



Roy Fox
@royf.org
Assistant Professor of Computer Science, UC Irvine
Website: royf.org
Website: royf.org

Quick links to the 2024 reviewed works:
1. bsky.app/profile/royf...
2. bsky.app/profile/royf...
3. bsky.app/profile/royf...
4. bsky.app/profile/royf...
5. bsky.app/profile/royf...
1. bsky.app/profile/royf...
2. bsky.app/profile/royf...
3. bsky.app/profile/royf...
4. bsky.app/profile/royf...
5. bsky.app/profile/royf...
December 31, 2024 at 8:03 PM
Quick links to the 2024 reviewed works:
1. bsky.app/profile/royf...
2. bsky.app/profile/royf...
3. bsky.app/profile/royf...
4. bsky.app/profile/royf...
5. bsky.app/profile/royf...
1. bsky.app/profile/royf...
2. bsky.app/profile/royf...
3. bsky.app/profile/royf...
4. bsky.app/profile/royf...
5. bsky.app/profile/royf...
2. Using RL to guide search. We called it Q* before OpenAI made that name famous.
“Q* Search: Heuristic Search with Deep Q-Networks”, by Forest Agostinelli, in collaboration with Shahaf Shperberg, Alexander Shmakov, Stephen McAleer, and Pierre Baldi. PRL @ ICAPS 2024.
“Q* Search: Heuristic Search with Deep Q-Networks”, by Forest Agostinelli, in collaboration with Shahaf Shperberg, Alexander Shmakov, Stephen McAleer, and Pierre Baldi. PRL @ ICAPS 2024.
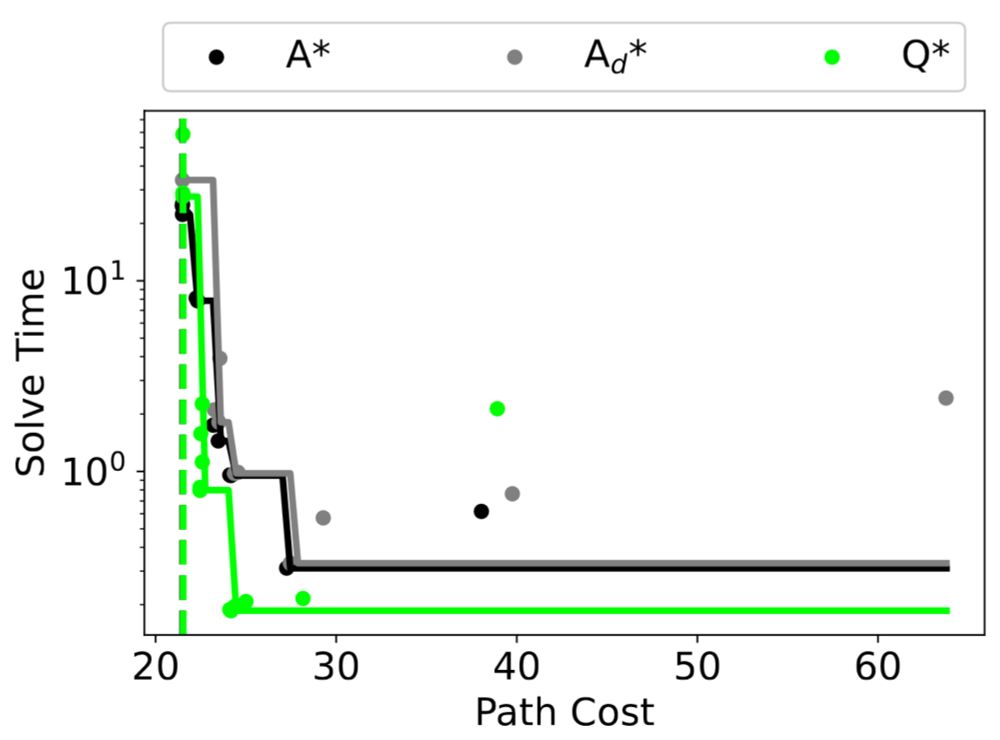
Q* Search: Heuristic Search with Deep Q-Networks
Efficiently solving problems with large action spaces using A* search has been of importance to the artificial intelligence community for decades. This is because the computation and memory requiremen...
indylab.org
December 31, 2024 at 8:03 PM
2. Using RL to guide search. We called it Q* before OpenAI made that name famous.
“Q* Search: Heuristic Search with Deep Q-Networks”, by Forest Agostinelli, in collaboration with Shahaf Shperberg, Alexander Shmakov, Stephen McAleer, and Pierre Baldi. PRL @ ICAPS 2024.
