




Qwen released QvQ 72B OpenAI o1 like reasoning model on Hugging Face with Vision capabilities - beating GPT4o, Claude Sonnet 3.5 🔥

December 24, 2024 at 5:25 PM
Qwen released QvQ 72B OpenAI o1 like reasoning model on Hugging Face with Vision capabilities - beating GPT4o, Claude Sonnet 3.5 🔥
BOOOOM! Meta released Llama 3.3 70B - 128K context, multilingual, enhanced tool calling, outperforms Llama 3.1 70B and comparable to Llama 405B 🔥
Comparable performance to 405B with 6x LESSER parameters ⚡
Comparable performance to 405B with 6x LESSER parameters ⚡

December 6, 2024 at 6:19 PM
BOOOOM! Meta released Llama 3.3 70B - 128K context, multilingual, enhanced tool calling, outperforms Llama 3.1 70B and comparable to Llama 405B 🔥
Comparable performance to 405B with 6x LESSER parameters ⚡
Comparable performance to 405B with 6x LESSER parameters ⚡
Introducing Indic-Parler TTS - Trained on 10K hours of data, 938M params, supports 20 Indic languages, emotional synthesis, apache 2.0 licensed! 🔥
w/ fully customisable speech and voice personas!
Try it out directly below or use the model weights as you want!
🇮🇳/acc
w/ fully customisable speech and voice personas!
Try it out directly below or use the model weights as you want!
🇮🇳/acc

December 3, 2024 at 9:31 PM
Introducing Indic-Parler TTS - Trained on 10K hours of data, 938M params, supports 20 Indic languages, emotional synthesis, apache 2.0 licensed! 🔥
w/ fully customisable speech and voice personas!
Try it out directly below or use the model weights as you want!
🇮🇳/acc
w/ fully customisable speech and voice personas!
Try it out directly below or use the model weights as you want!
🇮🇳/acc
you can just do things - ask AI to create your SQL queries and execute them right in your browser! 🔥
let your creativity guide you - powered by qwen 2.5 coder 32b ⚡
available on all 254,746 public datasets on the hub!
go check it out today! 🤗
let your creativity guide you - powered by qwen 2.5 coder 32b ⚡
available on all 254,746 public datasets on the hub!
go check it out today! 🤗
December 2, 2024 at 2:41 PM
you can just do things - ask AI to create your SQL queries and execute them right in your browser! 🔥
let your creativity guide you - powered by qwen 2.5 coder 32b ⚡
available on all 254,746 public datasets on the hub!
go check it out today! 🤗
let your creativity guide you - powered by qwen 2.5 coder 32b ⚡
available on all 254,746 public datasets on the hub!
go check it out today! 🤗
Reposted by vb

This demo of structured data extraction running on an LLM that executes entirely in the browser (Chrome only for the moment since it uses WebGPU) is amazing
My notes here: simonwillison.net/2024/Nov/29/...
My notes here: simonwillison.net/2024/Nov/29/...
November 29, 2024 at 9:10 PM
This demo of structured data extraction running on an LLM that executes entirely in the browser (Chrome only for the moment since it uses WebGPU) is amazing
My notes here: simonwillison.net/2024/Nov/29/...
My notes here: simonwillison.net/2024/Nov/29/...
Fuck it! Structured Generation w/ SmolLM2 running in browser & WebGPU 🔥
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser - profit!!
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser - profit!!
November 28, 2024 at 10:24 PM
Fuck it! Structured Generation w/ SmolLM2 running in browser & WebGPU 🔥
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser - profit!!
Powered by MLC Web-LLM & XGrammar ⚡
Define a JSON schema, Input free text, get structured data right in your browser - profit!!
Reposted by vb

FYI, here's the entire code to create a dataset of every single bsky message in real time:
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
November 28, 2024 at 9:56 AM
FYI, here's the entire code to create a dataset of every single bsky message in real time:
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
Reposted by vb

