



Ryan Sullivan
@ryanpsullivan.bsky.social
PhD Candidate at the University of Maryland researching reinforcement learning and autocurricula in complex, open-ended environments.
Previously RL intern @ SonyAI, RLHF intern @ Google Research, and RL intern @ Amazon Science
Previously RL intern @ SonyAI, RLHF intern @ Google Research, and RL intern @ Amazon Science
Passive might already have a different meaning in RL (learning from data generated by a different agent’s learning trajectory) arxiv.org/abs/2110.14020

The Difficulty of Passive Learning in Deep Reinforcement Learning
Learning to act from observational data without active environmental interaction is a well-known challenge in Reinforcement Learning (RL). Recent approaches involve constraints on the learned policy o...
arxiv.org
March 14, 2025 at 11:57 PM
Passive might already have a different meaning in RL (learning from data generated by a different agent’s learning trajectory) arxiv.org/abs/2110.14020
My interpretation of those stats is that AI writes 90% of low entropy code. A lot of code is boilerplate, and llms are great at writing it. People probably still write 90% and (should) review 100% of meaningful code.
March 14, 2025 at 11:52 PM
My interpretation of those stats is that AI writes 90% of low entropy code. A lot of code is boilerplate, and llms are great at writing it. People probably still write 90% and (should) review 100% of meaningful code.
Thanks for sharing this! It’s unfortunate that this type of work is so heavily disincentivized. Solving hard problems that push the field forward takes much longer, starts off with a lot of negative results, and rarely has any obvious novelty. But in the long run it helps everyone do better research
March 10, 2025 at 10:10 AM
Thanks for sharing this! It’s unfortunate that this type of work is so heavily disincentivized. Solving hard problems that push the field forward takes much longer, starts off with a lot of negative results, and rarely has any obvious novelty. But in the long run it helps everyone do better research
Let’s meet halfway, machine god that is content to install cuda and debug async code for me.
February 12, 2025 at 11:11 AM
Let’s meet halfway, machine god that is content to install cuda and debug async code for me.
I think it’s interesting because it shouldn’t be possible, even with a really unreasonable compute budget. It would imply that PPO can solve pretty much any problem with enough funding which I don’t think is true. Beating NetHack efficiently is of course more useful and interesting.
January 6, 2025 at 6:21 PM
I think it’s interesting because it shouldn’t be possible, even with a really unreasonable compute budget. It would imply that PPO can solve pretty much any problem with enough funding which I don’t think is true. Beating NetHack efficiently is of course more useful and interesting.
Nothing can yet, but the best RL baseline for NetHack is (asynchronous) PPO
January 6, 2025 at 6:02 PM
Nothing can yet, but the best RL baseline for NetHack is (asynchronous) PPO
Thank you! If you end up trying it out let me know, I'm happy to answer any questions.
December 5, 2024 at 4:21 PM
Thank you! If you end up trying it out let me know, I'm happy to answer any questions.
I have a lot more experiments from working on Syllabus so I’ll share more of those over the next few weeks. Now is probably a good time to mention I’m also looking for industry or postdoc positions starting in Fall 2024, so if you’re working on anything RL-related let me know!
December 5, 2024 at 4:13 PM
I have a lot more experiments from working on Syllabus so I’ll share more of those over the next few weeks. Now is probably a good time to mention I’m also looking for industry or postdoc positions starting in Fall 2024, so if you’re working on anything RL-related let me know!
Syllabus opens up a ton of low hanging fruit in CL. I’m still working on this and actively using it for my research, so if you’re interested in contributing, please feel free to reach out!
Paper: arxiv.org/abs/2411.11318
Github: github.com/RyanNavillus...
Paper: arxiv.org/abs/2411.11318
Github: github.com/RyanNavillus...

