




Shangshang Wang
@shangshang-wang.bsky.social
https://shangshang-wang.github.io/
Phd student in CS + AI @usc.edu. CS undergrad, master at ShanghaiTech. LLM reasoning, RL, AI4Science.
Phd student in CS + AI @usc.edu. CS undergrad, master at ShanghaiTech. LLM reasoning, RL, AI4Science.
Curious about the details for these efficiency claims?
We open-source everything for full reproducibility:
Paper: arxiv.org/abs/2506.09967
Blog: shangshangwang.notion.site/resa
Code: github.com/shangshang-w...
Model: huggingface.co/Resa-Yi
Training Logs: wandb.ai/upup-ashton-...
We open-source everything for full reproducibility:
Paper: arxiv.org/abs/2506.09967
Blog: shangshangwang.notion.site/resa
Code: github.com/shangshang-w...
Model: huggingface.co/Resa-Yi
Training Logs: wandb.ai/upup-ashton-...
June 12, 2025 at 5:02 PM
Curious about the details for these efficiency claims?
We open-source everything for full reproducibility:
Paper: arxiv.org/abs/2506.09967
Blog: shangshangwang.notion.site/resa
Code: github.com/shangshang-w...
Model: huggingface.co/Resa-Yi
Training Logs: wandb.ai/upup-ashton-...
We open-source everything for full reproducibility:
Paper: arxiv.org/abs/2506.09967
Blog: shangshangwang.notion.site/resa
Code: github.com/shangshang-w...
Model: huggingface.co/Resa-Yi
Training Logs: wandb.ai/upup-ashton-...
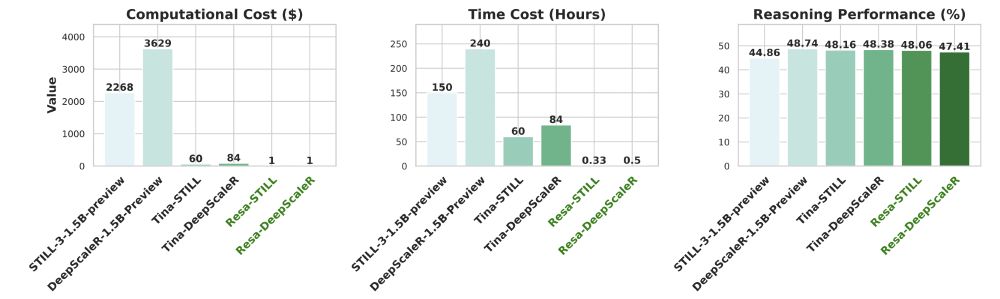
SAE-Tuning trains models that match RL-trained counterparts’ performance while reducing costs by >2000x and time by >450x.
The trained model is transparent, revealing where reasoning abilities hide, also generalizable and modular, enabling transfer across datasets and models.
The trained model is transparent, revealing where reasoning abilities hide, also generalizable and modular, enabling transfer across datasets and models.
June 12, 2025 at 5:02 PM
SAE-Tuning trains models that match RL-trained counterparts’ performance while reducing costs by >2000x and time by >450x.
The trained model is transparent, revealing where reasoning abilities hide, also generalizable and modular, enabling transfer across datasets and models.
The trained model is transparent, revealing where reasoning abilities hide, also generalizable and modular, enabling transfer across datasets and models.
Such efficiency stems from our novel SAE-Tuning method, which expands the use of SAEs beyond test-time steering.
In SAE-Tuning, the SAE first “extracts” latent reasoning features and then guides a standard supervised fine-tuning process to “elicit” reasoning abilities.
In SAE-Tuning, the SAE first “extracts” latent reasoning features and then guides a standard supervised fine-tuning process to “elicit” reasoning abilities.