I have converted a portion of my NLP Online Masters course to blog form. This is the progression I present that takes one from recurrent neural network to seq2seq with attention to transformer. mark-riedl.medium.com/transformers...
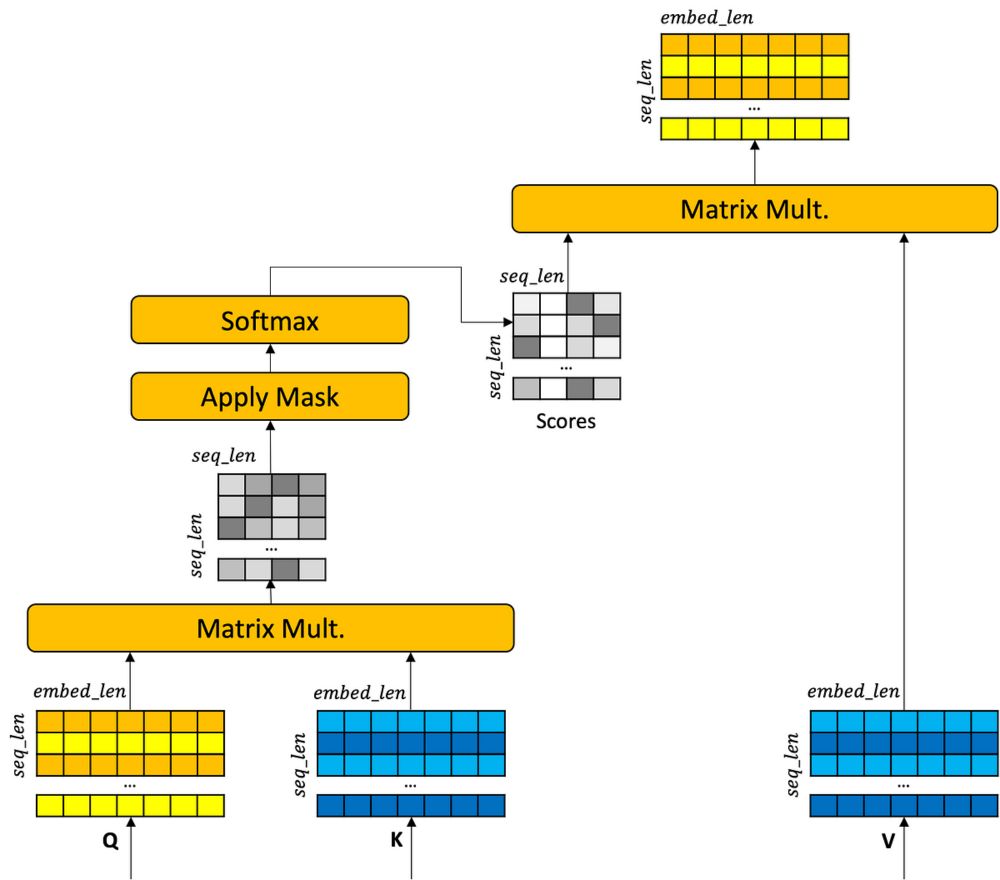
Transformers: Origins
An unofficial origin story of the transformer neural network architecture.
mark-riedl.medium.com
November 26, 2024 at 2:15 AM
I have converted a portion of my NLP Online Masters course to blog form. This is the progression I present that takes one from recurrent neural network to seq2seq with attention to transformer. mark-riedl.medium.com/transformers...
Reposted by vb

I'm disheartened by how toxic and violent some responses were here.
There was a mistake, a quick follow up to mitigate and an apology. I worked with Daniel for years and is one of the persons most preoccupied with ethical implications of AI. Some replies are Reddit-toxic level. We need empathy.
There was a mistake, a quick follow up to mitigate and an apology. I worked with Daniel for years and is one of the persons most preoccupied with ethical implications of AI. Some replies are Reddit-toxic level. We need empathy.