Syllabus: Portable Curricula for Reinforcement Learning Agents
Curriculum learning has been a quiet yet crucial component of many of the high-profile successes of reinforcement learning. Despite this, none of the major reinforcement learning libraries directly su...
arxiv.org
December 5, 2024 at 4:13 PM
Syllabus opens up a ton of low hanging fruit in CL. I’m still working on this and actively using it for my research, so if you’re interested in contributing, please feel free to reach out!
Paper: arxiv.org/abs/2411.11318
Github: github.com/RyanNavillus...
Paper: arxiv.org/abs/2411.11318
Github: github.com/RyanNavillus...
I’d like to thank my collaborators @ryan-pgd.bsky.social, Ameen Ur Rehman, Xinchen Yang, Junyun Huang, Aayush Verma, Nistha Mitra, and John P. Dickerson as well as @minqi.bsky.social, @samvelyan.com, and Jenny Zhang for their valuable feedback and answers to my many implementation questions.
December 5, 2024 at 4:12 PM
I’d like to thank my collaborators @ryan-pgd.bsky.social, Ameen Ur Rehman, Xinchen Yang, Junyun Huang, Aayush Verma, Nistha Mitra, and John P. Dickerson as well as @minqi.bsky.social, @samvelyan.com, and Jenny Zhang for their valuable feedback and answers to my many implementation questions.
We have implementations of Prioritized Level Replay, a learning progress curriculum, and Prioritized Fictitious Self Play, plus several tools for manually designing curricula like simulated annealing and sequential curricula. Stay tuned for more methods in the very near future!
December 5, 2024 at 4:12 PM
We have implementations of Prioritized Level Replay, a learning progress curriculum, and Prioritized Fictitious Self Play, plus several tools for manually designing curricula like simulated annealing and sequential curricula. Stay tuned for more methods in the very near future!
These portable implementations of CL methods work with nearly any RL library, meaning that you only need to implement the method once to guarantee that the same CL code is being used in every project. This minimizes the risk of implementation errors and promotes reproducibility.
December 5, 2024 at 4:12 PM
These portable implementations of CL methods work with nearly any RL library, meaning that you only need to implement the method once to guarantee that the same CL code is being used in every project. This minimizes the risk of implementation errors and promotes reproducibility.
Most importantly, it’s extremely easy to use! You add a synchronization wrapper to your environments and your curriculum, plus a little more configuration, and it just works. For most methods, you don’t need to make any changes to the actual training logic.
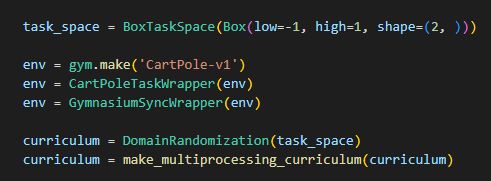
December 5, 2024 at 4:12 PM
Most importantly, it’s extremely easy to use! You add a synchronization wrapper to your environments and your curriculum, plus a little more configuration, and it just works. For most methods, you don’t need to make any changes to the actual training logic.
Syllabus helps researchers study CL in complex, open-ended environments without having to write new multiprocessing infrastructure. It uses a separate multiprocessing channel between the curriculum and environments to directly send new tasks and receive feedback
December 5, 2024 at 4:11 PM
Syllabus helps researchers study CL in complex, open-ended environments without having to write new multiprocessing infrastructure. It uses a separate multiprocessing channel between the curriculum and environments to directly send new tasks and receive feedback
As a result, CL research often focuses on relatively simple environments, despite the existence of challenging benchmarks like NetHack, Minecraft, and Neural MMO. Unsurprisingly, many of the methods developed in simpler environments won’t work as well on more complex domains.
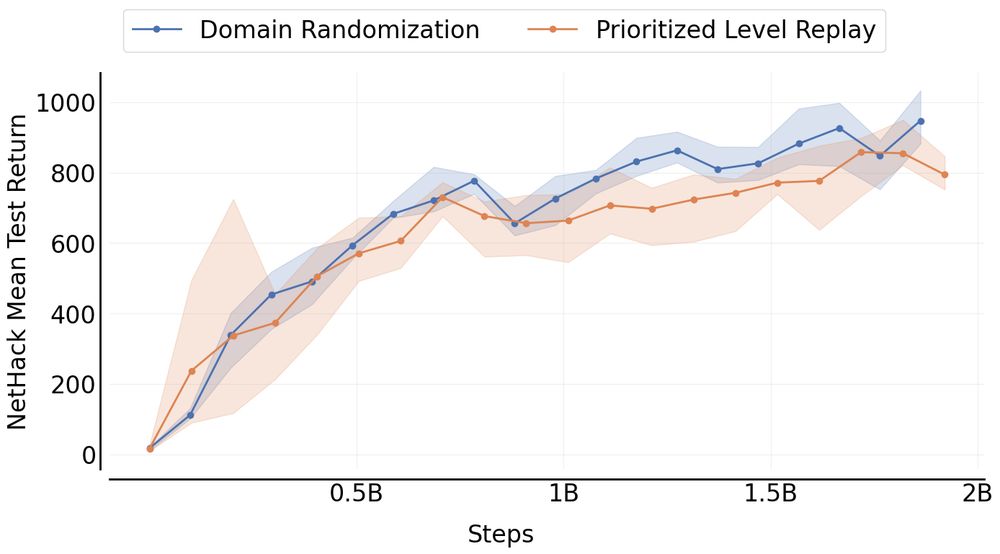
December 5, 2024 at 4:11 PM
As a result, CL research often focuses on relatively simple environments, despite the existence of challenging benchmarks like NetHack, Minecraft, and Neural MMO. Unsurprisingly, many of the methods developed in simpler environments won’t work as well on more complex domains.
CL is a powerful tool for training general agents, but it requires features that aren't supported by popular RL libraries. This makes it difficult to evaluate CL methods with new RL algorithms or in complex environments that require advanced RL techniques to solve.
December 5, 2024 at 4:11 PM
CL is a powerful tool for training general agents, but it requires features that aren't supported by popular RL libraries. This makes it difficult to evaluate CL methods with new RL algorithms or in complex environments that require advanced RL techniques to solve.
I translated Arrow’s impossibility theorem to find flaws in popular tourney formats, which was moderately helpful for my project. I wasn’t able to take those ideas any further but I found the connection fascinating. It’s awesome to see those ideas developed into a practical evaluation algorithm.
November 28, 2024 at 2:50 AM
I translated Arrow’s impossibility theorem to find flaws in popular tourney formats, which was moderately helpful for my project. I wasn’t able to take those ideas any further but I found the connection fascinating. It’s awesome to see those ideas developed into a practical evaluation algorithm.