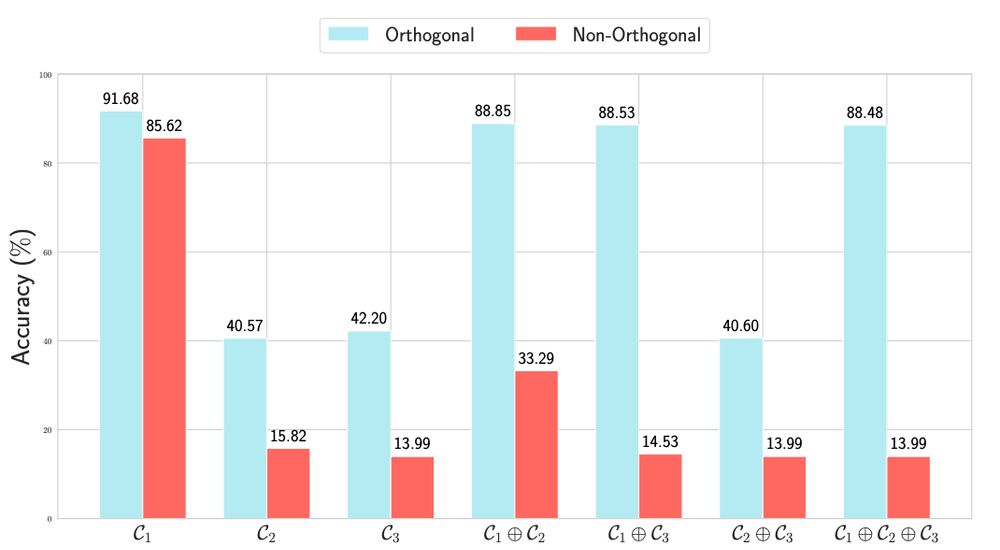
We found that combining multiple Hamming-weight orders with orthogonality and matrix compounding are essential for performant fine-tuning. Enforcing orthogonality is critical for the success of compound adapters.
February 12, 2025 at 2:57 PM
We found that combining multiple Hamming-weight orders with orthogonality and matrix compounding are essential for performant fine-tuning. Enforcing orthogonality is critical for the success of compound adapters.
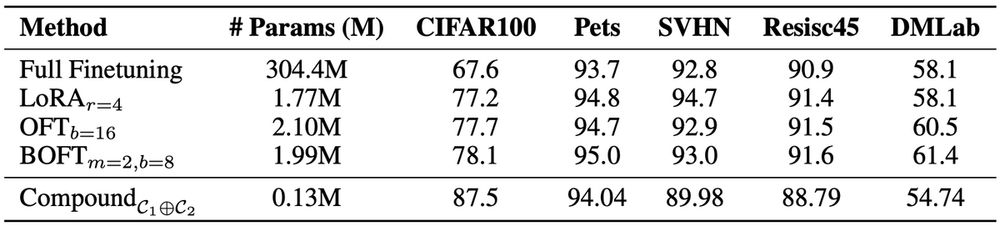
VTAB results are also promising! Our method achieves a comparable performance to LoRA with ≈ 13.6x fewer parameters. In some instances, such as CIFAR100, accuracy was significantly increased relative to other methods.
February 12, 2025 at 2:57 PM
VTAB results are also promising! Our method achieves a comparable performance to LoRA with ≈ 13.6x fewer parameters. In some instances, such as CIFAR100, accuracy was significantly increased relative to other methods.
On GLUE, we achieved 99.2% of LoRA's performance with a 44x parameter compression. Compared to OFT/BOFT, we achieved 98% relative performance with 25x fewer parameters.

February 12, 2025 at 2:57 PM
On GLUE, we achieved 99.2% of LoRA's performance with a 44x parameter compression. Compared to OFT/BOFT, we achieved 98% relative performance with 25x fewer parameters.
