


@riverdong.bsky.social
Overall, our work introduces a multi-faceted evaluation framework for LLM personalization. We hope our framework and empirical insights will guide the development of more robust, inclusive, and responsible personalization approaches that can better serve diverse global users.
March 5, 2025 at 4:05 PM
Overall, our work introduces a multi-faceted evaluation framework for LLM personalization. We hope our framework and empirical insights will guide the development of more robust, inclusive, and responsible personalization approaches that can better serve diverse global users.
⚖️ Personalization Can Protect Minority Viewpoints!
In diverse-user settings, personalization helps amplify underrepresented perspectives (User 8 in the Figure). Without personalization, models tend to default to majority opinions, sidelining minority viewpoints.
In diverse-user settings, personalization helps amplify underrepresented perspectives (User 8 in the Figure). Without personalization, models tend to default to majority opinions, sidelining minority viewpoints.

March 5, 2025 at 4:05 PM
⚖️ Personalization Can Protect Minority Viewpoints!
In diverse-user settings, personalization helps amplify underrepresented perspectives (User 8 in the Figure). Without personalization, models tend to default to majority opinions, sidelining minority viewpoints.
In diverse-user settings, personalization helps amplify underrepresented perspectives (User 8 in the Figure). Without personalization, models tend to default to majority opinions, sidelining minority viewpoints.
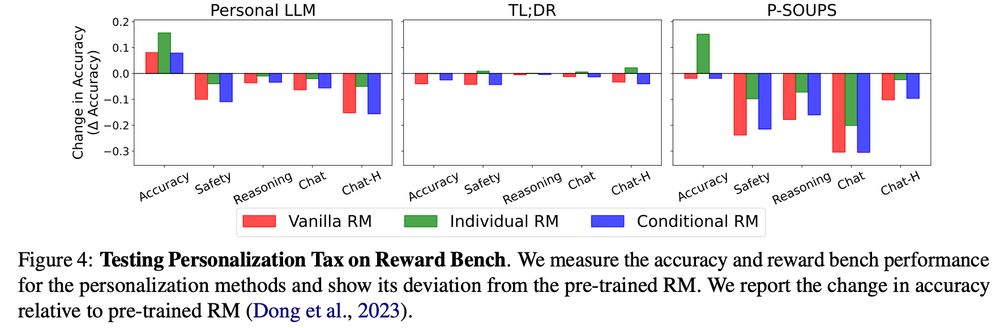
⚠️ Personalization can hurt model safety & reasoning by up to 30%.
March 5, 2025 at 4:04 PM
⚠️ Personalization can hurt model safety & reasoning by up to 30%.
📊 Key Findings:
(1) Performance can vary by up to 36%
(2) Fine-tuning per user is a strong baseline
(3) For the recently proposed algorithms: Personalized Reward Modeling (PRM) achieves best performance. Group Preference Optimization (GPO) show fast adaptation to new users.
(1) Performance can vary by up to 36%
(2) Fine-tuning per user is a strong baseline
(3) For the recently proposed algorithms: Personalized Reward Modeling (PRM) achieves best performance. Group Preference Optimization (GPO) show fast adaptation to new users.

March 5, 2025 at 4:04 PM
📊 Key Findings:
(1) Performance can vary by up to 36%
(2) Fine-tuning per user is a strong baseline
(3) For the recently proposed algorithms: Personalized Reward Modeling (PRM) achieves best performance. Group Preference Optimization (GPO) show fast adaptation to new users.
(1) Performance can vary by up to 36%
(2) Fine-tuning per user is a strong baseline
(3) For the recently proposed algorithms: Personalized Reward Modeling (PRM) achieves best performance. Group Preference Optimization (GPO) show fast adaptation to new users.
Dataset Characteristics Matter!
📌 OpenAI Reddit Summarization → Higher annotator agreement, minimal personalization needed.
📌 P-SOUPS → Strong user disagreement, useful for testing but unrealistic.
📌Personal-LLM → imbalance between majority & minority preference
📌 OpenAI Reddit Summarization → Higher annotator agreement, minimal personalization needed.
📌 P-SOUPS → Strong user disagreement, useful for testing but unrealistic.
📌Personal-LLM → imbalance between majority & minority preference
March 5, 2025 at 4:03 PM
Dataset Characteristics Matter!
📌 OpenAI Reddit Summarization → Higher annotator agreement, minimal personalization needed.
📌 P-SOUPS → Strong user disagreement, useful for testing but unrealistic.
📌Personal-LLM → imbalance between majority & minority preference
📌 OpenAI Reddit Summarization → Higher annotator agreement, minimal personalization needed.
📌 P-SOUPS → Strong user disagreement, useful for testing but unrealistic.
📌Personal-LLM → imbalance between majority & minority preference
🚀 Thrilled to share our paper: "A Multi-Faceted Analysis of Personalized Preference Learning." We introduce a multi-faceted framework to evaluate personalized preference learning algorithms in real-world conditions.
📄 Paper: arxiv.org/pdf/2502.19158
📄 Paper: arxiv.org/pdf/2502.19158
arxiv.org
March 5, 2025 at 4:03 PM
🚀 Thrilled to share our paper: "A Multi-Faceted Analysis of Personalized Preference Learning." We introduce a multi-faceted framework to evaluate personalized preference learning algorithms in real-world conditions.
📄 Paper: arxiv.org/pdf/2502.19158
📄 Paper: arxiv.org/pdf/2502.19158