I've removed the Bluesky data from the repo. While I wanted to support tool development for the platform, I recognize this approach violated principles of transparency and consent in data collection. I apologize for this mistake.
First dataset for the new @huggingface.bsky.social @bsky.app community organisation: one-million-bluesky-posts 🦋
📊 1M public posts from Bluesky's firehose API
🔍 Includes text, metadata, and language predictions
🔬 Perfect to experiment with using ML for Bluesky 🤗
huggingface.co/datasets/blu...
📊 1M public posts from Bluesky's firehose API
🔍 Includes text, metadata, and language predictions
🔬 Perfect to experiment with using ML for Bluesky 🤗
huggingface.co/datasets/blu...
November 27, 2024 at 11:09 AM
I'm disheartened by how toxic and violent some responses were here.
There was a mistake, a quick follow up to mitigate and an apology. I worked with Daniel for years and is one of the persons most preoccupied with ethical implications of AI. Some replies are Reddit-toxic level. We need empathy.
There was a mistake, a quick follow up to mitigate and an apology. I worked with Daniel for years and is one of the persons most preoccupied with ethical implications of AI. Some replies are Reddit-toxic level. We need empathy.
yo! nvidia finally released the weights for Hymba-1.5B - outperforms Qwen, and SmolLM2 w/ 6-12x less training
trained ONLY on 1.5T tokens
> massive reductions in KV cache size and improved throughput
> combines Mamba and Attention in a hybrid parallel architecture with a 5:1 ratio and meta-tokens
trained ONLY on 1.5T tokens
> massive reductions in KV cache size and improved throughput
> combines Mamba and Attention in a hybrid parallel architecture with a 5:1 ratio and meta-tokens

November 26, 2024 at 7:34 PM
yo! nvidia finally released the weights for Hymba-1.5B - outperforms Qwen, and SmolLM2 w/ 6-12x less training
trained ONLY on 1.5T tokens
> massive reductions in KV cache size and improved throughput
> combines Mamba and Attention in a hybrid parallel architecture with a 5:1 ratio and meta-tokens
trained ONLY on 1.5T tokens
> massive reductions in KV cache size and improved throughput
> combines Mamba and Attention in a hybrid parallel architecture with a 5:1 ratio and meta-tokens
Reposted by vb

Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!

November 26, 2024 at 3:57 PM
Let's go! We are releasing SmolVLM, a smol 2B VLM built for on-device inference that outperforms all models at similar GPU RAM usage and tokens throughputs.
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
SmolVLM can be fine-tuned on a Google collab and be run on a laptop! Or process millions of documents with a consumer GPU!
Smol TTS keeps getting better! Introducing OuteTTS v0.2 - 500M parameters, multilingual with voice cloning! 🔥
> Multilingual - English, Chinese, Korean & Japanese
> Cross platform inference w/ llama.cpp
> Trained on 5 Billion audio tokens
> Qwen 2.5 0.5B LLM backbone
> Trained via HF GPU grants
> Multilingual - English, Chinese, Korean & Japanese
> Cross platform inference w/ llama.cpp
> Trained on 5 Billion audio tokens
> Qwen 2.5 0.5B LLM backbone
> Trained via HF GPU grants
November 25, 2024 at 9:32 PM
Smol TTS keeps getting better! Introducing OuteTTS v0.2 - 500M parameters, multilingual with voice cloning! 🔥
> Multilingual - English, Chinese, Korean & Japanese
> Cross platform inference w/ llama.cpp
> Trained on 5 Billion audio tokens
> Qwen 2.5 0.5B LLM backbone
> Trained via HF GPU grants
> Multilingual - English, Chinese, Korean & Japanese
> Cross platform inference w/ llama.cpp
> Trained on 5 Billion audio tokens
> Qwen 2.5 0.5B LLM backbone
> Trained via HF GPU grants
SmolLM - run, pre-train, fine-tune, evaluate SoTA fully open source LM 🔥
Run with Transformers, MLX, Transformers.js, MLC Web-LLM, Ollama, Candle and more!
Apache 2.0 licensed codebase - go explore now!
Run with Transformers, MLX, Transformers.js, MLC Web-LLM, Ollama, Candle and more!
Apache 2.0 licensed codebase - go explore now!

