



Roy Fox
@royf.org
Assistant Professor of Computer Science, UC Irvine
Website: royf.org
Website: royf.org
Reposted by Roy Fox

This year's ACM/SIGAI Autonomous Agents Research Award goes to Prof. Shlomo Zilberstein. His work on decentralized Markov Decision Processes laid the foundation for decision-theoretic planning in multi-agent systems and multi-agent reinforcement learning.
sigai.acm.org/main/2025/03...
#SIGAIAward
sigai.acm.org/main/2025/03...
#SIGAIAward

Shlomo Zilberstein (2025 Autonomous Agents Research Award) - ACM SIGAI
The selection committee for the ACM/SIGAI Autonomous Agents Research Award is pleased to announce that Professor Shlomo Zilberstein is the recipient of the 2025 award. Shlomo Zilberstein is Professor…
sigai.acm.org
March 11, 2025 at 12:15 PM
This year's ACM/SIGAI Autonomous Agents Research Award goes to Prof. Shlomo Zilberstein. His work on decentralized Markov Decision Processes laid the foundation for decision-theoretic planning in multi-agent systems and multi-agent reinforcement learning.
sigai.acm.org/main/2025/03...
#SIGAIAward
sigai.acm.org/main/2025/03...
#SIGAIAward
Reposted by Roy Fox

Exciting news - early bird registration is now open for #RLDM2025!
🔗 Register now: forms.gle/QZS1GkZhYGRF...
Register now to save €100 on your ticket. Early bird prices are only available until 1st April.
🔗 Register now: forms.gle/QZS1GkZhYGRF...
Register now to save €100 on your ticket. Early bird prices are only available until 1st April.

February 11, 2025 at 2:56 PM
Exciting news - early bird registration is now open for #RLDM2025!
🔗 Register now: forms.gle/QZS1GkZhYGRF...
Register now to save €100 on your ticket. Early bird prices are only available until 1st April.
🔗 Register now: forms.gle/QZS1GkZhYGRF...
Register now to save €100 on your ticket. Early bird prices are only available until 1st April.
2025 is looking to be the year that information-theoretic principles in sequential decision making, finally make a comeback! (at least for me, I know others never stopped.) already 4 very exciting projects, and counting!
February 3, 2025 at 4:57 PM
2025 is looking to be the year that information-theoretic principles in sequential decision making, finally make a comeback! (at least for me, I know others never stopped.) already 4 very exciting projects, and counting!
I received an email from the Department of Energy stating that “DOE is moving aggressively to implement this Executive Order by directing the suspension of [...] DEI policies [...] Community Benefits Plans [... and] Justice40 requirements”.
This probably explains the NSF panel suspensions as well.
This probably explains the NSF panel suspensions as well.
January 28, 2025 at 2:54 AM
I received an email from the Department of Energy stating that “DOE is moving aggressively to implement this Executive Order by directing the suspension of [...] DEI policies [...] Community Benefits Plans [... and] Justice40 requirements”.
This probably explains the NSF panel suspensions as well.
This probably explains the NSF panel suspensions as well.
Reposted by Roy Fox

