



Sarath Chandar
@sarath-chandar.bsky.social
Associate Professor at Polytechnique Montreal and Mila.
I am recruiting several graduate students (both MSc and PhD level) for Fall 2026! The application deadline is December 01. Please apply through the Mila supervision request process here: mila.quebec/en/prospecti....
More details about the recruitment process here: chandar-lab.github.io/join/
More details about the recruitment process here: chandar-lab.github.io/join/

October 24, 2025 at 2:14 PM
I am recruiting several graduate students (both MSc and PhD level) for Fall 2026! The application deadline is December 01. Please apply through the Mila supervision request process here: mila.quebec/en/prospecti....
More details about the recruitment process here: chandar-lab.github.io/join/
More details about the recruitment process here: chandar-lab.github.io/join/
At Chandar Lab, we are happy to announce the third edition of our assistance program to provide feedback for members of communities underrepresented in AI who want to apply to high-profile graduate programs. Want feedback? Details: chandar-lab.github.io/grad_app/. Deadline: Nov 01!

October 3, 2025 at 3:20 PM
At Chandar Lab, we are happy to announce the third edition of our assistance program to provide feedback for members of communities underrepresented in AI who want to apply to high-profile graduate programs. Want feedback? Details: chandar-lab.github.io/grad_app/. Deadline: Nov 01!
To optimize for your own objective, start with this finetuning notebook. It defines a reward (via MoleculeEvaluator or your function), builds our AugmentedHC trainer, and runs a short loop so you can see “before vs after” quickly.
github.com/chandar-lab/...
github.com/chandar-lab/...

September 8, 2025 at 4:07 PM
To optimize for your own objective, start with this finetuning notebook. It defines a reward (via MoleculeEvaluator or your function), builds our AugmentedHC trainer, and runs a short loop so you can see “before vs after” quickly.
github.com/chandar-lab/...
github.com/chandar-lab/...
We just made NovoMolGen easy to play with: Transformers-native checkpoints on the Hub and small notebooks that let you load, sample, and fine-tune in minutes. The few lines of code that load the model, plug in a reward, run a short RL finetune, and plot the curve.

September 8, 2025 at 4:07 PM
We just made NovoMolGen easy to play with: Transformers-native checkpoints on the Hub and small notebooks that let you load, sample, and fine-tune in minutes. The few lines of code that load the model, plug in a reward, run a short RL finetune, and plot the curve.
6/7 Foundational chemical knowledge is learned fast. In pretraining, PMO and docking success saturate early. In fact, even our earliest checkpoints beat strong baselines, showing that extended pretraining offers diminishing returns for these functional tasks.

August 22, 2025 at 3:22 PM
6/7 Foundational chemical knowledge is learned fast. In pretraining, PMO and docking success saturate early. In fact, even our earliest checkpoints beat strong baselines, showing that extended pretraining offers diminishing returns for these functional tasks.
5/7 Common pretraining metrics can mislead. FCD, a popular generation metric, shows weak correlation with downstream optimization success. This suggests that optimizing for better FCD scores may not actually lead to better functional molecules.

August 22, 2025 at 3:22 PM
5/7 Common pretraining metrics can mislead. FCD, a popular generation metric, shows weak correlation with downstream optimization success. This suggests that optimizing for better FCD scores may not actually lead to better functional molecules.
4/7 In molecular design, larger models aren’t always needed. We find performance on key drug discovery tasks saturates early. Our 32M model is highly competitive with our 300M model, reaching SOTA while using a fraction of the compute.

August 22, 2025 at 3:22 PM
4/7 In molecular design, larger models aren’t always needed. We find performance on key drug discovery tasks saturates early. Our 32M model is highly competitive with our 300M model, reaching SOTA while using a fraction of the compute.
3/7 In structure-based design, #NovoMolGen discovers molecules with superior binding affinity (lower docking scores) AND achieves significantly higher hit rates, often more than DOUBLE the hit rate of previous SOTA models for key protein targets.