June 12, 2025 at 5:02 PM
Such efficiency stems from our novel SAE-Tuning method, which expands the use of SAEs beyond test-time steering.
In SAE-Tuning, the SAE first “extracts” latent reasoning features and then guides a standard supervised fine-tuning process to “elicit” reasoning abilities.
In SAE-Tuning, the SAE first “extracts” latent reasoning features and then guides a standard supervised fine-tuning process to “elicit” reasoning abilities.
Check out more about Tina following the links down below.
Paper: arxiv.org/abs/2504.15777
Notion Blog: shangshangwang.notion.site/tina
Code: github.com/shangshang-w...
Model: huggingface.co/Tina-Yi
Training Logs: wandb.ai/upup-ashton-...
Tina's avatar is generated by GPT-4o based on KYNE's girls.
Paper: arxiv.org/abs/2504.15777
Notion Blog: shangshangwang.notion.site/tina
Code: github.com/shangshang-w...
Model: huggingface.co/Tina-Yi
Training Logs: wandb.ai/upup-ashton-...
Tina's avatar is generated by GPT-4o based on KYNE's girls.

April 23, 2025 at 5:10 PM
Check out more about Tina following the links down below.
Paper: arxiv.org/abs/2504.15777
Notion Blog: shangshangwang.notion.site/tina
Code: github.com/shangshang-w...
Model: huggingface.co/Tina-Yi
Training Logs: wandb.ai/upup-ashton-...
Tina's avatar is generated by GPT-4o based on KYNE's girls.
Paper: arxiv.org/abs/2504.15777
Notion Blog: shangshangwang.notion.site/tina
Code: github.com/shangshang-w...
Model: huggingface.co/Tina-Yi
Training Logs: wandb.ai/upup-ashton-...
Tina's avatar is generated by GPT-4o based on KYNE's girls.
We also want to express our gratitude to the broader open-source community. This research was made possible by leveraging numerous publicly available resources from DeepScaleR, STILL, OpenThoughts @bespokelabs.bsky.social , OpenR1 @hf.co , LIMR, and OpenRS.
April 23, 2025 at 5:10 PM
We also want to express our gratitude to the broader open-source community. This research was made possible by leveraging numerous publicly available resources from DeepScaleR, STILL, OpenThoughts @bespokelabs.bsky.social , OpenR1 @hf.co , LIMR, and OpenRS.
This is an amazing collaboration with Julian, Omer, Enes, and Oliver @oliu-io.bsky.social in the course taught by Willie @willieneis.bsky.social (both the teacher and the advisor) Thanks everyone!
April 23, 2025 at 5:10 PM
This is an amazing collaboration with Julian, Omer, Enes, and Oliver @oliu-io.bsky.social in the course taught by Willie @willieneis.bsky.social (both the teacher and the advisor) Thanks everyone!
[9/9] 🚀 We thus hypothesize that LoRA’s effectiveness and efficiency stem from rapidly adapting the reasoning format under RL while preserving base model knowledge, a likely more compute-efficient process than the deep knowledge integration of full-parameter training.
April 23, 2025 at 5:10 PM
[9/9] 🚀 We thus hypothesize that LoRA’s effectiveness and efficiency stem from rapidly adapting the reasoning format under RL while preserving base model knowledge, a likely more compute-efficient process than the deep knowledge integration of full-parameter training.
[8/9] 💡 Observation 2) We consistently observe a training phase transition in the format-related metrics (format reward, completion length) but NOT accuracy-related metrics across most Tina models. And the best-performance checkpoint is always found around this transition point.

April 23, 2025 at 5:10 PM
[8/9] 💡 Observation 2) We consistently observe a training phase transition in the format-related metrics (format reward, completion length) but NOT accuracy-related metrics across most Tina models. And the best-performance checkpoint is always found around this transition point.
[7/9] 💡 Observation 1) We observe that in Tina models, increased training compute inversely affects performance, in contrast to full-parameter models. This observation highlights a “less compute can yield more performance” phenomenon.

April 23, 2025 at 5:10 PM
[7/9] 💡 Observation 1) We observe that in Tina models, increased training compute inversely affects performance, in contrast to full-parameter models. This observation highlights a “less compute can yield more performance” phenomenon.
🤔 But why? Where does this effectiveness and efficiency come from?
💡 We further provide insights based on our observations during post-training Tina models.
💡 We further provide insights based on our observations during post-training Tina models.
April 23, 2025 at 5:10 PM
🤔 But why? Where does this effectiveness and efficiency come from?
💡 We further provide insights based on our observations during post-training Tina models.
💡 We further provide insights based on our observations during post-training Tina models.
[6/9] 😋 And, it costs only $9 to reproduce the best Tina checkpoint, $526 to reproduce all our experiments from scratch!

