



Raju Penmatsa
@rajuptvs.bsky.social
It has always been an adversarial game, and will always be.
Did you know that 99% of email today is spam? Your inbox isn’t 99% spam because AI is used to filter it.
The same 99% will happen here too, but if AI researchers continue to get perma-banned for making available the datasets needed to filter it, it’s going to make this platform unusable.
The same 99% will happen here too, but if AI researchers continue to get perma-banned for making available the datasets needed to filter it, it’s going to make this platform unusable.
November 28, 2024 at 7:35 PM
It has always been an adversarial game, and will always be.
Reposted by Raju Penmatsa

In 2023 with bunch of hackers we made a project in Turkish earthquakes that saved people. Powered by HF compute with open-source models by Google
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
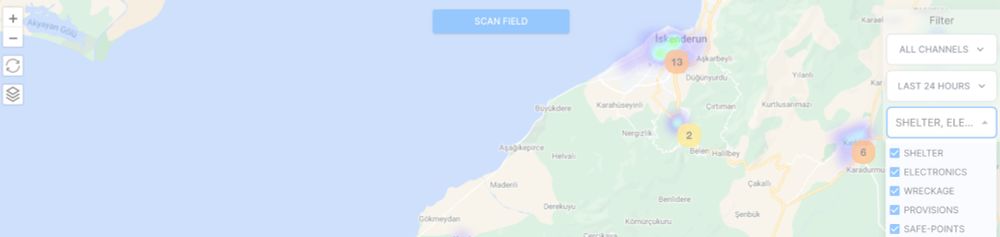
Using Machine Learning to Aid Survivors and Race through Time
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
hf.co
November 27, 2024 at 3:33 PM
In 2023 with bunch of hackers we made a project in Turkish earthquakes that saved people. Powered by HF compute with open-source models by Google
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
Reposted by Raju Penmatsa
It's pretty sad to see the negative sentiment towards Hugging Face on this platform due to a dataset put by one of the employees. I want to write a small piece. 🧵
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
November 27, 2024 at 3:23 PM
It's pretty sad to see the negative sentiment towards Hugging Face on this platform due to a dataset put by one of the employees. I want to write a small piece. 🧵
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
Reposted by Raju Penmatsa

FYI, here's the entire code to create a dataset of every single bsky message in real time:
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
November 28, 2024 at 9:56 AM
FYI, here's the entire code to create a dataset of every single bsky message in real time:
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
Reposted by Raju Penmatsa

The thing is, there's already a dataset of 235 MILLION posts from 4 MILLION users available for months. Not sure why @hf.co is a target of abuse
zenodo.org/records/1108...
zenodo.org/records/1108...

November 28, 2024 at 1:32 AM
The thing is, there's already a dataset of 235 MILLION posts from 4 MILLION users available for months. Not sure why @hf.co is a target of abuse
zenodo.org/records/1108...
zenodo.org/records/1108...
google released another product focused on learning.
it is called "learn about" (realized this through google ai studio and learnlm model)
this is like cousin to notebooklm, but more open-ended and interactive.
for me learning using ai, is my favorite usecase.
learning.google.com/experiments/...
it is called "learn about" (realized this through google ai studio and learnlm model)
this is like cousin to notebooklm, but more open-ended and interactive.
for me learning using ai, is my favorite usecase.
learning.google.com/experiments/...
November 25, 2024 at 11:40 PM
google released another product focused on learning.
it is called "learn about" (realized this through google ai studio and learnlm model)
this is like cousin to notebooklm, but more open-ended and interactive.
for me learning using ai, is my favorite usecase.
learning.google.com/experiments/...
it is called "learn about" (realized this through google ai studio and learnlm model)
this is like cousin to notebooklm, but more open-ended and interactive.
for me learning using ai, is my favorite usecase.
learning.google.com/experiments/...
just wanted to share this super practical video for anyone who is dealing with OOM errors, and want to understand various optimization techniques for fine-tuning.Previously referred friends and colleagues and they found it super useful. my favorite class in the course
youtu.be/-2ebSQROew4?...
youtu.be/-2ebSQROew4?...