November 25, 2024 at 1:17 PM
SmolLM - run, pre-train, fine-tune, evaluate SoTA fully open source LM 🔥
Run with Transformers, MLX, Transformers.js, MLC Web-LLM, Ollama, Candle and more!
Apache 2.0 licensed codebase - go explore now!
Run with Transformers, MLX, Transformers.js, MLC Web-LLM, Ollama, Candle and more!
Apache 2.0 licensed codebase - go explore now!
Massive week for Open Source AI/ ML
Mistral Pixtral & Instruct Large - ~123B, 128K context, multilingual, json + function calling & open weights
Allen AI Tülu 70B & 8B - competive with claude 3.5 haiku, beats all major open models like llama 3.1 70B, qwen 2.5 and nemotron
Mistral Pixtral & Instruct Large - ~123B, 128K context, multilingual, json + function calling & open weights
Allen AI Tülu 70B & 8B - competive with claude 3.5 haiku, beats all major open models like llama 3.1 70B, qwen 2.5 and nemotron

November 24, 2024 at 8:12 PM
Massive week for Open Source AI/ ML
Mistral Pixtral & Instruct Large - ~123B, 128K context, multilingual, json + function calling & open weights
Allen AI Tülu 70B & 8B - competive with claude 3.5 haiku, beats all major open models like llama 3.1 70B, qwen 2.5 and nemotron
Mistral Pixtral & Instruct Large - ~123B, 128K context, multilingual, json + function calling & open weights
Allen AI Tülu 70B & 8B - competive with claude 3.5 haiku, beats all major open models like llama 3.1 70B, qwen 2.5 and nemotron
Apple released blazingly fast CoreML models AND an iOS app to run them on iPhone! ⚡
> S0 matches OpenAI's ViT-B/16 in zero-shot performance but is 4.8x faster and 2.8x smaller
> S2 outperforms SigLIP's ViT-B/16 in zero-shot accuracy, being 2.3x faster, 2.1x smaller, and trained with 3x fewer data
> S0 matches OpenAI's ViT-B/16 in zero-shot performance but is 4.8x faster and 2.8x smaller
> S2 outperforms SigLIP's ViT-B/16 in zero-shot accuracy, being 2.3x faster, 2.1x smaller, and trained with 3x fewer data

November 23, 2024 at 4:22 PM
Apple released blazingly fast CoreML models AND an iOS app to run them on iPhone! ⚡
> S0 matches OpenAI's ViT-B/16 in zero-shot performance but is 4.8x faster and 2.8x smaller
> S2 outperforms SigLIP's ViT-B/16 in zero-shot accuracy, being 2.3x faster, 2.1x smaller, and trained with 3x fewer data
> S0 matches OpenAI's ViT-B/16 in zero-shot performance but is 4.8x faster and 2.8x smaller
> S2 outperforms SigLIP's ViT-B/16 in zero-shot accuracy, being 2.3x faster, 2.1x smaller, and trained with 3x fewer data
Check out my new swanky handle! 🦋 - Drop your Hugging Face ID in the comments if you want the same!

