



Sham Kakade
@shamkakade.bsky.social
(3/n) 📊 From our controlled experiments on language models:
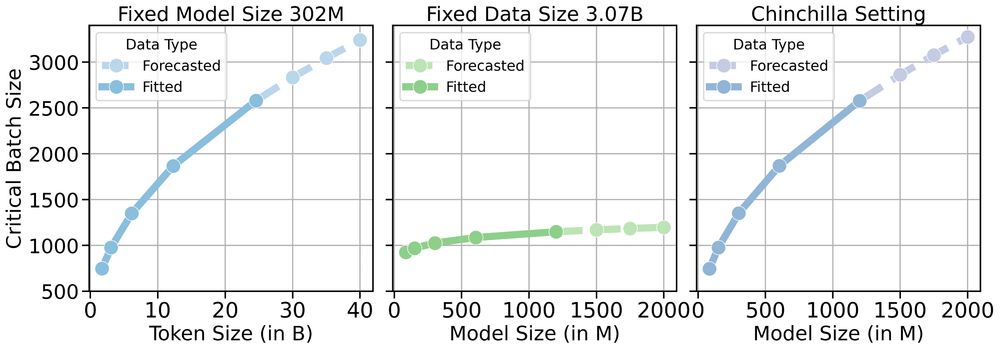
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.
November 22, 2024 at 8:19 PM
(3/n) 📊 From our controlled experiments on language models:
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.
📈CBS increases as dataset size grows
🤏CBS remains weakly dependent on model size
Data size, not model size, drives parallel efficiency for large-scale pre-training.
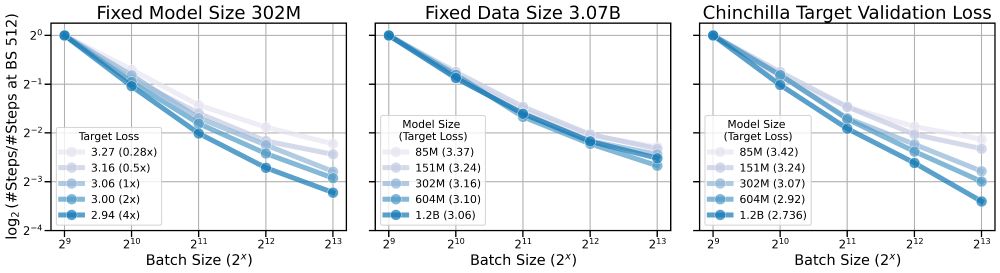
(2/n) 🤔 How does CBS scale with model size and data size in pre-training? We find that CBS scales with data size and is largely invariant to model size. Prior beliefs that CBS scales with model size may have stemmed from Chinchilla’s coupled N-D scaling.
November 22, 2024 at 8:19 PM
(2/n) 🤔 How does CBS scale with model size and data size in pre-training? We find that CBS scales with data size and is largely invariant to model size. Prior beliefs that CBS scales with model size may have stemmed from Chinchilla’s coupled N-D scaling.
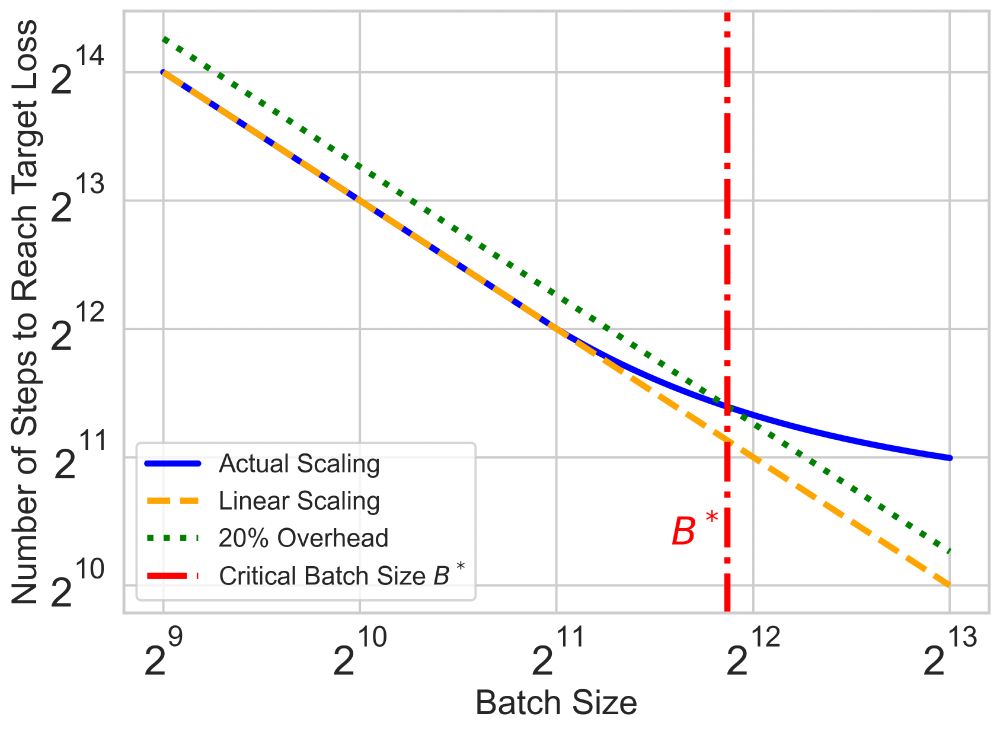
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
November 22, 2024 at 8:19 PM
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.