



Sarath Chandar
@sarath-chandar.bsky.social
Associate Professor at Polytechnique Montreal and Mila.
For more context, design choices, scaling observations, and practical tips for applying NovoMolGen to new tasks see our blogpost:
chandar-lab.github.io/NovoMolGen/
chandar-lab.github.io/NovoMolGen/

NovoMolGen: Rethinking Molecular Language Model Pretraining
Open-Source Foundation Models for De novo Molecule Generation
chandar-lab.github.io
September 8, 2025 at 4:07 PM
For more context, design choices, scaling observations, and practical tips for applying NovoMolGen to new tasks see our blogpost:
chandar-lab.github.io/NovoMolGen/
chandar-lab.github.io/NovoMolGen/
To reproduce our unconstrained results, the quickstart notebook samples 30k SMILES and computes the six metrics from our table (Validity, Unique@1k, IntDiv, FCD, SNN, Frag/Scaf) in one cell.
github.com/chandar-lab/...
github.com/chandar-lab/...

NovoMolGen/notebooks/checkpoint_quickstart.ipynb at main · chandar-lab/NovoMolGen
Code for the paper "NovoMolGen: Rethinking Molecular Language Model Pretraining" - chandar-lab/NovoMolGen
github.com
September 8, 2025 at 4:07 PM
To reproduce our unconstrained results, the quickstart notebook samples 30k SMILES and computes the six metrics from our table (Validity, Unique@1k, IntDiv, FCD, SNN, Frag/Scaf) in one cell.
github.com/chandar-lab/...
github.com/chandar-lab/...
To optimize for your own objective, start with this finetuning notebook. It defines a reward (via MoleculeEvaluator or your function), builds our AugmentedHC trainer, and runs a short loop so you can see “before vs after” quickly.
github.com/chandar-lab/...
github.com/chandar-lab/...

September 8, 2025 at 4:07 PM
To optimize for your own objective, start with this finetuning notebook. It defines a reward (via MoleculeEvaluator or your function), builds our AugmentedHC trainer, and runs a short loop so you can see “before vs after” quickly.
github.com/chandar-lab/...
github.com/chandar-lab/...
Want to generate molecules immediately? Use the Transformers-native checkpoint. It loads with AutoModelForCausalLM and works with .generate() (no custom code required). Model card + example: huggingface.co/chandar-lab/...

chandar-lab/NovoMolGen_32M_SMILES_AtomWise · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
September 8, 2025 at 4:07 PM
Want to generate molecules immediately? Use the Transformers-native checkpoint. It loads with AutoModelForCausalLM and works with .generate() (no custom code required). Model card + example: huggingface.co/chandar-lab/...
7/7 Our findings suggest a paradigm shift is needed: from models that learn chemical syntax to models that learn chemical function. Explore paper, use our models, and build on our code!
Paper: www.arxiv.org/abs/2508.13408
Code: github.com/chandar-lab/...
Models: huggingface.co/collections/...
Paper: www.arxiv.org/abs/2508.13408
Code: github.com/chandar-lab/...
Models: huggingface.co/collections/...

NovoMolGen: Rethinking Molecular Language Model Pretraining
Designing de-novo molecules with desired property profiles requires efficient exploration of the vast chemical space ranging from $10^{23}$ to $10^{60}$ possible synthesizable candidates. While variou...
www.arxiv.org
August 22, 2025 at 3:22 PM
7/7 Our findings suggest a paradigm shift is needed: from models that learn chemical syntax to models that learn chemical function. Explore paper, use our models, and build on our code!
Paper: www.arxiv.org/abs/2508.13408
Code: github.com/chandar-lab/...
Models: huggingface.co/collections/...
Paper: www.arxiv.org/abs/2508.13408
Code: github.com/chandar-lab/...
Models: huggingface.co/collections/...
6/7 Foundational chemical knowledge is learned fast. In pretraining, PMO and docking success saturate early. In fact, even our earliest checkpoints beat strong baselines, showing that extended pretraining offers diminishing returns for these functional tasks.