April 23, 2025 at 5:10 PM
[6/9] 😋 And, it costs only $9 to reproduce the best Tina checkpoint, $526 to reproduce all our experiments from scratch!
[5/9] 🤩 We validate this across multiple open-source reasoning datasets and various ablation settings with a single, fixed set of hyperparameters, confirming the effectiveness and efficiency of LoRA-based RL.

April 23, 2025 at 5:10 PM
[5/9] 🤩 We validate this across multiple open-source reasoning datasets and various ablation settings with a single, fixed set of hyperparameters, confirming the effectiveness and efficiency of LoRA-based RL.
[4/9] 😍 With minimal post-training compute, the best Tina checkpoint achieves >20% performance increase over the base model and 43% Pass@1 on AIME24.

April 23, 2025 at 5:10 PM
[4/9] 😍 With minimal post-training compute, the best Tina checkpoint achieves >20% performance increase over the base model and 43% Pass@1 on AIME24.
[3/9] 🚀 Our Tina models compete with, and sometimes surpass, SOTA models built on the same base model with a surprising high cost efficiency.

April 23, 2025 at 5:10 PM
[3/9] 🚀 Our Tina models compete with, and sometimes surpass, SOTA models built on the same base model with a surprising high cost efficiency.
[2/9] 👩 We release the Tina family of models, created by post-training the DeepSeek-R1-Distill-Qwen-1.5B base model using low-rank adaptation (LoRA) during reinforcement learning (RL), on open-source reasoning datasets.
April 23, 2025 at 5:10 PM
[2/9] 👩 We release the Tina family of models, created by post-training the DeepSeek-R1-Distill-Qwen-1.5B base model using low-rank adaptation (LoRA) during reinforcement learning (RL), on open-source reasoning datasets.
Click on the link/card below to see the full set of spreadsheets:
shangshangwang.notion.site/llm-reasoning
shangshangwang.notion.site/llm-reasoning

LLM Reasoning: Curated Insights
Reasoning ability is gained via post-training and is scaled via test-time compute.
shangshangwang.notion.site
February 19, 2025 at 6:01 PM
Click on the link/card below to see the full set of spreadsheets:
shangshangwang.notion.site/llm-reasoning
shangshangwang.notion.site/llm-reasoning
6/6 This is an ongoing collection of LLM reasoning. Please feel free to send new materials or any feedback here or via the google form.
docs.google.com/forms/d/e/1F...
docs.google.com/forms/d/e/1F...

Feedback on "LLM Reasoning: Curated Insights"
docs.google.com
February 19, 2025 at 6:01 PM
6/6 This is an ongoing collection of LLM reasoning. Please feel free to send new materials or any feedback here or via the google form.
docs.google.com/forms/d/e/1F...
docs.google.com/forms/d/e/1F...
5/6 Others Artifacts
We then collect survey, evaluation, benchmark and application papers and also online resources like blogs, posts, videos, code, and data.
We then collect survey, evaluation, benchmark and application papers and also online resources like blogs, posts, videos, code, and data.


February 19, 2025 at 6:01 PM
5/6 Others Artifacts
We then collect survey, evaluation, benchmark and application papers and also online resources like blogs, posts, videos, code, and data.
We then collect survey, evaluation, benchmark and application papers and also online resources like blogs, posts, videos, code, and data.
4/6 Verification, The Key to Reasoning
Verifiers serve as a key component in both post-training (e.g., as reward models) and test-time compute (e.g., as signals to guide search). Our fourth section collects thoughts on various verification.
Verifiers serve as a key component in both post-training (e.g., as reward models) and test-time compute (e.g., as signals to guide search). Our fourth section collects thoughts on various verification.