November 23, 2024 at 3:01 PM
Check out my new swanky handle! 🦋 - Drop your Hugging Face ID in the comments if you want the same!
LFG!! XGrammar: a lightning fast, flexible, and portable engine for structured generation! 🔥
> Accurate JSON/grammar generation
> 3-10x speedup in latency
> 14x faster JSON-schema generation and up to 80x CFG-guided generation
GG MLC team is literally the best in the game and slept on! ⚡
> Accurate JSON/grammar generation
> 3-10x speedup in latency
> 14x faster JSON-schema generation and up to 80x CFG-guided generation
GG MLC team is literally the best in the game and slept on! ⚡
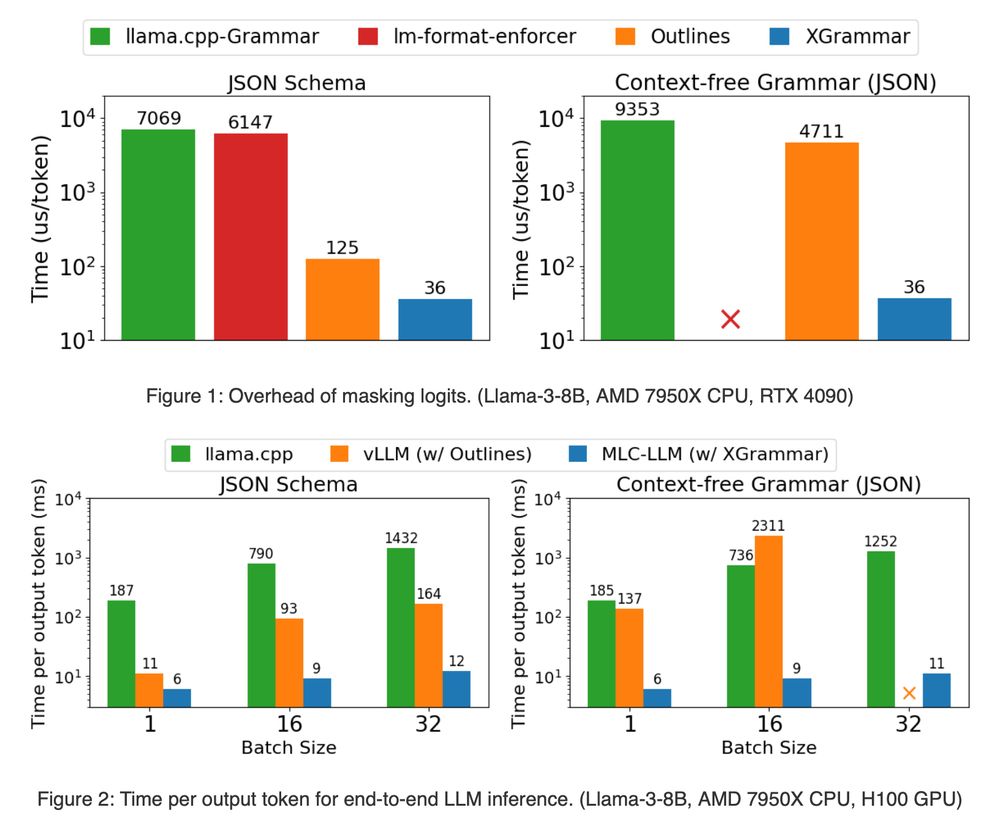
November 22, 2024 at 9:21 PM
LFG!! XGrammar: a lightning fast, flexible, and portable engine for structured generation! 🔥
> Accurate JSON/grammar generation
> 3-10x speedup in latency
> 14x faster JSON-schema generation and up to 80x CFG-guided generation
GG MLC team is literally the best in the game and slept on! ⚡
> Accurate JSON/grammar generation
> 3-10x speedup in latency
> 14x faster JSON-schema generation and up to 80x CFG-guided generation
GG MLC team is literally the best in the game and slept on! ⚡
🚨 UPDATE: New Whisper based model competing with Nvidia on Open ASR Leaderboard! 🔥
CrisperWhisper aims to transcribe every spoken word exactly as it is, including fillers, pauses, stutters and false starts
