




Sebastian Schuster
@sebschu.bsky.social
Computational semantics and pragmatics, interpretability and occasionally some psycholinguistics. he/him. 🦝
https://sebschu.com
https://sebschu.com
What makes an extension difficult for agents?
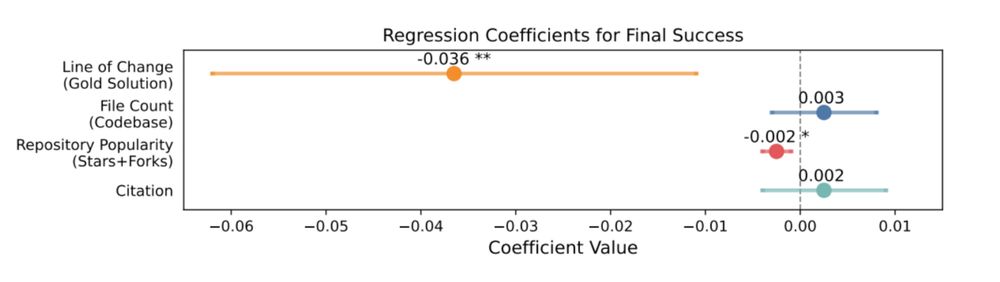
Statistically, tasks with more lines of change in the gold solution were harder. Meanwhile, repo size and popularity had marginal effects. Qualitatively, the performance aligned poorly with human-expert perceived difficulty!
Statistically, tasks with more lines of change in the gold solution were harder. Meanwhile, repo size and popularity had marginal effects. Qualitatively, the performance aligned poorly with human-expert perceived difficulty!
July 2, 2025 at 3:40 PM
What makes an extension difficult for agents?
Statistically, tasks with more lines of change in the gold solution were harder. Meanwhile, repo size and popularity had marginal effects. Qualitatively, the performance aligned poorly with human-expert perceived difficulty!
Statistically, tasks with more lines of change in the gold solution were harder. Meanwhile, repo size and popularity had marginal effects. Qualitatively, the performance aligned poorly with human-expert perceived difficulty!
What if we give them hints?
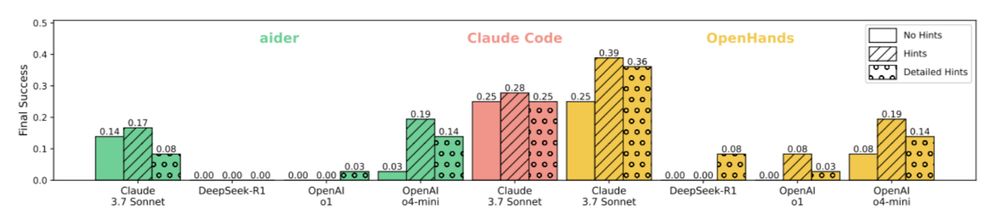
We provided two levels of human-written hints. L1: information localization (e.g., files to edit) & L2: step-by-step guidance. With hints, the best agent’s performance improves to 39%, showing that substantial human guidance is still needed.
We provided two levels of human-written hints. L1: information localization (e.g., files to edit) & L2: step-by-step guidance. With hints, the best agent’s performance improves to 39%, showing that substantial human guidance is still needed.
July 2, 2025 at 3:40 PM
What if we give them hints?
We provided two levels of human-written hints. L1: information localization (e.g., files to edit) & L2: step-by-step guidance. With hints, the best agent’s performance improves to 39%, showing that substantial human guidance is still needed.
We provided two levels of human-written hints. L1: information localization (e.g., files to edit) & L2: step-by-step guidance. With hints, the best agent’s performance improves to 39%, showing that substantial human guidance is still needed.
Results! All agents we tested struggled on RExBench.
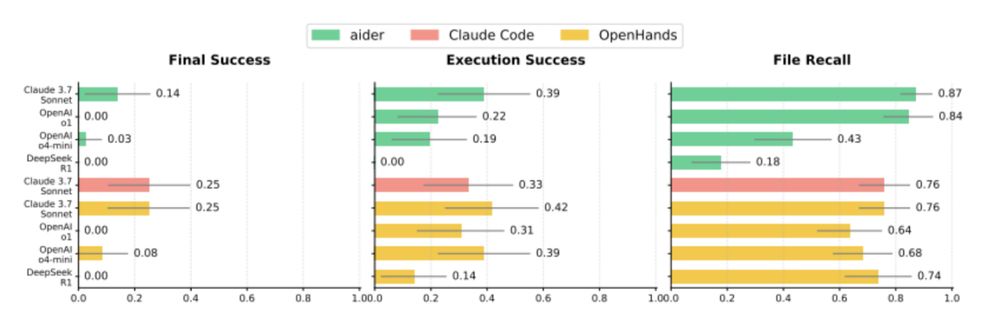
The best-performing agents (OpenHands + Claude 3.7 Sonnet and Claude Code) only had a 25% average success rate across 3 runs. But we were still impressed that the top agents achieved end-to-end success on several tasks!Res
The best-performing agents (OpenHands + Claude 3.7 Sonnet and Claude Code) only had a 25% average success rate across 3 runs. But we were still impressed that the top agents achieved end-to-end success on several tasks!Res
July 2, 2025 at 3:40 PM
Results! All agents we tested struggled on RExBench.
The best-performing agents (OpenHands + Claude 3.7 Sonnet and Claude Code) only had a 25% average success rate across 3 runs. But we were still impressed that the top agents achieved end-to-end success on several tasks!Res
The best-performing agents (OpenHands + Claude 3.7 Sonnet and Claude Code) only had a 25% average success rate across 3 runs. But we were still impressed that the top agents achieved end-to-end success on several tasks!Res
Can coding agents autonomously implement AI research extensions?
We introduce RExBench, a benchmark that tests if a coding agent can implement a novel experiment based on existing research and code.
Finding: Most agents we tested had a low success rate, but there is promise!
We introduce RExBench, a benchmark that tests if a coding agent can implement a novel experiment based on existing research and code.
Finding: Most agents we tested had a low success rate, but there is promise!

July 2, 2025 at 3:40 PM
Can coding agents autonomously implement AI research extensions?
We introduce RExBench, a benchmark that tests if a coding agent can implement a novel experiment based on existing research and code.
Finding: Most agents we tested had a low success rate, but there is promise!
We introduce RExBench, a benchmark that tests if a coding agent can implement a novel experiment based on existing research and code.
Finding: Most agents we tested had a low success rate, but there is promise!