August 22, 2025 at 3:22 PM
3/7 In structure-based design, #NovoMolGen discovers molecules with superior binding affinity (lower docking scores) AND achieves significantly higher hit rates, often more than DOUBLE the hit rate of previous SOTA models for key protein targets.
2/7 How well does it work? On PMO, #NovoMolGen sets a new SOTA. It consistently outperforms strong baselines like f-RAG and REINVENT across a wide range of real-world drug discovery tasks, from multi property optimization to rediscovery, under strict oracle budgets.

August 22, 2025 at 3:22 PM
2/7 How well does it work? On PMO, #NovoMolGen sets a new SOTA. It consistently outperforms strong baselines like f-RAG and REINVENT across a wide range of real-world drug discovery tasks, from multi property optimization to rediscovery, under strict oracle budgets.
Molecules speak in atoms and bonds. LLMs can learn that language. Even with SOTA #denovo design, our largest molecular LLM study finds a plot twist: early saturation, weak scaling, and proxy metrics that mislead on real tasks! Led by Kamran and Roshan!
🧵 More in thread:
🧵 More in thread:
August 22, 2025 at 3:22 PM
Molecules speak in atoms and bonds. LLMs can learn that language. Even with SOTA #denovo design, our largest molecular LLM study finds a plot twist: early saturation, weak scaling, and proxy metrics that mislead on real tasks! Led by Kamran and Roshan!
🧵 More in thread:
🧵 More in thread:
🧠 Can LLMs master Hanabi without RL? We tested SOTA models by prompting them or finetuning them with expert trajectories.
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
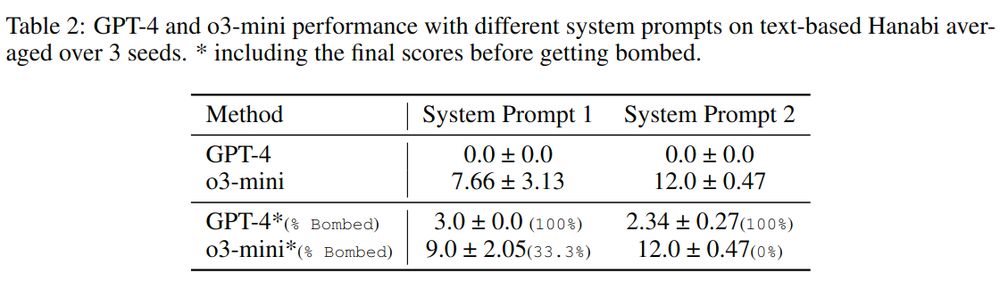
April 4, 2025 at 5:12 PM
🧠 Can LLMs master Hanabi without RL? We tested SOTA models by prompting them or finetuning them with expert trajectories.
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
Results? Still far off—o3-mini scored only 12 out of 25 even with extensive prompting! 🚧 #LLMs 6/n
⚡Zero-Shot Coordination: R3D2 can be trained on multiple settings at once (e.g., 2p & 3p), using simpler games to boost learning in complex ones—letting it coordinate across unseen game settings and partners without explicit training on those settings! 4/n
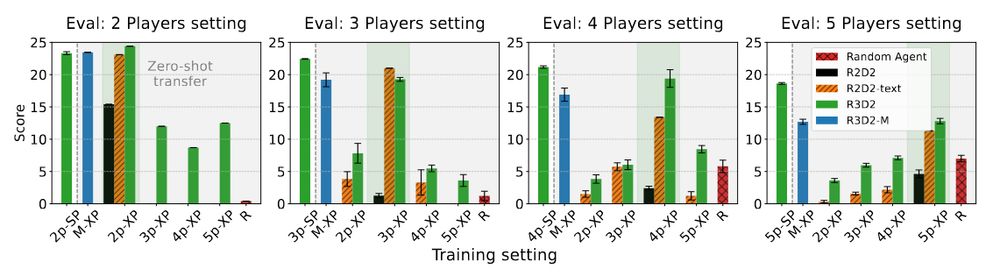
April 4, 2025 at 5:12 PM
⚡Zero-Shot Coordination: R3D2 can be trained on multiple settings at once (e.g., 2p & 3p), using simpler games to boost learning in complex ones—letting it coordinate across unseen game settings and partners without explicit training on those settings! 4/n
🔄 Self-Play & Generalization: R3D2 adapts to new partners & game setups without complex MARL tricks—just smart representations & architecture. Shows self-play alone can go far for generalizable policies! #ZeroShot #PolicyTransfer 3/n
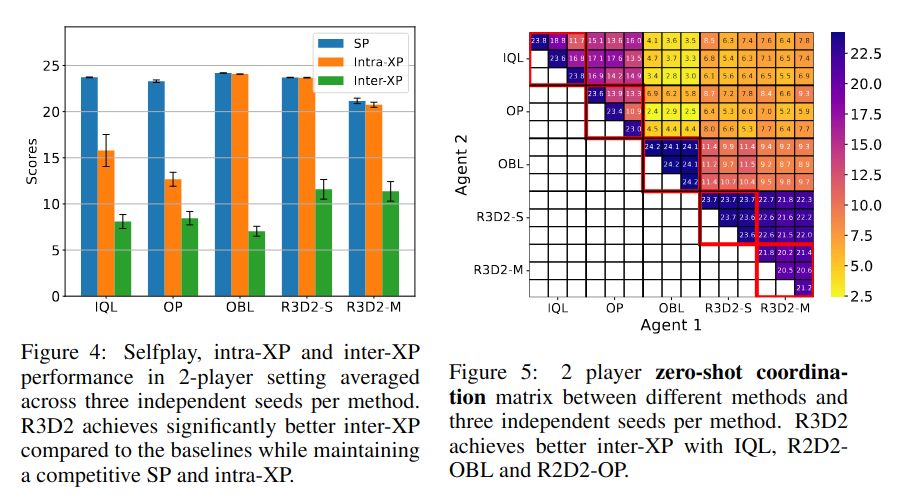
April 4, 2025 at 5:12 PM
🔄 Self-Play & Generalization: R3D2 adapts to new partners & game setups without complex MARL tricks—just smart representations & architecture. Shows self-play alone can go far for generalizable policies! #ZeroShot #PolicyTransfer 3/n
🔡 Dynamic observation- and action-space: We frame Hanabi as a text game and use a dynamic action-space architecture, DRRN (He et al., 2015), letting R3D2 adapt across settings via text input—drawing on the power of language as representation. #TextGames 2/n