Whisper Large V3 fine-tune - beats it by roughly ~1 WER margin ⚡
hf.co/spaces/hf-au...
CrisperWhisper aims to transcribe every spoken word exactly as it is, including fillers, pauses, stutters and false starts
Whisper Large V3 fine-tune - beats it by roughly ~1 WER margin ⚡
hf.co/spaces/hf-au...
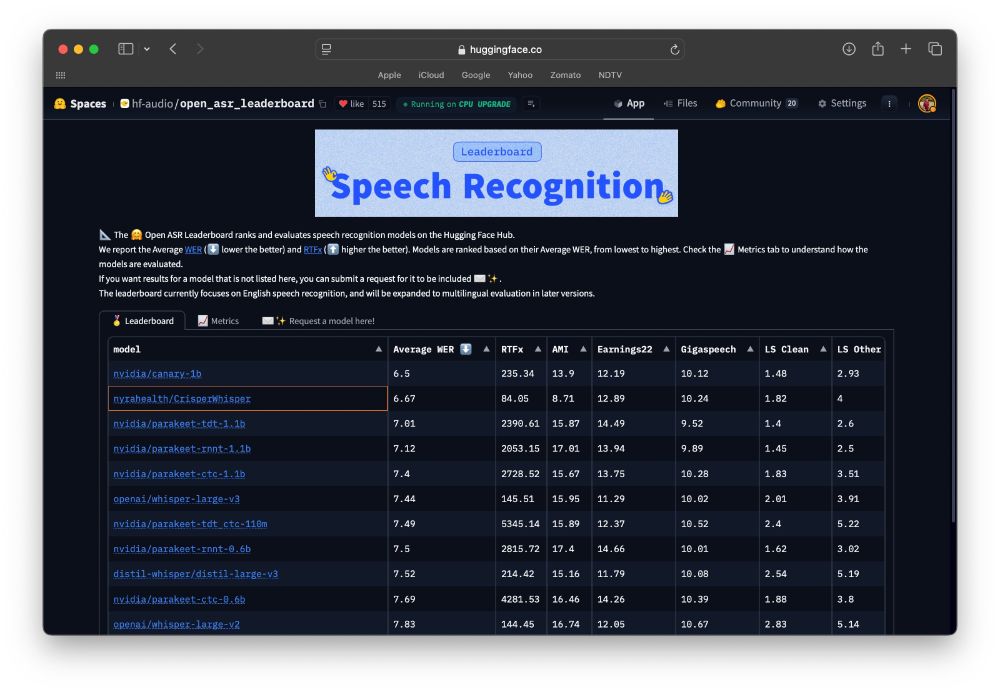
November 20, 2024 at 10:45 PM
🚨 UPDATE: New Whisper based model competing with Nvidia on Open ASR Leaderboard! 🔥
CrisperWhisper aims to transcribe every spoken word exactly as it is, including fillers, pauses, stutters and false starts
Whisper Large V3 fine-tune - beats it by roughly ~1 WER margin ⚡
hf.co/spaces/hf-au...
CrisperWhisper aims to transcribe every spoken word exactly as it is, including fillers, pauses, stutters and false starts
Whisper Large V3 fine-tune - beats it by roughly ~1 WER margin ⚡
hf.co/spaces/hf-au...
OH WOW! The Whale aka DeepSeek is BACK!! New model, with complete reasoning outputs and a gracious FREE TIER too! 🔥
Here's a quick snippet of it searching the web for the right documentation, creating the JS files plus the necessary HTML all whilst handling Auth too ⚡
Here's a quick snippet of it searching the web for the right documentation, creating the JS files plus the necessary HTML all whilst handling Auth too ⚡