“Q* Search: Heuristic Search with Deep Q-Networks”, by Forest Agostinelli, in collaboration with Shahaf Shperberg, Alexander Shmakov, Stephen McAleer, and Pierre Baldi. PRL @ ICAPS 2024.
1. Using segmentation foundation models to overcome distractions in model-based RL.
“Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distraction”, by Kyungmin Kim, in collaboration with Charless Fowlkes. TAFM @ RLC 2024.
“Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distraction”, by Kyungmin Kim, in collaboration with Charless Fowlkes. TAFM @ RLC 2024.
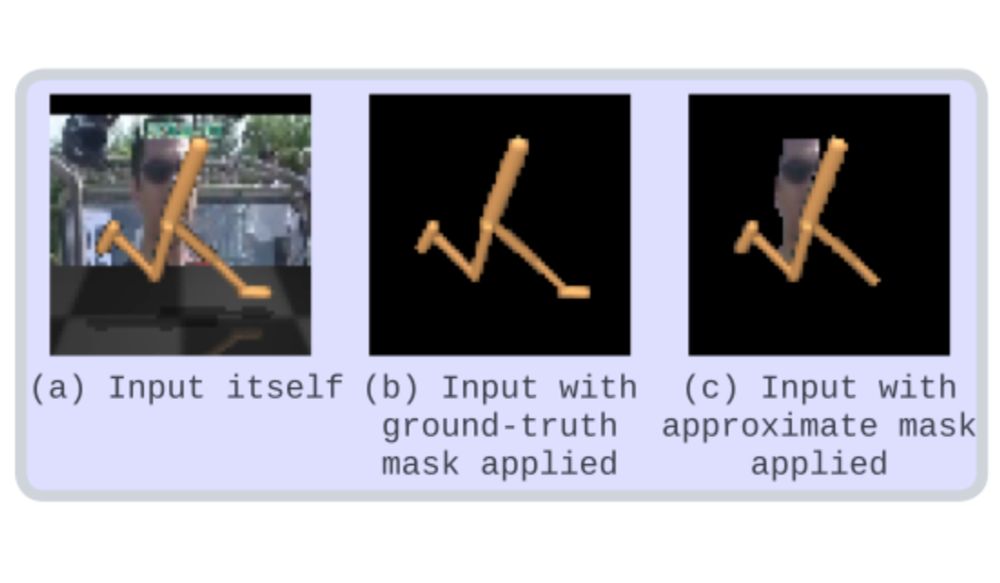
Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distraction
Model-Based Reinforcement Learning (MBRL) has been a powerful tool for visual control tasks. Despite improved data efficiency, it remains challenging to use MBRL to train agents with generalizable per...
indylab.org
December 31, 2024 at 8:03 PM
1. Using segmentation foundation models to overcome distractions in model-based RL.
“Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distraction”, by Kyungmin Kim, in collaboration with Charless Fowlkes. TAFM @ RLC 2024.
“Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distraction”, by Kyungmin Kim, in collaboration with Charless Fowlkes. TAFM @ RLC 2024.
Davide Corsi @dcorsi.bsky.social, a rising star in Safe Robot Learning, led this work in collaboration with Guy Amir, Andoni Rodríguez, César Sánchez, and Guy Katz, published in RLC 2024. Not to be confused with Davide's other work in RLC 2024, for which he won a Best Paper Award (see below).
RLJ · Aquatic Navigation: A Challenging Benchmark for Deep Reinforcement Learning
Reinforcement Learning Journal (RLJ)
rlj.cs.umass.edu
December 31, 2024 at 7:43 PM
Davide Corsi @dcorsi.bsky.social, a rising star in Safe Robot Learning, led this work in collaboration with Guy Amir, Andoni Rodríguez, César Sánchez, and Guy Katz, published in RLC 2024. Not to be confused with Davide's other work in RLC 2024, for which he won a Best Paper Award (see below).