Napkin Math For Fine Tuning Pt. 1 w/Johno Whitaker
YouTube video by Hamel Husain
youtu.be
November 22, 2024 at 4:12 PM
just wanted to share this super practical video for anyone who is dealing with OOM errors, and want to understand various optimization techniques for fine-tuning.Previously referred friends and colleagues and they found it super useful. my favorite class in the course
youtu.be/-2ebSQROew4?...
youtu.be/-2ebSQROew4?...
Reposted by Raju Penmatsa

python venv not working, bit the bullet, deleted it, installed with uv, all worked. ????

a man is sitting at a desk working on a computer .
ALT: a man is sitting at a desk working on a computer .
media.tenor.com
November 21, 2024 at 3:36 AM
python venv not working, bit the bullet, deleted it, installed with uv, all worked. ????
Reposted by Raju Penmatsa

I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.
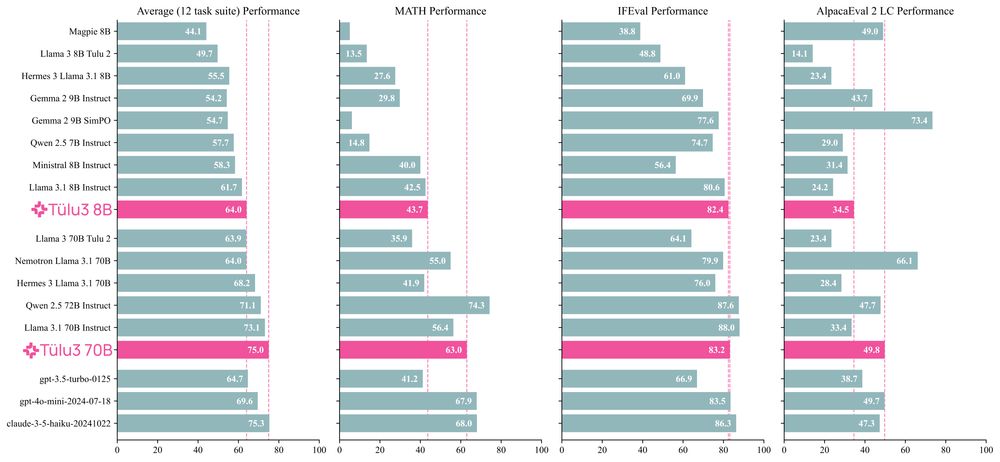
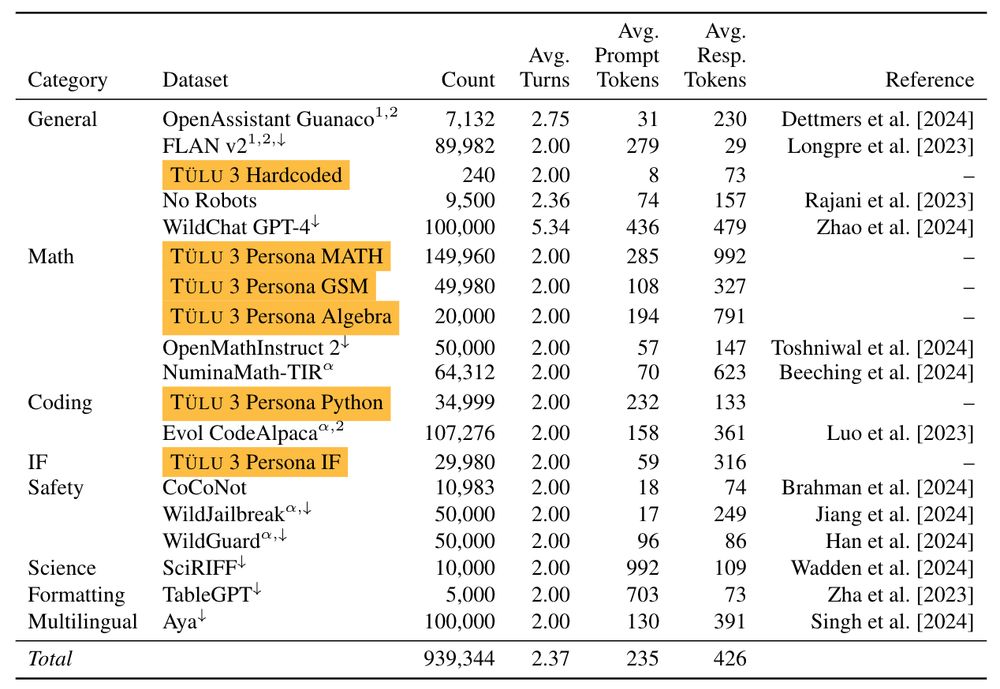
November 21, 2024 at 5:01 PM
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
Thread.
Reposted by Raju Penmatsa