November 20, 2024 at 11:42 AM
OH WOW! The Whale aka DeepSeek is BACK!! New model, with complete reasoning outputs and a gracious FREE TIER too! 🔥
Here's a quick snippet of it searching the web for the right documentation, creating the JS files plus the necessary HTML all whilst handling Auth too ⚡
Here's a quick snippet of it searching the web for the right documentation, creating the JS files plus the necessary HTML all whilst handling Auth too ⚡
Great day for M/LLMs, just released Mistral & Pixtral Large - ~123B, 128K context, Multilingual, JSON + Function calling support & open weights! 🔥
Pixtral Large: huggingface.co/mistralai/Pi...
Mistral Large: huggingface.co/mistralai/Mi...
Pixtral Large: huggingface.co/mistralai/Pi...
Mistral Large: huggingface.co/mistralai/Mi...
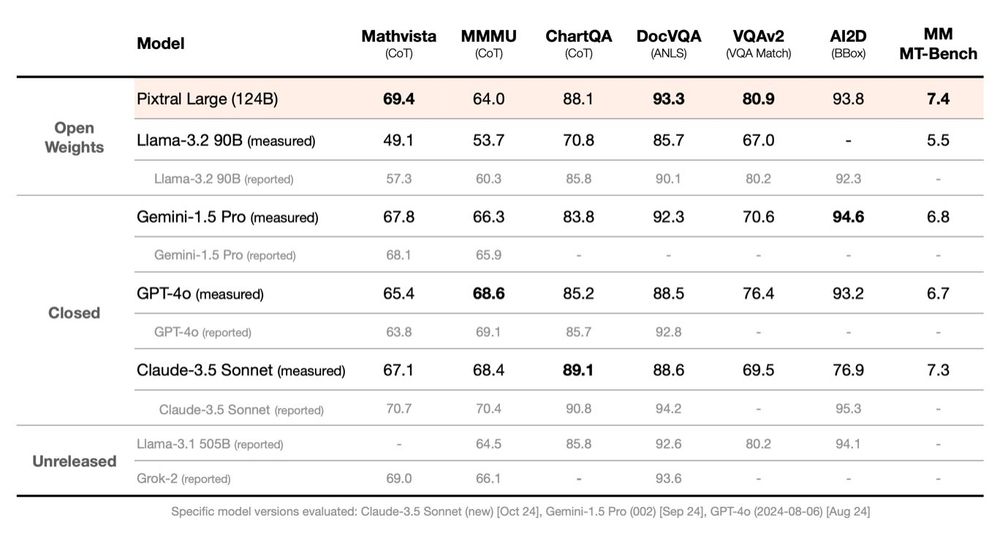
November 18, 2024 at 5:40 PM
Great day for M/LLMs, just released Mistral & Pixtral Large - ~123B, 128K context, Multilingual, JSON + Function calling support & open weights! 🔥
Pixtral Large: huggingface.co/mistralai/Pi...
Mistral Large: huggingface.co/mistralai/Mi...
Pixtral Large: huggingface.co/mistralai/Pi...
Mistral Large: huggingface.co/mistralai/Mi...
New spaces of the week! 🔥
> Qwen 2.5 Coder Artifacts
> Flux Kolors Character
> X Potrait
> Text Behind Image 🤯
> DimensionX
> MagicQuill
> JanusFlow 1.3B
> Netflix Recommentation
Check them out at hf.co/spaces 🏃
> Qwen 2.5 Coder Artifacts
> Flux Kolors Character
> X Potrait
> Text Behind Image 🤯
> DimensionX
> MagicQuill
> JanusFlow 1.3B
> Netflix Recommentation
Check them out at hf.co/spaces 🏃