We tested our adapters on GLUE and VTAB benchmarks. Results show our method achieves competitive performance with significantly fewer trainable parameters compared to LoRA, OFT, and BOFT.
February 12, 2025 at 2:57 PM
We tested our adapters on GLUE and VTAB benchmarks. Results show our method achieves competitive performance with significantly fewer trainable parameters compared to LoRA, OFT, and BOFT.
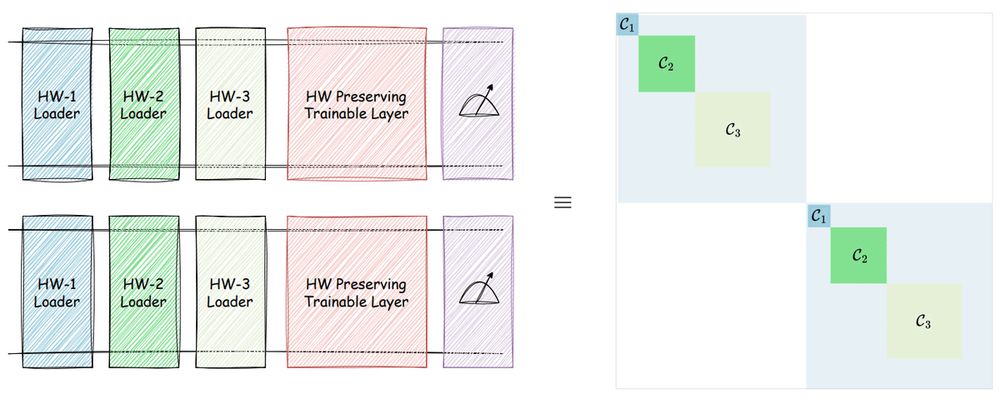
Our approach draws inspiration from Hamming-weight preserving quantum circuits to create parameter-efficient adapters that operate in a combinatorially large space while preserving orthogonality in weight parameters.
February 12, 2025 at 2:57 PM
Our approach draws inspiration from Hamming-weight preserving quantum circuits to create parameter-efficient adapters that operate in a combinatorially large space while preserving orthogonality in weight parameters.
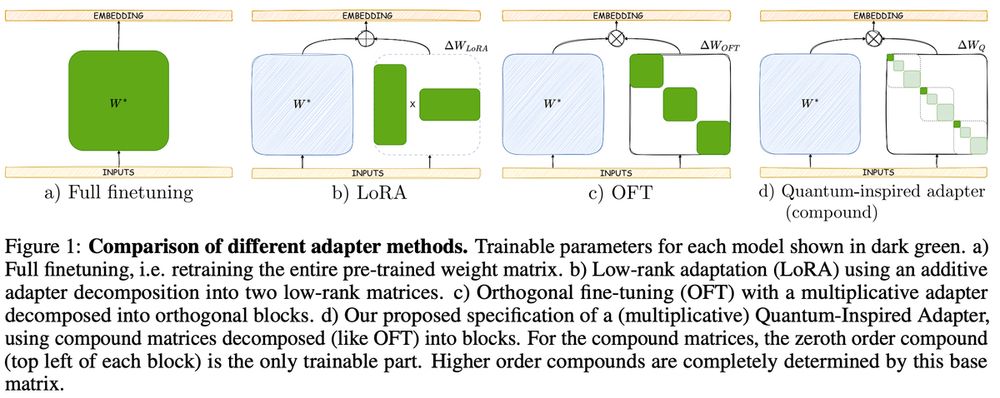
Fine-tuning large models is computationally expensive. This challenge has spurred interest in parameter efficient methods like LoRA which aim to adapt large foundation models to new tasks by updating only a small subset of parameters or introducing lightweight adaptation modules.
February 12, 2025 at 2:57 PM
Fine-tuning large models is computationally expensive. This challenge has spurred interest in parameter efficient methods like LoRA which aim to adapt large foundation models to new tasks by updating only a small subset of parameters or introducing lightweight adaptation modules.