April 4, 2025 at 5:12 PM
🔡 Dynamic observation- and action-space: We frame Hanabi as a text game and use a dynamic action-space architecture, DRRN (He et al., 2015), letting R3D2 adapt across settings via text input—drawing on the power of language as representation. #TextGames 2/n
Can better architectures & representations make self-play enough for zero-shot coordination? 🤔
We explore this in our ICLR 2025 paper: A Generalist Hanabi Agent. We develop R3D2, the first agent to master all Hanabi settings and generalize to novel partners! 🚀 #ICLR2025 1/n
We explore this in our ICLR 2025 paper: A Generalist Hanabi Agent. We develop R3D2, the first agent to master all Hanabi settings and generalize to novel partners! 🚀 #ICLR2025 1/n
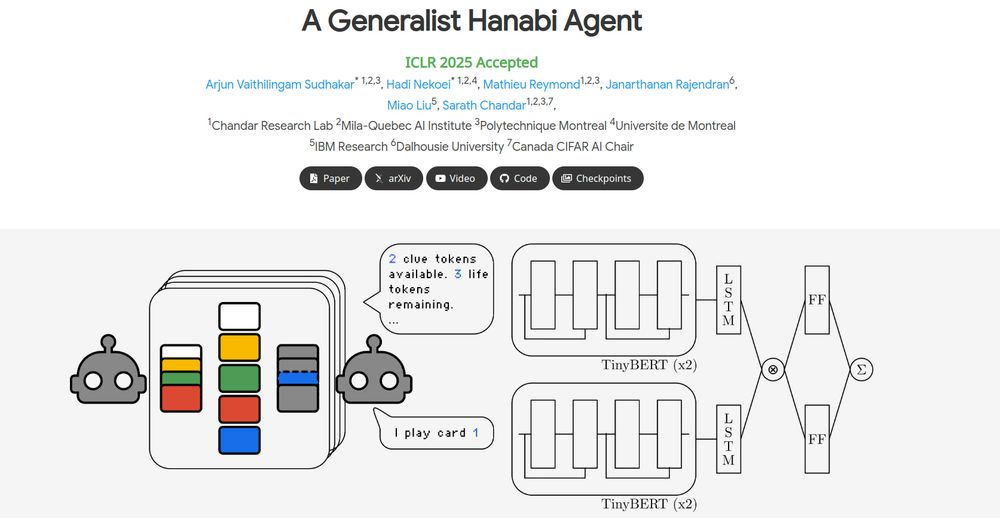
April 4, 2025 at 5:12 PM
Can better architectures & representations make self-play enough for zero-shot coordination? 🤔
We explore this in our ICLR 2025 paper: A Generalist Hanabi Agent. We develop R3D2, the first agent to master all Hanabi settings and generalize to novel partners! 🚀 #ICLR2025 1/n
We explore this in our ICLR 2025 paper: A Generalist Hanabi Agent. We develop R3D2, the first agent to master all Hanabi settings and generalize to novel partners! 🚀 #ICLR2025 1/n
In my lab, we have not one but four open postdoc positions! If you have strong research expertise and a PhD in LLMs and Foundation Models, and you are willing to learn about domain-specific problems and collaborate with domain experts, this is an ideal position for you! 1/2