November 18, 2024 at 11:23 AM
New spaces of the week! 🔥
> Qwen 2.5 Coder Artifacts
> Flux Kolors Character
> X Potrait
> Text Behind Image 🤯
> DimensionX
> MagicQuill
> JanusFlow 1.3B
> Netflix Recommentation
Check them out at hf.co/spaces 🏃
> Qwen 2.5 Coder Artifacts
> Flux Kolors Character
> X Potrait
> Text Behind Image 🤯
> DimensionX
> MagicQuill
> JanusFlow 1.3B
> Netflix Recommentation
Check them out at hf.co/spaces 🏃
What a brilliant week in Open Source!

November 17, 2024 at 9:09 PM
What a brilliant week in Open Source!
🚨 Nexusflow released Athene v2 72B - competitive with GPT4o & Llama 3.1 405B Chat, Code and Math 🔥
> Arena Hard: GPT4o (84.9) vs Athene v2 (77.9) vs L3.1 405B (69.3)
> Bigcode-Bench Hard: 30.8 vs 31.4 vs 26.4
> MATH: 76.6 vs 83 vs 73.8
Open science ftw! ⚡
> Arena Hard: GPT4o (84.9) vs Athene v2 (77.9) vs L3.1 405B (69.3)
> Bigcode-Bench Hard: 30.8 vs 31.4 vs 26.4
> MATH: 76.6 vs 83 vs 73.8
Open science ftw! ⚡

November 15, 2024 at 9:41 AM
🚨 Nexusflow released Athene v2 72B - competitive with GPT4o & Llama 3.1 405B Chat, Code and Math 🔥
> Arena Hard: GPT4o (84.9) vs Athene v2 (77.9) vs L3.1 405B (69.3)
> Bigcode-Bench Hard: 30.8 vs 31.4 vs 26.4
> MATH: 76.6 vs 83 vs 73.8
Open science ftw! ⚡
> Arena Hard: GPT4o (84.9) vs Athene v2 (77.9) vs L3.1 405B (69.3)
> Bigcode-Bench Hard: 30.8 vs 31.4 vs 26.4
> MATH: 76.6 vs 83 vs 73.8
Open science ftw! ⚡
Smol TTS models are here! OuteTTS-0.1-350M - Zero shot voice cloning, built on LLaMa architecture, CC-BY license! 🔥
> Pure language modeling approach to TTS
> Zero-shot voice cloning
> LLaMa architecture w/ Audio tokens (WavTokenizer)
> BONUS: Works on-device w/ llama.cpp ⚡
> Pure language modeling approach to TTS
> Zero-shot voice cloning
> LLaMa architecture w/ Audio tokens (WavTokenizer)
> BONUS: Works on-device w/ llama.cpp ⚡
November 4, 2024 at 5:19 PM
Smol TTS models are here! OuteTTS-0.1-350M - Zero shot voice cloning, built on LLaMa architecture, CC-BY license! 🔥
> Pure language modeling approach to TTS
> Zero-shot voice cloning
> LLaMa architecture w/ Audio tokens (WavTokenizer)
> BONUS: Works on-device w/ llama.cpp ⚡
> Pure language modeling approach to TTS
> Zero-shot voice cloning
> LLaMa architecture w/ Audio tokens (WavTokenizer)
> BONUS: Works on-device w/ llama.cpp ⚡
Reposted by vb

Our multimodal team is releasing IDEFICS! One year in the making, the first open SOTA visual LLM:
images/text input, text output. Think multimodal ChatGPT!
We release 2 sizes: 80B🐳 & 9B🐿️
Read: https://huggingface.co/blog/idefics
Try: https://huggingface.co/spaces/HuggingFaceM4/idefics_playground
images/text input, text output. Think multimodal ChatGPT!
We release 2 sizes: 80B🐳 & 9B🐿️
Read: https://huggingface.co/blog/idefics
Try: https://huggingface.co/spaces/HuggingFaceM4/idefics_playground

Introducing IDEFICS: An Open Reproduction of State-of-the-art Visual Langage Model
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
August 22, 2023 at 2:35 PM
Our multimodal team is releasing IDEFICS! One year in the making, the first open SOTA visual LLM:
images/text input, text output. Think multimodal ChatGPT!
We release 2 sizes: 80B🐳 & 9B🐿️
Read: https://huggingface.co/blog/idefics
Try: https://huggingface.co/spaces/HuggingFaceM4/idefics_playground
images/text input, text output. Think multimodal ChatGPT!
We release 2 sizes: 80B🐳 & 9B🐿️
Read: https://huggingface.co/blog/idefics
Try: https://huggingface.co/spaces/HuggingFaceM4/idefics_playground