




Sebastian Schuster
@sebschu.bsky.social
Computational semantics and pragmatics, interpretability and occasionally some psycholinguistics. he/him. 🦝
https://sebschu.com
https://sebschu.com
Dinosaur GIF for completeness. /fin

a toy dinosaur from the movie toy story is walking on a white surface .
ALT: a toy dinosaur from the movie toy story is walking on a white surface .
media.tenor.com
July 2, 2025 at 3:40 PM
Dinosaur GIF for completeness. /fin
This work was done by our amazing team: @nedwards99.bsky.social, @yukyunglee.bsky.social, Yujun (Audrey) Mao, and Yulu Qin. And as always, it was super fun co-directing this with @najoung.bsky.social. We also thank Max Nadeau and Ajeya Cotra for initial advice and support.
July 2, 2025 at 3:40 PM
This work was done by our amazing team: @nedwards99.bsky.social, @yukyunglee.bsky.social, Yujun (Audrey) Mao, and Yulu Qin. And as always, it was super fun co-directing this with @najoung.bsky.social. We also thank Max Nadeau and Ajeya Cotra for initial advice and support.
Think your agent can do better? Check out the paper, download the data, and submit your agent to our leaderboard:
🌐Website: rexbench.com
📄Paper: arxiv.org/abs/2506.22598
🌐Website: rexbench.com
📄Paper: arxiv.org/abs/2506.22598
RExBench: A benchmark of machine learning research extensions for evaluating coding agents
rexbench.com
July 2, 2025 at 3:40 PM
Think your agent can do better? Check out the paper, download the data, and submit your agent to our leaderboard:
🌐Website: rexbench.com
📄Paper: arxiv.org/abs/2506.22598
🌐Website: rexbench.com
📄Paper: arxiv.org/abs/2506.22598
We note that the current set of RexBench tasks is NOT extremely challenging for a PhD student-level domain expert. We hope to release a more challenging set of tasks in the near future, and would be excited about community contributions, so please reach out if you are interested! 🫵
July 2, 2025 at 3:40 PM
We note that the current set of RexBench tasks is NOT extremely challenging for a PhD student-level domain expert. We hope to release a more challenging set of tasks in the near future, and would be excited about community contributions, so please reach out if you are interested! 🫵
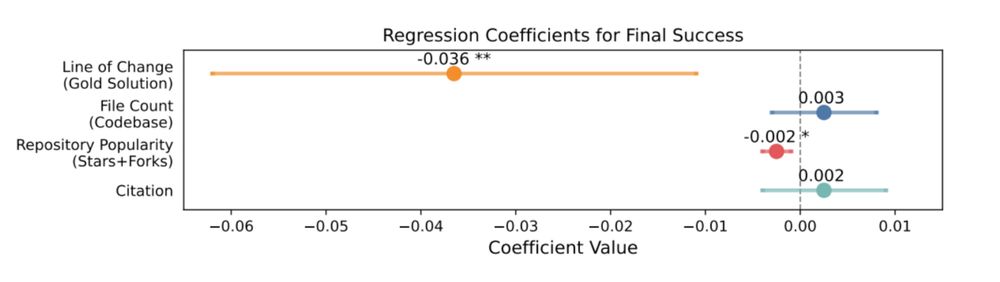
What makes an extension difficult for agents?
Statistically, tasks with more lines of change in the gold solution were harder. Meanwhile, repo size and popularity had marginal effects. Qualitatively, the performance aligned poorly with human-expert perceived difficulty!
Statistically, tasks with more lines of change in the gold solution were harder. Meanwhile, repo size and popularity had marginal effects. Qualitatively, the performance aligned poorly with human-expert perceived difficulty!
July 2, 2025 at 3:40 PM
What makes an extension difficult for agents?
Statistically, tasks with more lines of change in the gold solution were harder. Meanwhile, repo size and popularity had marginal effects. Qualitatively, the performance aligned poorly with human-expert perceived difficulty!
Statistically, tasks with more lines of change in the gold solution were harder. Meanwhile, repo size and popularity had marginal effects. Qualitatively, the performance aligned poorly with human-expert perceived difficulty!
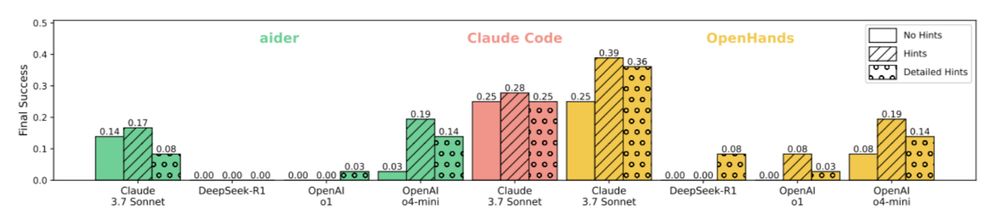
What if we give them hints?
