


Shrey Dixit
@shreydixit.bsky.social
Doctoral Researcher doing NeuroAI at the Max Planck Institute of Human Cognitive and Brain Sciences
Finally, huge thanks to the organizers for giving us this opportunity @algonautsproject.bsky.social
July 31, 2025 at 2:39 PM
Finally, huge thanks to the organizers for giving us this opportunity @algonautsproject.bsky.social
What's next? We plan to publish a more in-depth analysis of VIBE’s internal dynamics and feature–parcel mappings, to advance our understanding of brain function, and guide future work in neuroscience.
Spoiler: We already have a model that beats the top score of this challenge ;)
Spoiler: We already have a model that beats the top score of this challenge ;)
July 31, 2025 at 2:39 PM
What's next? We plan to publish a more in-depth analysis of VIBE’s internal dynamics and feature–parcel mappings, to advance our understanding of brain function, and guide future work in neuroscience.
Spoiler: We already have a model that beats the top score of this challenge ;)
Spoiler: We already have a model that beats the top score of this challenge ;)
Shapley (MSA) Insights:
Feature attribution maps align with neuroanatomy, but crazily enough, textual features from the transcripts are the most predictive of all.
Feature attribution maps align with neuroanatomy, but crazily enough, textual features from the transcripts are the most predictive of all.
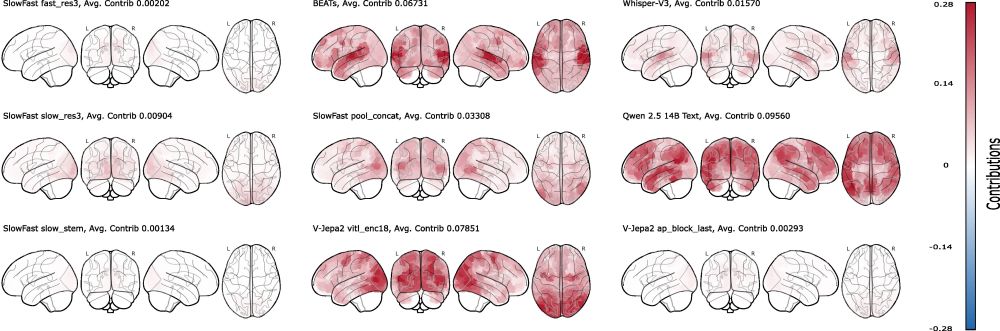
July 31, 2025 at 2:39 PM
Shapley (MSA) Insights:
Feature attribution maps align with neuroanatomy, but crazily enough, textual features from the transcripts are the most predictive of all.
Feature attribution maps align with neuroanatomy, but crazily enough, textual features from the transcripts are the most predictive of all.
We have strong lifts over baseline both in-distribution and OOD. VIBE (final): r=0.3225 (ID, Friends S07) & 0.2125 (6×OOD).
Competition submission (earlier iteration): r=0.3198 ID / 0.2096 OOD → 1st in Phase-1, 2nd overall.
vs baseline 0.2033/0.0895 → +0.119/+0.123.
Competition submission (earlier iteration): r=0.3198 ID / 0.2096 OOD → 1st in Phase-1, 2nd overall.
vs baseline 0.2033/0.0895 → +0.119/+0.123.

July 31, 2025 at 2:39 PM
We have strong lifts over baseline both in-distribution and OOD. VIBE (final): r=0.3225 (ID, Friends S07) & 0.2125 (6×OOD).
Competition submission (earlier iteration): r=0.3198 ID / 0.2096 OOD → 1st in Phase-1, 2nd overall.
vs baseline 0.2033/0.0895 → +0.119/+0.123.
Competition submission (earlier iteration): r=0.3198 ID / 0.2096 OOD → 1st in Phase-1, 2nd overall.
vs baseline 0.2033/0.0895 → +0.119/+0.123.
We present VIBE: Video-Input Brain Encoder, which is a 2-stage Transformer. First stage merges text, audio, and visual features per timepoint (plus subject embeddings). And the second stage models temporal dynamics with rotary positional embeddings.

July 31, 2025 at 2:39 PM
We present VIBE: Video-Input Brain Encoder, which is a 2-stage Transformer. First stage merges text, audio, and visual features per timepoint (plus subject embeddings). And the second stage models temporal dynamics with rotary positional embeddings.
Competition & Data: Algonauts 2025 tests how well we can predict brain activity while people watch naturalistic movies. Multi-modal stimuli (video, audio, text) → whole-brain fMRI, split into parcels. Train on movies/TV; evaluate in-distribution and on out-of-distribution films.

July 31, 2025 at 2:39 PM
Competition & Data: Algonauts 2025 tests how well we can predict brain activity while people watch naturalistic movies. Multi-modal stimuli (video, audio, text) → whole-brain fMRI, split into parcels. Train on movies/TV; evaluate in-distribution and on out-of-distribution films.
I personally prefer subway surfers. This one couldn't hold my attention for the whole video
July 29, 2025 at 5:15 PM
I personally prefer subway surfers. This one couldn't hold my attention for the whole video
Aside from a few mispronunciations, the AI really got the paper. Honestly, it's reassuring—if an AI can follow it without any mistakes, then folks in the field probably can too :)
July 24, 2025 at 3:26 AM
Aside from a few mispronunciations, the AI really got the paper. Honestly, it's reassuring—if an AI can follow it without any mistakes, then folks in the field probably can too :)
Not really. Thankfully, Max Planck has GPU clusters that I can use.
Although I did ask my friend (o3) about it, according to whom, 5090 is sufficient for most cases. (chatgpt.com/share/685c6a...)
Although I did ask my friend (o3) about it, according to whom, 5090 is sufficient for most cases. (chatgpt.com/share/685c6a...)

ChatGPT - RTX 5000 vs 5090 for ML
Shared via ChatGPT
chatgpt.com
June 25, 2025 at 9:34 PM
Not really. Thankfully, Max Planck has GPU clusters that I can use.
Although I did ask my friend (o3) about it, according to whom, 5090 is sufficient for most cases. (chatgpt.com/share/685c6a...)
Although I did ask my friend (o3) about it, according to whom, 5090 is sufficient for most cases. (chatgpt.com/share/685c6a...)