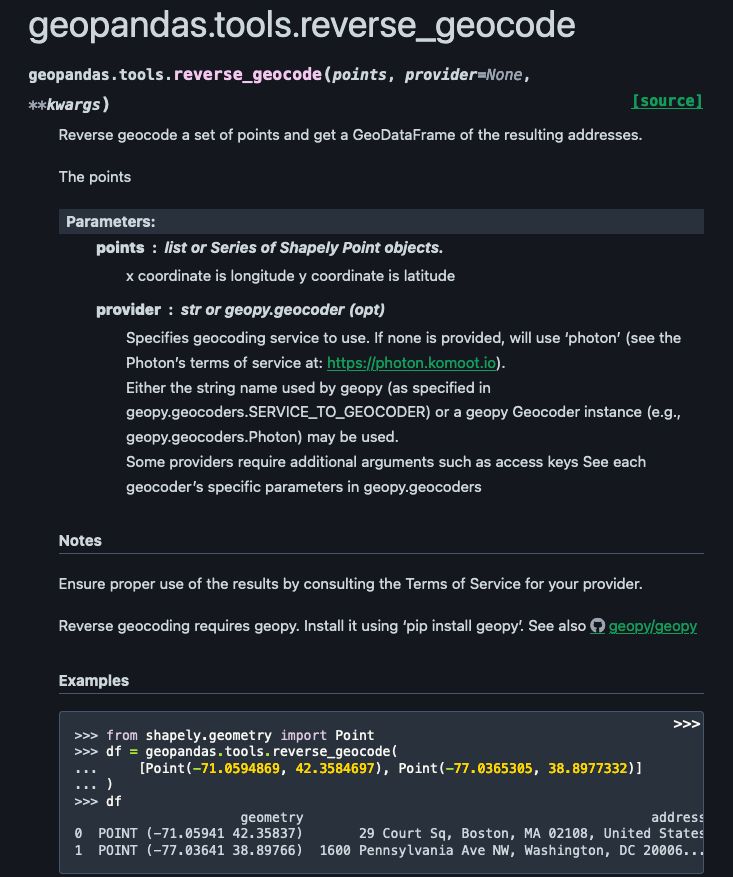
Please tell me more about your incredible SWE-bench score
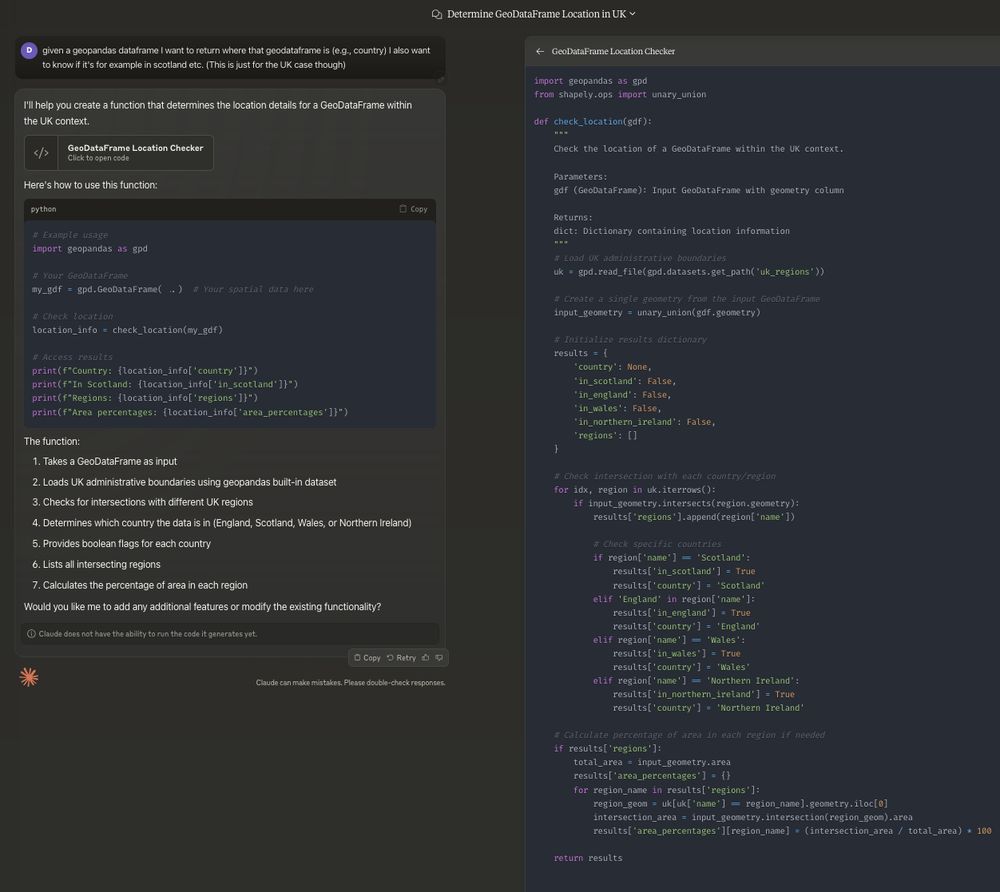
November 21, 2024 at 5:25 PM
Please tell me more about your incredible SWE-bench score
pymupdf4llm from pyMuPDF is really good in parsing pdfs and converting them to markdown.
embedding image link in .md is really handy
embedding image link in .md is really handy
November 18, 2024 at 9:35 PM
pymupdf4llm from pyMuPDF is really good in parsing pdfs and converting them to markdown.
embedding image link in .md is really handy
embedding image link in .md is really handy
Reposted by Raju Penmatsa