March 21, 2025 at 2:49 PM
In my lab, we have not one but four open postdoc positions! If you have strong research expertise and a PhD in LLMs and Foundation Models, and you are willing to learn about domain-specific problems and collaborate with domain experts, this is an ideal position for you! 1/2




I gave a talk on developing efficient foundation models for proteins and small molecules at the Helmholtz-ELLIS Workshop on Foundation Models in Science (www.mdc-berlin.de/news/events/...) today.
If you are interested in my spicy takes on ML for Biology, continue reading this thread! 1/n
If you are interested in my spicy takes on ML for Biology, continue reading this thread! 1/n

March 19, 2025 at 2:07 PM
I gave a talk on developing efficient foundation models for proteins and small molecules at the Helmholtz-ELLIS Workshop on Foundation Models in Science (www.mdc-berlin.de/news/events/...) today.
If you are interested in my spicy takes on ML for Biology, continue reading this thread! 1/n
If you are interested in my spicy takes on ML for Biology, continue reading this thread! 1/n
I am excited to share that our BindGPT paper won the best poster award at #AAAI2025! Congratulations to the team! Work led by @artemzholus.bsky.social!

March 5, 2025 at 2:54 PM
I am excited to share that our BindGPT paper won the best poster award at #AAAI2025! Congratulations to the team! Work led by @artemzholus.bsky.social!
