


Shrey Dixit
@shreydixit.bsky.social
Doctoral Researcher doing NeuroAI at the Max Planck Institute of Human Cognitive and Brain Sciences
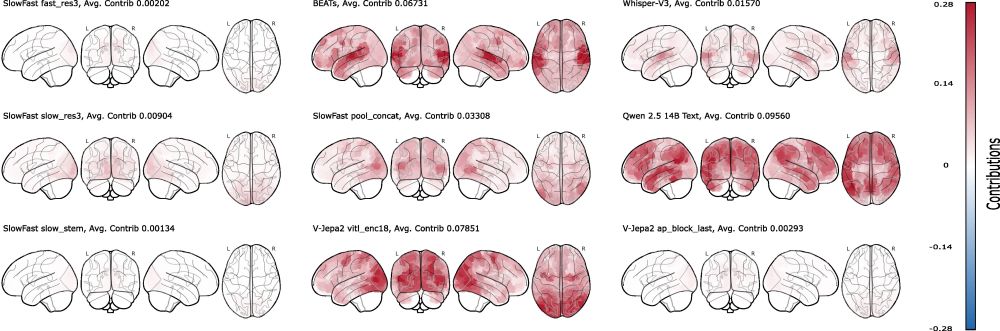
Shapley (MSA) Insights:
Feature attribution maps align with neuroanatomy, but crazily enough, textual features from the transcripts are the most predictive of all.
Feature attribution maps align with neuroanatomy, but crazily enough, textual features from the transcripts are the most predictive of all.
July 31, 2025 at 2:39 PM
Shapley (MSA) Insights:
Feature attribution maps align with neuroanatomy, but crazily enough, textual features from the transcripts are the most predictive of all.
Feature attribution maps align with neuroanatomy, but crazily enough, textual features from the transcripts are the most predictive of all.
We have strong lifts over baseline both in-distribution and OOD. VIBE (final): r=0.3225 (ID, Friends S07) & 0.2125 (6×OOD).
Competition submission (earlier iteration): r=0.3198 ID / 0.2096 OOD → 1st in Phase-1, 2nd overall.
vs baseline 0.2033/0.0895 → +0.119/+0.123.
Competition submission (earlier iteration): r=0.3198 ID / 0.2096 OOD → 1st in Phase-1, 2nd overall.
vs baseline 0.2033/0.0895 → +0.119/+0.123.

July 31, 2025 at 2:39 PM
We have strong lifts over baseline both in-distribution and OOD. VIBE (final): r=0.3225 (ID, Friends S07) & 0.2125 (6×OOD).
Competition submission (earlier iteration): r=0.3198 ID / 0.2096 OOD → 1st in Phase-1, 2nd overall.
vs baseline 0.2033/0.0895 → +0.119/+0.123.
Competition submission (earlier iteration): r=0.3198 ID / 0.2096 OOD → 1st in Phase-1, 2nd overall.
vs baseline 0.2033/0.0895 → +0.119/+0.123.
We present VIBE: Video-Input Brain Encoder, which is a 2-stage Transformer. First stage merges text, audio, and visual features per timepoint (plus subject embeddings). And the second stage models temporal dynamics with rotary positional embeddings.

July 31, 2025 at 2:39 PM
We present VIBE: Video-Input Brain Encoder, which is a 2-stage Transformer. First stage merges text, audio, and visual features per timepoint (plus subject embeddings). And the second stage models temporal dynamics with rotary positional embeddings.
Competition & Data: Algonauts 2025 tests how well we can predict brain activity while people watch naturalistic movies. Multi-modal stimuli (video, audio, text) → whole-brain fMRI, split into parcels. Train on movies/TV; evaluate in-distribution and on out-of-distribution films.

