




@sifal.bsky.social
Reposted

Ever looked at LLM skill emergence and thought 70B parameters was a magic number? Our new paper shows sudden breakthroughs are samples from bimodal performance distributions across seeds. Observed accuracy jumps abruptly while the underlying accuracy DISTRIBUTION changes slowly!

February 25, 2025 at 10:33 PM
Ever looked at LLM skill emergence and thought 70B parameters was a magic number? Our new paper shows sudden breakthroughs are samples from bimodal performance distributions across seeds. Observed accuracy jumps abruptly while the underlying accuracy DISTRIBUTION changes slowly!
Reposted

OpenAI releasing a model spec is one of my favorite things about them. All frontier labs should be doing this. Closes the gap between intentions and results, so you can interpret them better.
openai.com/index/sharin...
openai.com/index/sharin...

Sharing the latest Model Spec
We’ve made updates to the Model Spec based on external feedback and our continued research in shaping desired model behavior.
openai.com
February 12, 2025 at 10:39 PM
OpenAI releasing a model spec is one of my favorite things about them. All frontier labs should be doing this. Closes the gap between intentions and results, so you can interpret them better.
openai.com/index/sharin...
openai.com/index/sharin...
Reposted

Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
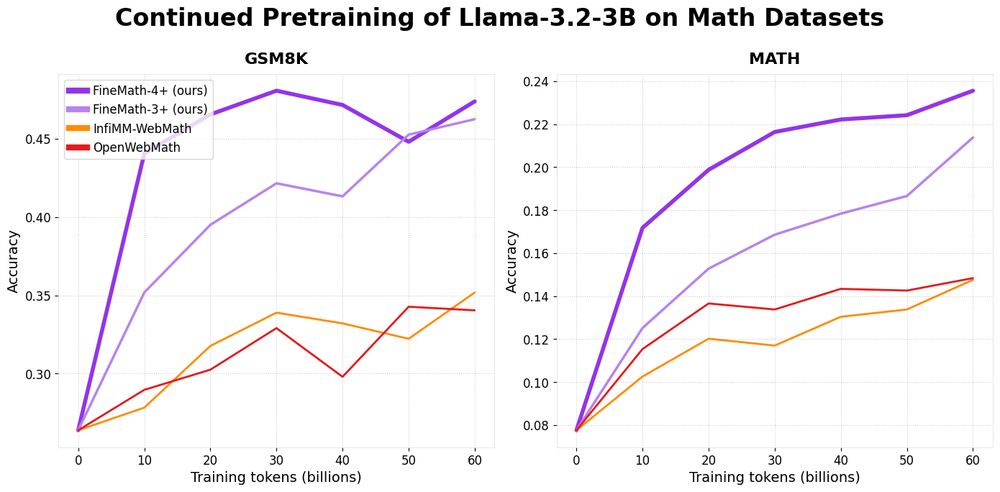
December 19, 2024 at 3:55 PM
Introducing 📐FineMath: the best open math pre-training dataset with 50B+ tokens!
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵
Math remains challenging for LLMs and by training on FineMath we see considerable gains over other math datasets, especially on GSM8K and MATH.
🤗 huggingface.co/datasets/Hug...
Here’s a breakdown 🧵