If the unsafe state space is small, and the boundary simplification is careful not to expand it much, the result is that we can safely run the policy and only rarely invoke the shield on unsafe states, leading to significant speedup with safety guarantees.
December 31, 2024 at 7:43 PM
If the unsafe state space is small, and the boundary simplification is careful not to expand it much, the result is that we can safely run the policy and only rarely invoke the shield on unsafe states, leading to significant speedup with safety guarantees.
The trick is to use offline verification not only to label a policy safe/unsafe, but to label each state safe/unsafe, resp. if the policy's action there satisfies/violates safety constraints. The partition is complex, so we simplify it while guaranteeing no false negatives (no unsafe labeled safe).
December 31, 2024 at 7:43 PM
The trick is to use offline verification not only to label a policy safe/unsafe, but to label each state safe/unsafe, resp. if the policy's action there satisfies/violates safety constraints. The partition is complex, so we simplify it while guaranteeing no false negatives (no unsafe labeled safe).
Online verification can be slow but more useful than offline: it's easier to replace occasional unsafe actions than entire unsafe policies. And unsafe actions are often rare, only reducing optimality a little. But it's costly that we need to run the shield on every action, even if it turns out safe.
December 31, 2024 at 7:43 PM
Online verification can be slow but more useful than offline: it's easier to replace occasional unsafe actions than entire unsafe policies. And unsafe actions are often rare, only reducing optimality a little. But it's costly that we need to run the shield on every action, even if it turns out safe.
Given a control policy (say, a reinforcement-learned neural network) and a set of safety constraints, there are 2 ways to verify safety: offline, where the policy is verified to always output safe actions; and online, where a “shield” intercepts unsafe actions and replaces them with safe ones.
December 31, 2024 at 7:43 PM
Given a control policy (say, a reinforcement-learned neural network) and a set of safety constraints, there are 2 ways to verify safety: offline, where the policy is verified to always output safe actions; and online, where a “shield” intercepts unsafe actions and replaces them with safe ones.
Led by the fantastic Armin Karamzade in collaboration with Kyungmin Kim and Montek Kalsi, this work was published in RLC 2024.
December 30, 2024 at 7:44 PM
Led by the fantastic Armin Karamzade in collaboration with Kyungmin Kim and Montek Kalsi, this work was published in RLC 2024.
This method works well for short delays, but gets worse as the WM drifts over longer horizons than it was trained for. For longer delays, our experiments suggest a simpler method that directly conditions the policy on the delayed WM state and the following actions.
December 30, 2024 at 7:44 PM
This method works well for short delays, but gets worse as the WM drifts over longer horizons than it was trained for. For longer delays, our experiments suggest a simpler method that directly conditions the policy on the delayed WM state and the following actions.
This suggests several delayed model-based RL methods. Most interestingly, when observations are delayed, we can use the WM to imagine how recent actions could have affected the world state, in order to choose the next action.
December 30, 2024 at 7:44 PM
This suggests several delayed model-based RL methods. Most interestingly, when observations are delayed, we can use the WM to imagine how recent actions could have affected the world state, in order to choose the next action.
But real-world control problems are often partially observable. Can we use the structure of delayed POMDPs? Recent world modeling (WM) methods have a cool property: they can learn an MDP model of a POMDP. We show that for a good WM of an undelayed POMDP, the delayed WM models the delayed POMDP.
December 30, 2024 at 7:44 PM
But real-world control problems are often partially observable. Can we use the structure of delayed POMDPs? Recent world modeling (WM) methods have a cool property: they can learn an MDP model of a POMDP. We show that for a good WM of an undelayed POMDP, the delayed WM models the delayed POMDP.
Previous works have noticed some important modeling tricks. First, delays can be modeled as just partial observability (POMDP), but generic POMDPs lose the nice temporal structure provided by delays. Second, delayed MDPs are still MDPs, in a larger state space — exponential, but keeps the structure.
December 30, 2024 at 7:44 PM
Previous works have noticed some important modeling tricks. First, delays can be modeled as just partial observability (POMDP), but generic POMDPs lose the nice temporal structure provided by delays. Second, delayed MDPs are still MDPs, in a larger state space — exponential, but keeps the structure.