Want a job in robotics in New York? faunarobotics.com

January 7, 2025 at 1:17 AM
Want a job in robotics in New York? faunarobotics.com
Our 2024 research review isn't complete without mentioning 2 workshop papers that preview upcoming publications; I'll leave other things happening as surprises for 2025.
December 31, 2024 at 8:03 PM
Our 2024 research review isn't complete without mentioning 2 workshop papers that preview upcoming publications; I'll leave other things happening as surprises for 2025.
Last in our 2024 research review: control with efficient safety guarantees. Formal verification methods are very slow, but here's a cool trick to use them for safe control, with minimal slowdown and provable safety guarantees.
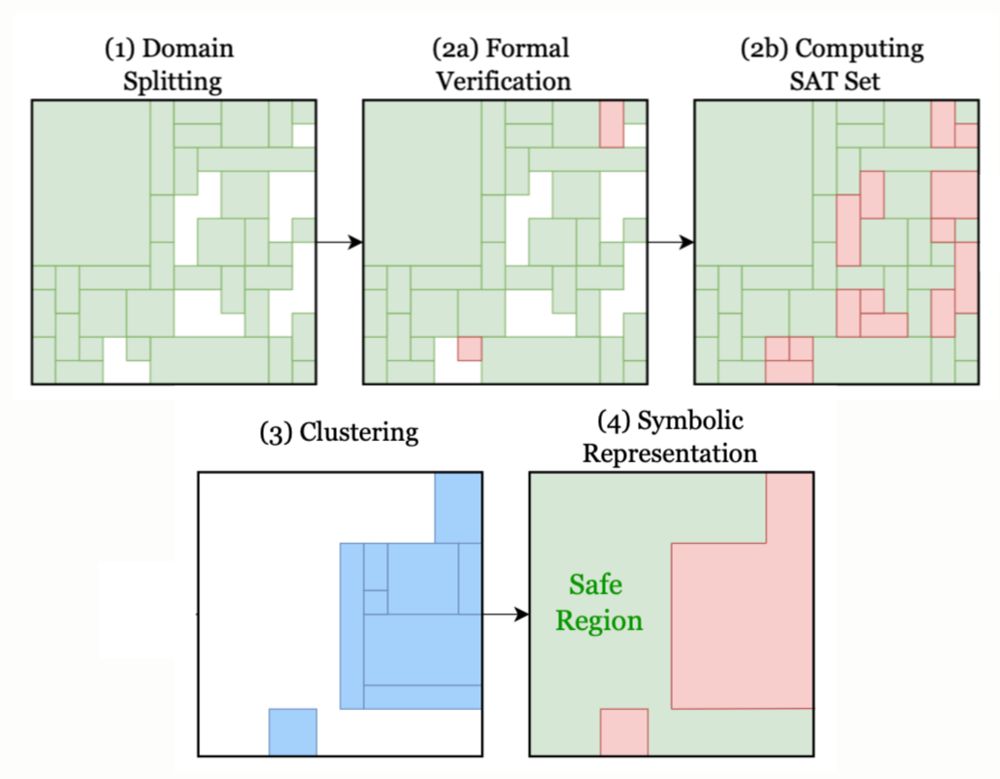
Verification-Guided Shielding for Deep Reinforcement Learning
In recent years, Deep Reinforcement Learning (DRL) has emerged as an effective approach to solving real-world tasks. However, despite their successes, DRL-based policies suffer from poor reliability, ...
indylab.org
December 31, 2024 at 7:43 PM
Last in our 2024 research review: control with efficient safety guarantees. Formal verification methods are very slow, but here's a cool trick to use them for safe control, with minimal slowdown and provable safety guarantees.
Next up in our 2024 research overview: reinforcement learning under delays. The usual control loop assumes immediate observation and action in each time step, but that's not always possible, as processing observations and decisions can take time. How can we learn to control delayed systems?
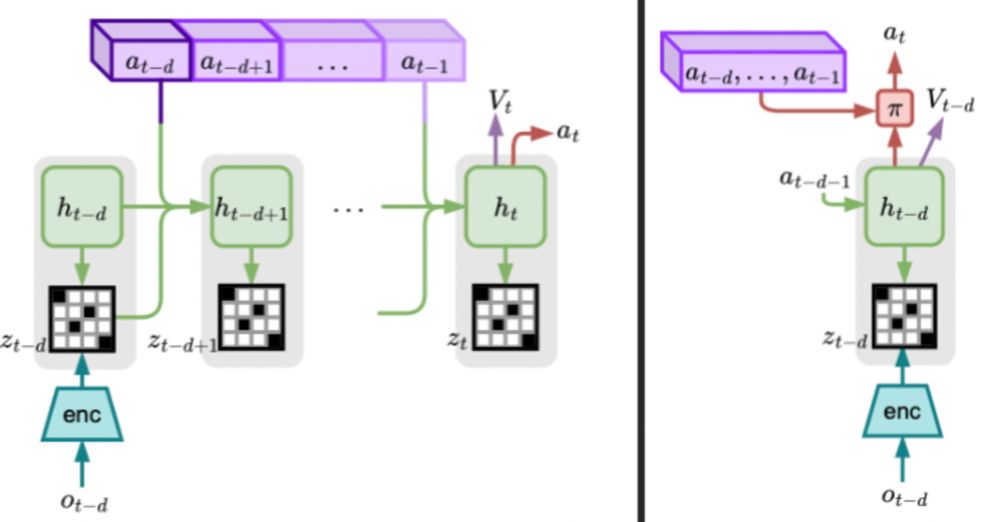
Reinforcement Learning from Delayed Observations via World Models
In standard reinforcement learning settings, agents typically assume immediate feedback about the effects of their actions after taking them. However, in practice, this assumption may not hold true du...
indylab.org
December 30, 2024 at 7:44 PM
Next up in our 2024 research overview: reinforcement learning under delays. The usual control loop assumes immediate observation and action in each time step, but that's not always possible, as processing observations and decisions can take time. How can we learn to control delayed systems?
Way back in 2023, before multimodal foundation models were a thing, we wanted to apply language agents to visual domains. One idea was to use vision models to extract perceptual features and put them into text templates. But “a picture is worth 1000 words” — a big context! Can be slow, distracting.
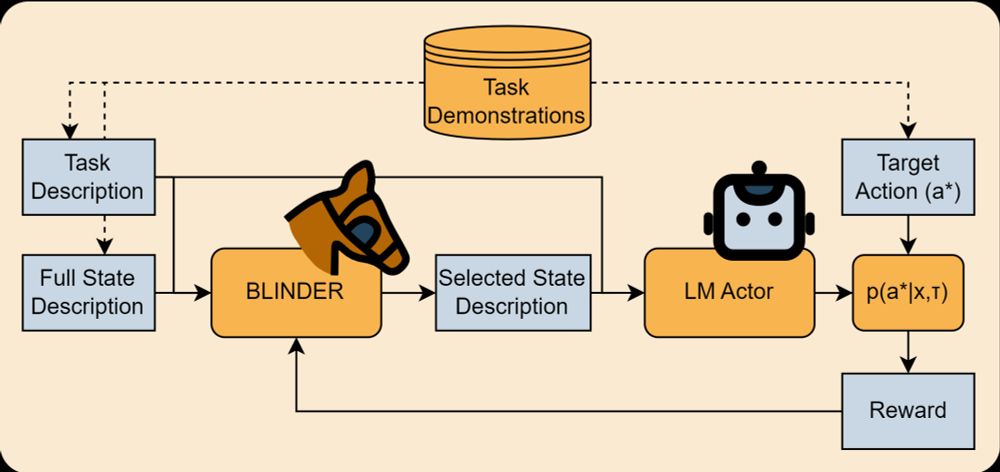
Selective Perception: Learning Concise State Descriptions for Language Model Actors
It is increasingly common for large language models (LLMs) to be applied as actors in sequential decision making problems in embodied domains such as robotics and games, due to their general world kno...
indylab.org
December 16, 2024 at 5:03 PM
Way back in 2023, before multimodal foundation models were a thing, we wanted to apply language agents to visual domains. One idea was to use vision models to extract perceptual features and put them into text templates. But “a picture is worth 1000 words” — a big context! Can be slow, distracting.
Reposted by Roy Fox