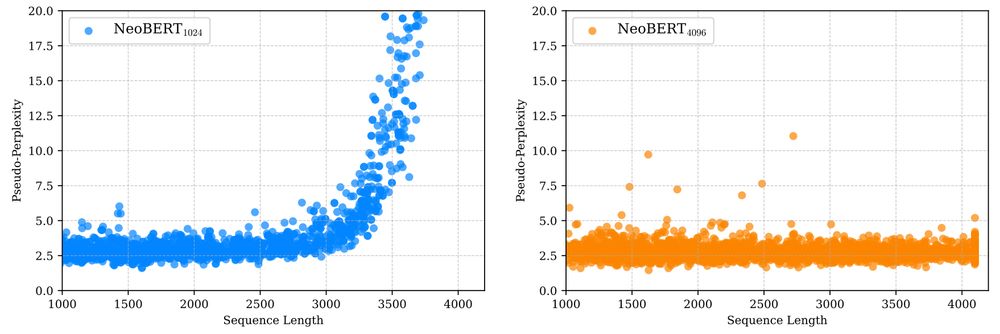
After training for 1M steps with a maximum sequence length of 1024, we did a final 50k steps at 4096. This two-step training was a cost-efficient strategy to scale the model’s maximum context window. For further scaling, our use of RoPE embeddings also lets us integrate YaRN! (5/n)
February 28, 2025 at 4:30 PM
After training for 1M steps with a maximum sequence length of 1024, we did a final 50k steps at 4096. This two-step training was a cost-efficient strategy to scale the model’s maximum context window. For further scaling, our use of RoPE embeddings also lets us integrate YaRN! (5/n)
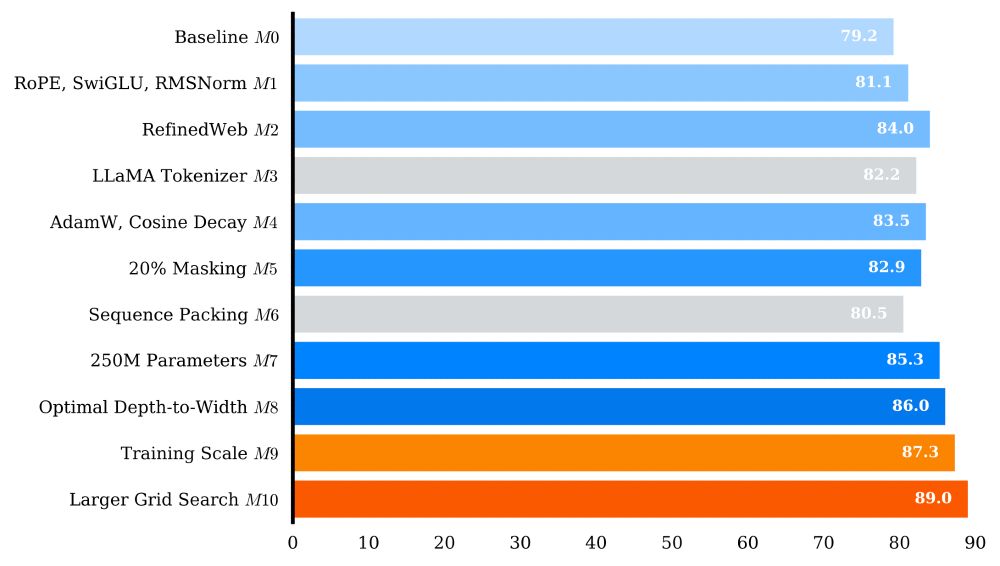
Before pre-training NeoBERT, we conducted thorough ablations on all our design choices by pre-training 9 different models at the scale of BERT (1M steps, 131k batch size). (4/n)
February 28, 2025 at 4:30 PM
Before pre-training NeoBERT, we conducted thorough ablations on all our design choices by pre-training 9 different models at the scale of BERT (1M steps, 131k batch size). (4/n)
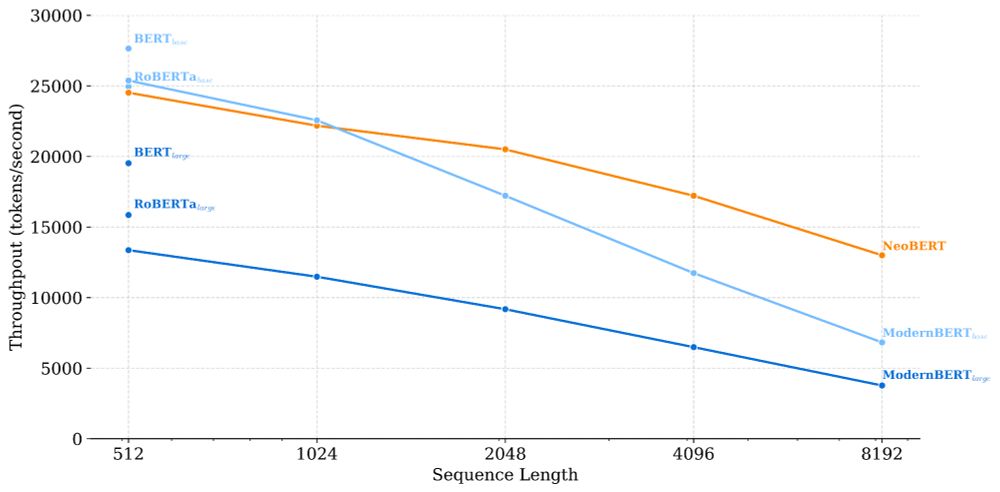
Its features include a native context length of 4,096, an optimal-depth-to-width ratio with 250M parameters, and the most efficient inference speeds of its kind! (3/n)
February 28, 2025 at 4:30 PM
Its features include a native context length of 4,096, an optimal-depth-to-width ratio with 250M parameters, and the most efficient inference speeds of its kind! (3/n)