July 31, 2025 at 2:39 PM
Competition & Data: Algonauts 2025 tests how well we can predict brain activity while people watch naturalistic movies. Multi-modal stimuli (video, audio, text) → whole-brain fMRI, split into parcels. Train on movies/TV; evaluate in-distribution and on out-of-distribution films.
We did it! 🏆 We won Phase 1 and placed 2nd overall in the Algonauts 2025 Challenge. So proud of the crew
@keckjanis.bsky.social,Viktor Studenyak,Daniel Schad,Aleksandr Shpilevoi. Huge thanks to @andrejbicanski.bsky.social and @doellerlab.bsky.social for support. Report: arxiv.org/abs/2507.17958
@keckjanis.bsky.social,Viktor Studenyak,Daniel Schad,Aleksandr Shpilevoi. Huge thanks to @andrejbicanski.bsky.social and @doellerlab.bsky.social for support. Report: arxiv.org/abs/2507.17958

July 31, 2025 at 2:39 PM
We did it! 🏆 We won Phase 1 and placed 2nd overall in the Algonauts 2025 Challenge. So proud of the crew
@keckjanis.bsky.social,Viktor Studenyak,Daniel Schad,Aleksandr Shpilevoi. Huge thanks to @andrejbicanski.bsky.social and @doellerlab.bsky.social for support. Report: arxiv.org/abs/2507.17958
@keckjanis.bsky.social,Viktor Studenyak,Daniel Schad,Aleksandr Shpilevoi. Huge thanks to @andrejbicanski.bsky.social and @doellerlab.bsky.social for support. Report: arxiv.org/abs/2507.17958
DCGAN Case Study:
Pixel-wise Shapley Modes reveal the inverted CNN hierarchy: first transposed-conv layer shapes high-level facial parts; final layer merely renders RGB channels.
Pixel-wise Shapley Modes reveal the inverted CNN hierarchy: first transposed-conv layer shapes high-level facial parts; final layer merely renders RGB channels.

June 25, 2025 at 9:18 AM
DCGAN Case Study:
Pixel-wise Shapley Modes reveal the inverted CNN hierarchy: first transposed-conv layer shapes high-level facial parts; final layer merely renders RGB channels.
Pixel-wise Shapley Modes reveal the inverted CNN hierarchy: first transposed-conv layer shapes high-level facial parts; final layer merely renders RGB channels.
LLM Case Study:
Calculated expert-level contributions of an MOE-based LLM across arithmetic, language ID, and factual recall. Found an expert which was super-important for all domains. Also found redundant experts, removing which does not decrease performance much.
Calculated expert-level contributions of an MOE-based LLM across arithmetic, language ID, and factual recall. Found an expert which was super-important for all domains. Also found redundant experts, removing which does not decrease performance much.

June 25, 2025 at 9:18 AM
LLM Case Study:
Calculated expert-level contributions of an MOE-based LLM across arithmetic, language ID, and factual recall. Found an expert which was super-important for all domains. Also found redundant experts, removing which does not decrease performance much.
Calculated expert-level contributions of an MOE-based LLM across arithmetic, language ID, and factual recall. Found an expert which was super-important for all domains. Also found redundant experts, removing which does not decrease performance much.
MLP Case Study:
Neural computations within a three-layer MNIST MLP were analysed. L1/L2 regularisation funnels computations into a few neurons. Also, contrary to popular belief, large weights do not equal high importance of neural units.
Neural computations within a three-layer MNIST MLP were analysed. L1/L2 regularisation funnels computations into a few neurons. Also, contrary to popular belief, large weights do not equal high importance of neural units.

June 25, 2025 at 9:18 AM
MLP Case Study:
Neural computations within a three-layer MNIST MLP were analysed. L1/L2 regularisation funnels computations into a few neurons. Also, contrary to popular belief, large weights do not equal high importance of neural units.
Neural computations within a three-layer MNIST MLP were analysed. L1/L2 regularisation funnels computations into a few neurons. Also, contrary to popular belief, large weights do not equal high importance of neural units.