To prevent online brain poisoning you should have to have some human interaction before you're allowed to post. If you quote a twitter screenshot you have to borrow a cup of sugar from a neighbor. For every 10K followers you have to explain yourself to a classroom of middle schoolers.
December 15, 2024 at 4:28 AM
To prevent online brain poisoning you should have to have some human interaction before you're allowed to post. If you quote a twitter screenshot you have to borrow a cup of sugar from a neighbor. For every 10K followers you have to explain yourself to a classroom of middle schoolers.
Many are posting end-of-year research summaries, good idea! Let's start:
You want an agent's behavior that can't be exploited by an adversary (zero-sum Nash equilibrium = NE). The world is big, so you restrict the agent to stochastic mixing of a small population. How should you grow the population?
You want an agent's behavior that can't be exploited by an adversary (zero-sum Nash equilibrium = NE). The world is big, so you restrict the agent to stochastic mixing of a small population. How should you grow the population?
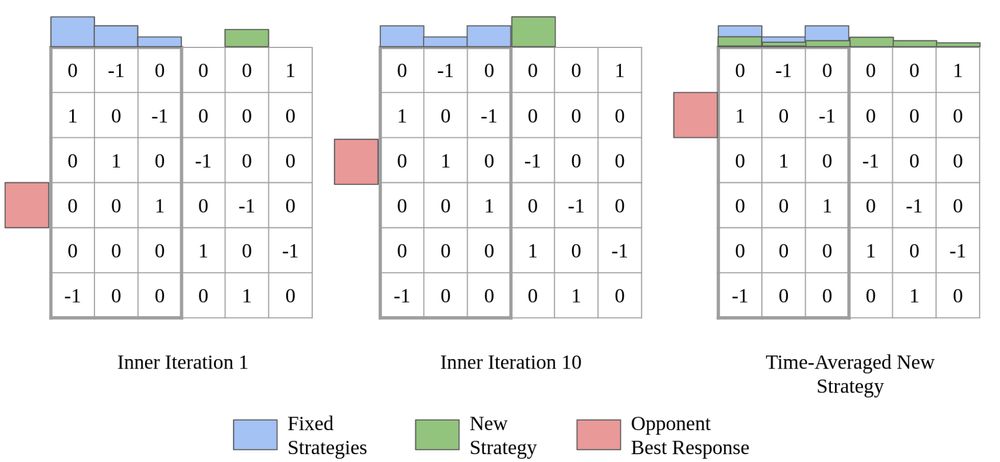
Toward Optimal Policy Population Growth in Two-Player Zero-Sum Games
In competitive two-agent environments, deep reinforcement learning (RL) methods like Policy Space Response Oracles (PSRO) often increase exploitability between iterations, which is problematic when tr...
indylab.org
December 10, 2024 at 3:27 PM
Many are posting end-of-year research summaries, good idea! Let's start:
You want an agent's behavior that can't be exploited by an adversary (zero-sum Nash equilibrium = NE). The world is big, so you restrict the agent to stochastic mixing of a small population. How should you grow the population?
You want an agent's behavior that can't be exploited by an adversary (zero-sum Nash equilibrium = NE). The world is big, so you restrict the agent to stochastic mixing of a small population. How should you grow the population?