August 22, 2025 at 3:22 PM
6/7 Foundational chemical knowledge is learned fast. In pretraining, PMO and docking success saturate early. In fact, even our earliest checkpoints beat strong baselines, showing that extended pretraining offers diminishing returns for these functional tasks.
5/7 Common pretraining metrics can mislead. FCD, a popular generation metric, shows weak correlation with downstream optimization success. This suggests that optimizing for better FCD scores may not actually lead to better functional molecules.

August 22, 2025 at 3:22 PM
5/7 Common pretraining metrics can mislead. FCD, a popular generation metric, shows weak correlation with downstream optimization success. This suggests that optimizing for better FCD scores may not actually lead to better functional molecules.
4/7 In molecular design, larger models aren’t always needed. We find performance on key drug discovery tasks saturates early. Our 32M model is highly competitive with our 300M model, reaching SOTA while using a fraction of the compute.

August 22, 2025 at 3:22 PM
4/7 In molecular design, larger models aren’t always needed. We find performance on key drug discovery tasks saturates early. Our 32M model is highly competitive with our 300M model, reaching SOTA while using a fraction of the compute.
3/7 In structure-based design, #NovoMolGen discovers molecules with superior binding affinity (lower docking scores) AND achieves significantly higher hit rates, often more than DOUBLE the hit rate of previous SOTA models for key protein targets.

August 22, 2025 at 3:22 PM
3/7 In structure-based design, #NovoMolGen discovers molecules with superior binding affinity (lower docking scores) AND achieves significantly higher hit rates, often more than DOUBLE the hit rate of previous SOTA models for key protein targets.
2/7 How well does it work? On PMO, #NovoMolGen sets a new SOTA. It consistently outperforms strong baselines like f-RAG and REINVENT across a wide range of real-world drug discovery tasks, from multi property optimization to rediscovery, under strict oracle budgets.

August 22, 2025 at 3:22 PM
2/7 How well does it work? On PMO, #NovoMolGen sets a new SOTA. It consistently outperforms strong baselines like f-RAG and REINVENT across a wide range of real-world drug discovery tasks, from multi property optimization to rediscovery, under strict oracle budgets.
Reposted by Sarath Chandar

We have an amazing lineup of speakers, who will share their experience in deploying RL for power systems, industrial processes, nuclear fusion, logistics and more!
Consider submitting!
Consider submitting!

April 8, 2025 at 1:53 PM
We have an amazing lineup of speakers, who will share their experience in deploying RL for power systems, industrial processes, nuclear fusion, logistics and more!
Consider submitting!
Consider submitting!
🤝 This was a project led by my students Arjun and
Hadi, in collaboration with Mathieu, Miao, and Janarthanan!
Paper: arxiv.org/abs/2503.14555
Code: github.com/chandar-lab/...
Models: huggingface.co/chandar-lab/...
Website: chandar-lab.github.io/R3D2-A-Gener.... 7/7
Hadi, in collaboration with Mathieu, Miao, and Janarthanan!
Paper: arxiv.org/abs/2503.14555
Code: github.com/chandar-lab/...
Models: huggingface.co/chandar-lab/...
Website: chandar-lab.github.io/R3D2-A-Gener.... 7/7

