



Raju Penmatsa
@rajuptvs.bsky.social
Reposted by Raju Penmatsa

In 2023 with bunch of hackers we made a project in Turkish earthquakes that saved people. Powered by HF compute with open-source models by Google
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
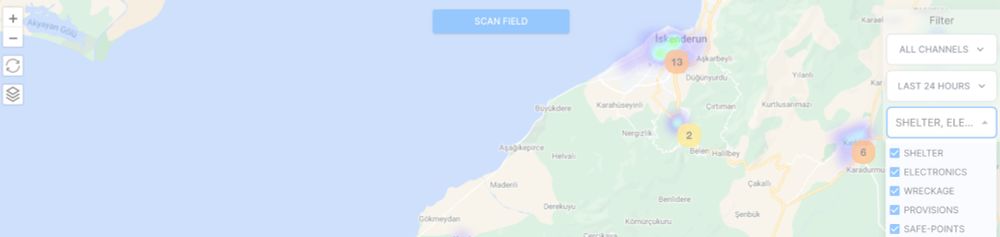
Using Machine Learning to Aid Survivors and Race through Time
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
hf.co
November 27, 2024 at 3:33 PM
In 2023 with bunch of hackers we made a project in Turkish earthquakes that saved people. Powered by HF compute with open-source models by Google
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
But I think we can still change the default from concise to other. I definitely remember doing that.
definitely worth a shot.
definitely worth a shot.
November 22, 2024 at 3:32 AM
But I think we can still change the default from concise to other. I definitely remember doing that.
definitely worth a shot.
definitely worth a shot.
this has a lot of parallels to this.
arxiv.org/abs/2410.02089
arxiv.org/abs/2410.02089

RLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their gene...
arxiv.org
November 21, 2024 at 5:54 PM
this has a lot of parallels to this.
arxiv.org/abs/2410.02089
arxiv.org/abs/2410.02089
sorry my bad. just saw this on the post,
looks like this is gonna be explored in future.
open.substack.com/pub/robotic/...
looks like this is gonna be explored in future.
open.substack.com/pub/robotic/...

Tülu 3: The next era in open post-training
We give you open-source, frontier-model post-training.
open.substack.com
November 21, 2024 at 5:51 PM
sorry my bad. just saw this on the post,
looks like this is gonna be explored in future.
open.substack.com/pub/robotic/...
looks like this is gonna be explored in future.
open.substack.com/pub/robotic/...
Code might have a lot of overhead in computation, but since code has shown to increase model generalization capabilities over time.
Also this might help model learn, why some code was wrong if there is error and can correct itself.
Also this might help model learn, why some code was wrong if there is error and can correct itself.
November 21, 2024 at 5:43 PM
Code might have a lot of overhead in computation, but since code has shown to increase model generalization capabilities over time.
Also this might help model learn, why some code was wrong if there is error and can correct itself.
Also this might help model learn, why some code was wrong if there is error and can correct itself.
looks very interesting, and on quick glance makes a lot of sense. especially the verifiable rewards part of it.
Is there an extension to this where, it includes code generation and execution feedback is taken into account for RL.
Is there an extension to this where, it includes code generation and execution feedback is taken into account for RL.
November 21, 2024 at 5:39 PM
looks very interesting, and on quick glance makes a lot of sense. especially the verifiable rewards part of it.
Is there an extension to this where, it includes code generation and execution feedback is taken into account for RL.
Is there an extension to this where, it includes code generation and execution feedback is taken into account for RL.
for me i really think, this preview is a way to collect user data and usage pattern, and hone in the RL policy that was used during training on user queries.
this for me is a typical ml practice.. where you deploy the model, collect user feedback and iterate and curate similar datasets and iterate.
this for me is a typical ml practice.. where you deploy the model, collect user feedback and iterate and curate similar datasets and iterate.
November 21, 2024 at 5:35 PM
for me i really think, this preview is a way to collect user data and usage pattern, and hone in the RL policy that was used during training on user queries.
this for me is a typical ml practice.. where you deploy the model, collect user feedback and iterate and curate similar datasets and iterate.
this for me is a typical ml practice.. where you deploy the model, collect user feedback and iterate and curate similar datasets and iterate.
keyboard looks dope !!
November 21, 2024 at 5:31 PM
keyboard looks dope !!
thanks a lot for this.. will check it out..
November 18, 2024 at 7:05 PM
thanks a lot for this.. will check it out..
thanks for this much needed atm !! Kudos to the team!!
November 18, 2024 at 6:59 PM
thanks for this much needed atm !! Kudos to the team!!
at first glance, looks inefficient (i maybe wrong).. looks like the native scaled decoder is trying to cover up for the small image encoder and insufficient signals from them.
But hey.. if it works, it works 😅
But hey.. if it works, it works 😅
November 18, 2024 at 6:58 PM
at first glance, looks inefficient (i maybe wrong).. looks like the native scaled decoder is trying to cover up for the small image encoder and insufficient signals from them.
But hey.. if it works, it works 😅
But hey.. if it works, it works 😅
Lol, so true.. are there any promising papers that show the effect of scaling image encoder.
This seems to be quite disproportionate, image encoder vs other params.
This seems to be quite disproportionate, image encoder vs other params.
November 18, 2024 at 6:55 PM
Lol, so true.. are there any promising papers that show the effect of scaling image encoder.
This seems to be quite disproportionate, image encoder vs other params.
This seems to be quite disproportionate, image encoder vs other params.