We provided two levels of human-written hints. L1: information localization (e.g., files to edit) & L2: step-by-step guidance. With hints, the best agent’s performance improves to 39%, showing that substantial human guidance is still needed.
We provided two levels of human-written hints. L1: information localization (e.g., files to edit) & L2: step-by-step guidance. With hints, the best agent’s performance improves to 39%, showing that substantial human guidance is still needed.
July 2, 2025 at 3:40 PM
What if we give them hints?
We provided two levels of human-written hints. L1: information localization (e.g., files to edit) & L2: step-by-step guidance. With hints, the best agent’s performance improves to 39%, showing that substantial human guidance is still needed.
We provided two levels of human-written hints. L1: information localization (e.g., files to edit) & L2: step-by-step guidance. With hints, the best agent’s performance improves to 39%, showing that substantial human guidance is still needed.
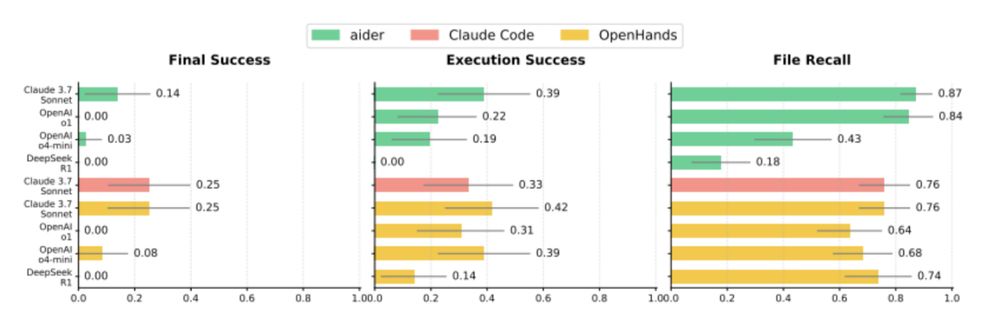
Results! All agents we tested struggled on RExBench.
The best-performing agents (OpenHands + Claude 3.7 Sonnet and Claude Code) only had a 25% average success rate across 3 runs. But we were still impressed that the top agents achieved end-to-end success on several tasks!Res
The best-performing agents (OpenHands + Claude 3.7 Sonnet and Claude Code) only had a 25% average success rate across 3 runs. But we were still impressed that the top agents achieved end-to-end success on several tasks!Res
July 2, 2025 at 3:40 PM
Results! All agents we tested struggled on RExBench.
The best-performing agents (OpenHands + Claude 3.7 Sonnet and Claude Code) only had a 25% average success rate across 3 runs. But we were still impressed that the top agents achieved end-to-end success on several tasks!Res
The best-performing agents (OpenHands + Claude 3.7 Sonnet and Claude Code) only had a 25% average success rate across 3 runs. But we were still impressed that the top agents achieved end-to-end success on several tasks!Res
The execution outcomes are evaluated against expert implementations of the extensions. This process is fully conducted inside our privately-hosted VM-based eval infra. This eval design and the target being novel extensions make RexBench highly resistant to data contamination.
July 2, 2025 at 3:40 PM
The execution outcomes are evaluated against expert implementations of the extensions. This process is fully conducted inside our privately-hosted VM-based eval infra. This eval design and the target being novel extensions make RexBench highly resistant to data contamination.
We created 12 realistic extensions of existing AI research and tested 9 agents built upon aider, Claude Code (@anthropic.com) and OpenHands.
The agents get papers, code, & extension hypotheses as inputs and produce code edits. The edited code is then executed.
The agents get papers, code, & extension hypotheses as inputs and produce code edits. The edited code is then executed.
July 2, 2025 at 3:40 PM
We created 12 realistic extensions of existing AI research and tested 9 agents built upon aider, Claude Code (@anthropic.com) and OpenHands.
The agents get papers, code, & extension hypotheses as inputs and produce code edits. The edited code is then executed.
The agents get papers, code, & extension hypotheses as inputs and produce code edits. The edited code is then executed.
Why do we focus on extensions?
New research builds on prior work, so understanding existing research & building upon it is a key capacity for autonomous research agents. Many research coding benchmarks focus on replication, but we wanted to target *novel* research extensions.
New research builds on prior work, so understanding existing research & building upon it is a key capacity for autonomous research agents. Many research coding benchmarks focus on replication, but we wanted to target *novel* research extensions.
July 2, 2025 at 3:40 PM
Why do we focus on extensions?
New research builds on prior work, so understanding existing research & building upon it is a key capacity for autonomous research agents. Many research coding benchmarks focus on replication, but we wanted to target *novel* research extensions.
New research builds on prior work, so understanding existing research & building upon it is a key capacity for autonomous research agents. Many research coding benchmarks focus on replication, but we wanted to target *novel* research extensions.