A Generalist Hanabi Agent
Traditional multi-agent reinforcement learning (MARL) systems can develop cooperative strategies through repeated interactions. However, these systems are unable to perform well on any other setting t...
arxiv.org
April 4, 2025 at 5:12 PM
🤝 This was a project led by my students Arjun and
Hadi, in collaboration with Mathieu, Miao, and Janarthanan!
Paper: arxiv.org/abs/2503.14555
Code: github.com/chandar-lab/...
Models: huggingface.co/chandar-lab/...
Website: chandar-lab.github.io/R3D2-A-Gener.... 7/7
Hadi, in collaboration with Mathieu, Miao, and Janarthanan!
Paper: arxiv.org/abs/2503.14555
Code: github.com/chandar-lab/...
Models: huggingface.co/chandar-lab/...
Website: chandar-lab.github.io/R3D2-A-Gener.... 7/7
🧠 Can LLMs master Hanabi without RL? We tested SOTA models by prompting them or finetuning them with expert trajectories.
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
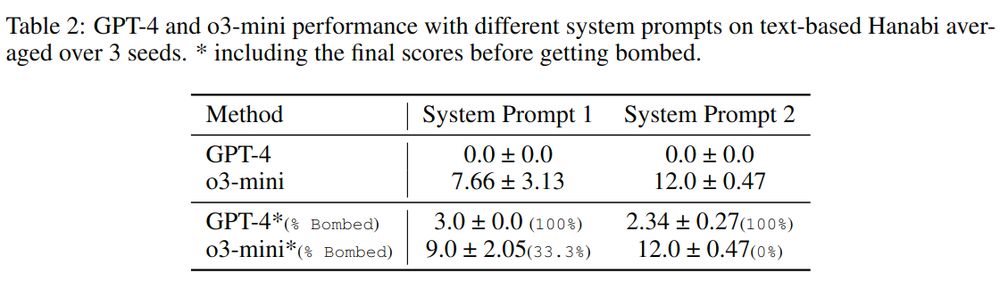
April 4, 2025 at 5:12 PM
🧠 Can LLMs master Hanabi without RL? We tested SOTA models by prompting them or finetuning them with expert trajectories.
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
🎭 Robustness in Cross-Play: We introduce a new inter-setting eval alongside inter/intra-algorithm cross-play—R3D2 adapts smoothly to new agents & envs, outperforming others. Even our 12 (!) reviewers liked the thorough eval! 🔍 #CrossPlay
Openreview: openreview.net/forum?id=pCj...
5/n
Openreview: openreview.net/forum?id=pCj...
5/n
openreview.net
April 4, 2025 at 5:12 PM
🎭 Robustness in Cross-Play: We introduce a new inter-setting eval alongside inter/intra-algorithm cross-play—R3D2 adapts smoothly to new agents & envs, outperforming others. Even our 12 (!) reviewers liked the thorough eval! 🔍 #CrossPlay
Openreview: openreview.net/forum?id=pCj...
5/n
Openreview: openreview.net/forum?id=pCj...
5/n
⚡Zero-Shot Coordination: R3D2 can be trained on multiple settings at once (e.g., 2p & 3p), using simpler games to boost learning in complex ones—letting it coordinate across unseen game settings and partners without explicit training on those settings! 4/n
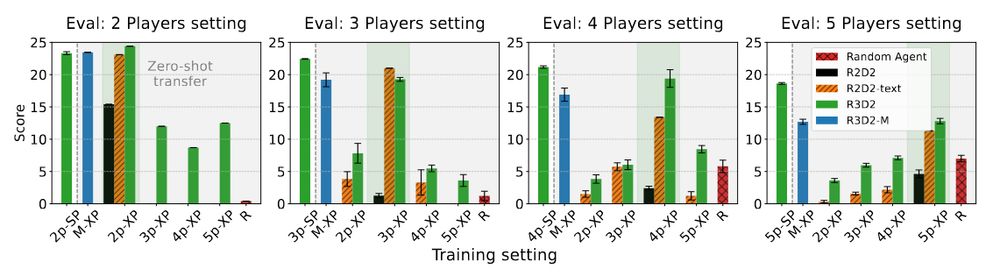
April 4, 2025 at 5:12 PM
⚡Zero-Shot Coordination: R3D2 can be trained on multiple settings at once (e.g., 2p & 3p), using simpler games to boost learning in complex ones—letting it coordinate across unseen game settings and partners without explicit training on those settings! 4/n