February 19, 2025 at 6:01 PM
4/6 Verification, The Key to Reasoning
Verifiers serve as a key component in both post-training (e.g., as reward models) and test-time compute (e.g., as signals to guide search). Our fourth section collects thoughts on various verification.
Verifiers serve as a key component in both post-training (e.g., as reward models) and test-time compute (e.g., as signals to guide search). Our fourth section collects thoughts on various verification.
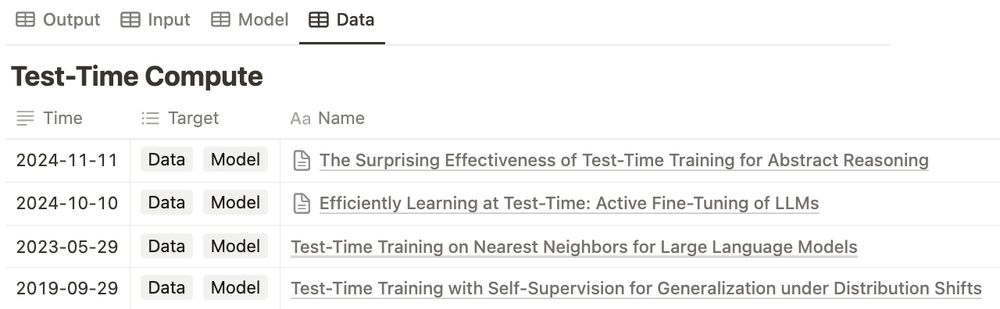
3/6 Test-Time Compute: Scaling Reasoning Ability
Test-time compute is an emerging field where folks are trying different methods (e.g., search) and using extra components (e.g., verifiers). Our third section classifies them based on the optimization targets for LLMs.
Test-time compute is an emerging field where folks are trying different methods (e.g., search) and using extra components (e.g., verifiers). Our third section classifies them based on the optimization targets for LLMs.



February 19, 2025 at 6:01 PM
3/6 Test-Time Compute: Scaling Reasoning Ability
Test-time compute is an emerging field where folks are trying different methods (e.g., search) and using extra components (e.g., verifiers). Our third section classifies them based on the optimization targets for LLMs.
Test-time compute is an emerging field where folks are trying different methods (e.g., search) and using extra components (e.g., verifiers). Our third section classifies them based on the optimization targets for LLMs.
2/6 Post-Training: Gain Reasoning Ability
Our second section collects thoughts on post-training methods for LLM reasoning including the hot RL-based and also SFT-based methods.
Our second section collects thoughts on post-training methods for LLM reasoning including the hot RL-based and also SFT-based methods.


February 19, 2025 at 6:01 PM
2/6 Post-Training: Gain Reasoning Ability
Our second section collects thoughts on post-training methods for LLM reasoning including the hot RL-based and also SFT-based methods.
Our second section collects thoughts on post-training methods for LLM reasoning including the hot RL-based and also SFT-based methods.
1/6 OpenAI, DeepSeek and More
The discussion on reasoning ability started to go viral with the release of OpenAI o-series and DeepSeek R1 models. Our first section collects thoughts on OpenAI o-series and DeepSeek R1 models and other SOTA reasoning models.
The discussion on reasoning ability started to go viral with the release of OpenAI o-series and DeepSeek R1 models. Our first section collects thoughts on OpenAI o-series and DeepSeek R1 models and other SOTA reasoning models.



February 19, 2025 at 6:01 PM
1/6 OpenAI, DeepSeek and More
The discussion on reasoning ability started to go viral with the release of OpenAI o-series and DeepSeek R1 models. Our first section collects thoughts on OpenAI o-series and DeepSeek R1 models and other SOTA reasoning models.
The discussion on reasoning ability started to go viral with the release of OpenAI o-series and DeepSeek R1 models. Our first section collects thoughts on OpenAI o-series and DeepSeek R1 models and other SOTA reasoning models.
Click on the link/card below to see the full set of spreadsheets, and check out the thread below for an overview of each section:
shangshangwang.notion.site/llm-reasoning
shangshangwang.notion.site/llm-reasoning
LLM Reasoning: Curated Insights
Reasoning ability is gained via post-training and is scaled via test-time compute.
shangshangwang.notion.site
February 19, 2025 at 6:01 PM
Click on the link/card below to see the full set of spreadsheets, and check out the thread below for an overview of each section:
shangshangwang.notion.site/llm-reasoning
shangshangwang.notion.site/llm-reasoning