




Snehal Raj
@snehalraj.bsky.social
PhD student at Sorbonne University
Assoc. Staff Scientist at QC Ware
www.snehalraj.com
Assoc. Staff Scientist at QC Ware
www.snehalraj.com
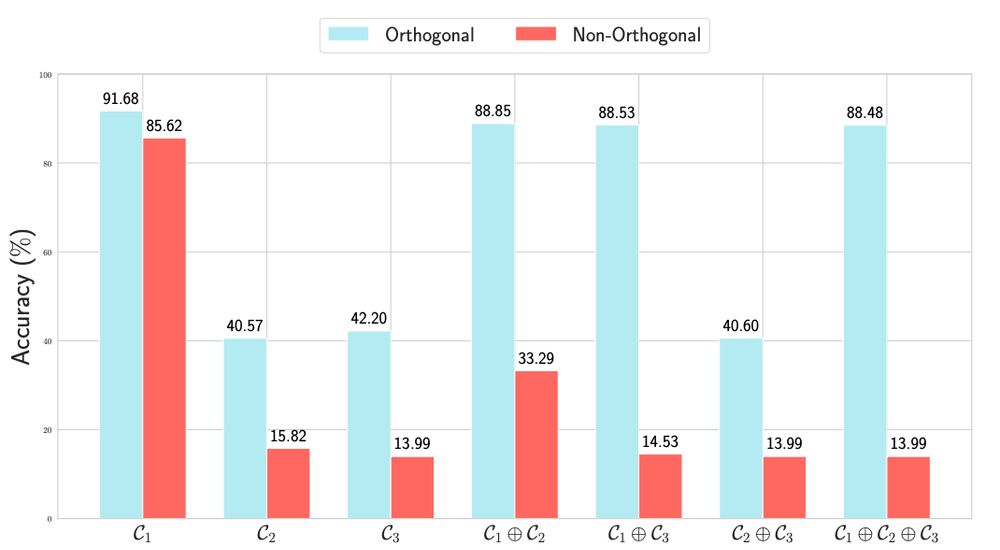
We found that combining multiple Hamming-weight orders with orthogonality and matrix compounding are essential for performant fine-tuning. Enforcing orthogonality is critical for the success of compound adapters.
February 12, 2025 at 2:57 PM
We found that combining multiple Hamming-weight orders with orthogonality and matrix compounding are essential for performant fine-tuning. Enforcing orthogonality is critical for the success of compound adapters.
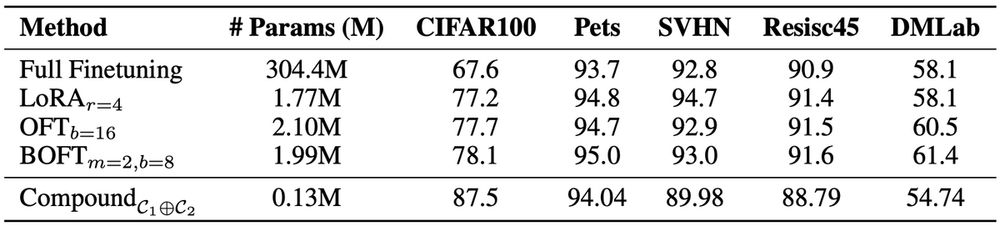
VTAB results are also promising! Our method achieves a comparable performance to LoRA with ≈ 13.6x fewer parameters. In some instances, such as CIFAR100, accuracy was significantly increased relative to other methods.
February 12, 2025 at 2:57 PM
VTAB results are also promising! Our method achieves a comparable performance to LoRA with ≈ 13.6x fewer parameters. In some instances, such as CIFAR100, accuracy was significantly increased relative to other methods.
On GLUE, we achieved 99.2% of LoRA's performance with a 44x parameter compression. Compared to OFT/BOFT, we achieved 98% relative performance with 25x fewer parameters.

February 12, 2025 at 2:57 PM
On GLUE, we achieved 99.2% of LoRA's performance with a 44x parameter compression. Compared to OFT/BOFT, we achieved 98% relative performance with 25x fewer parameters.
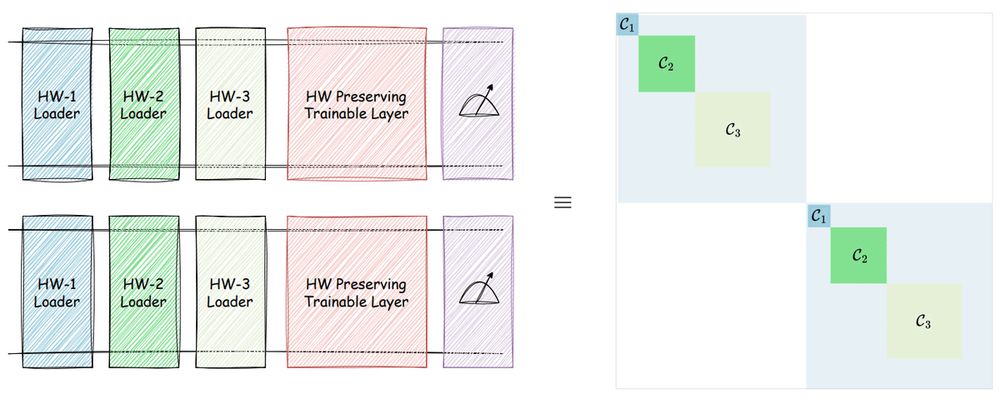
Our approach draws inspiration from Hamming-weight preserving quantum circuits to create parameter-efficient adapters that operate in a combinatorially large space while preserving orthogonality in weight parameters.
February 12, 2025 at 2:57 PM
Our approach draws inspiration from Hamming-weight preserving quantum circuits to create parameter-efficient adapters that operate in a combinatorially large space while preserving orthogonality in weight parameters.
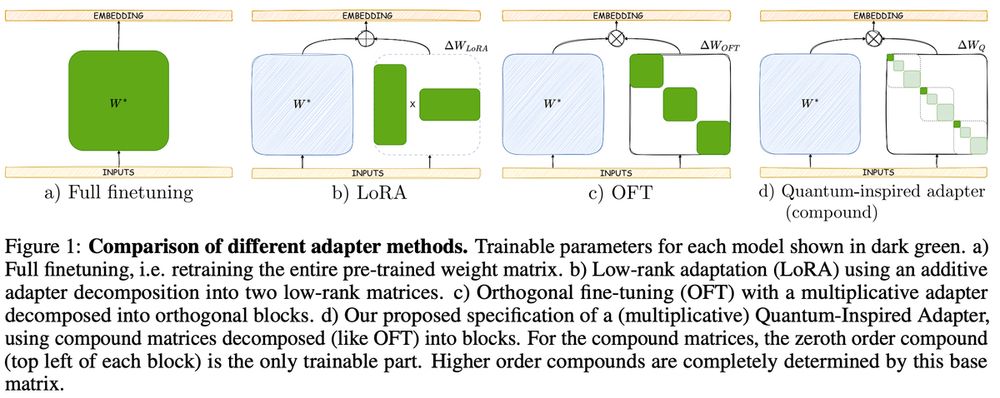
Fine-tuning large models is computationally expensive. This challenge has spurred interest in parameter efficient methods like LoRA which aim to adapt large foundation models to new tasks by updating only a small subset of parameters or introducing lightweight adaptation modules.
February 12, 2025 at 2:57 PM
Fine-tuning large models is computationally expensive. This challenge has spurred interest in parameter efficient methods like LoRA which aim to adapt large foundation models to new tasks by updating only a small subset of parameters or introducing lightweight adaptation modules.