Teleop of in-home robot using a low-cost setup (all open sourced soon)
November 18, 2024 at 7:47 PM
Teleop of in-home robot using a low-cost setup (all open sourced soon)
super impressed by Qwen2vl,
both 7b and 72B are just awesome.
if the problem is broken into subtasks,
7b performance significantly increases.
In my limited evaluation,
7b beats the new sonnet too for image based extraction.
Kudos to the team!!
both 7b and 72B are just awesome.
if the problem is broken into subtasks,
7b performance significantly increases.
In my limited evaluation,
7b beats the new sonnet too for image based extraction.
Kudos to the team!!
November 11, 2024 at 10:42 PM
super impressed by Qwen2vl,
both 7b and 72B are just awesome.
if the problem is broken into subtasks,
7b performance significantly increases.
In my limited evaluation,
7b beats the new sonnet too for image based extraction.
Kudos to the team!!
both 7b and 72B are just awesome.
if the problem is broken into subtasks,
7b performance significantly increases.
In my limited evaluation,
7b beats the new sonnet too for image based extraction.
Kudos to the team!!
Note to my future self:
THINK OUT LOUD,
AND SHARE MORE IN PUBLIC (can be in various ways)
THINK OUT LOUD,
AND SHARE MORE IN PUBLIC (can be in various ways)
November 9, 2024 at 3:13 AM
Note to my future self:
THINK OUT LOUD,
AND SHARE MORE IN PUBLIC (can be in various ways)
THINK OUT LOUD,
AND SHARE MORE IN PUBLIC (can be in various ways)
kind of don't want to publicize much about this platform,
already feel anxious that people will start flooding here and might lose the current vibes that I am loving here.
already feel anxious that people will start flooding here and might lose the current vibes that I am loving here.
November 9, 2024 at 2:55 AM
kind of don't want to publicize much about this platform,
already feel anxious that people will start flooding here and might lose the current vibes that I am loving here.
already feel anxious that people will start flooding here and might lose the current vibes that I am loving here.
Reposted by Raju Penmatsa

If you listen to podcasts and like infrastructure, databases, cloud, or open source you should check it out
November 9, 2024 at 2:43 AM
If you listen to podcasts and like infrastructure, databases, cloud, or open source you should check it out
Reposted by Raju Penmatsa
Ship It! Always ships on Friday 😎
Let us know if you like the occasional news/articles episode. Trying to find a balance with interviews
@withenoughcoffee.bsky.social and I obviously recorded this before this week
Let us know if you like the occasional news/articles episode. Trying to find a balance with interviews
@withenoughcoffee.bsky.social and I obviously recorded this before this week


November 8, 2024 at 10:23 PM
Ship It! Always ships on Friday 😎
Let us know if you like the occasional news/articles episode. Trying to find a balance with interviews
@withenoughcoffee.bsky.social and I obviously recorded this before this week
Let us know if you like the occasional news/articles episode. Trying to find a balance with interviews
@withenoughcoffee.bsky.social and I obviously recorded this before this week
Reposted by Raju Penmatsa
one thing you will learn about me is that I sort of tweet (post?) to clarify my thinking.
as such, my second post (tweet?) about an idea is usually much better than the first.
as such, my second post (tweet?) about an idea is usually much better than the first.
November 8, 2024 at 1:54 PM
one thing you will learn about me is that I sort of tweet (post?) to clarify my thinking.
as such, my second post (tweet?) about an idea is usually much better than the first.
as such, my second post (tweet?) about an idea is usually much better than the first.
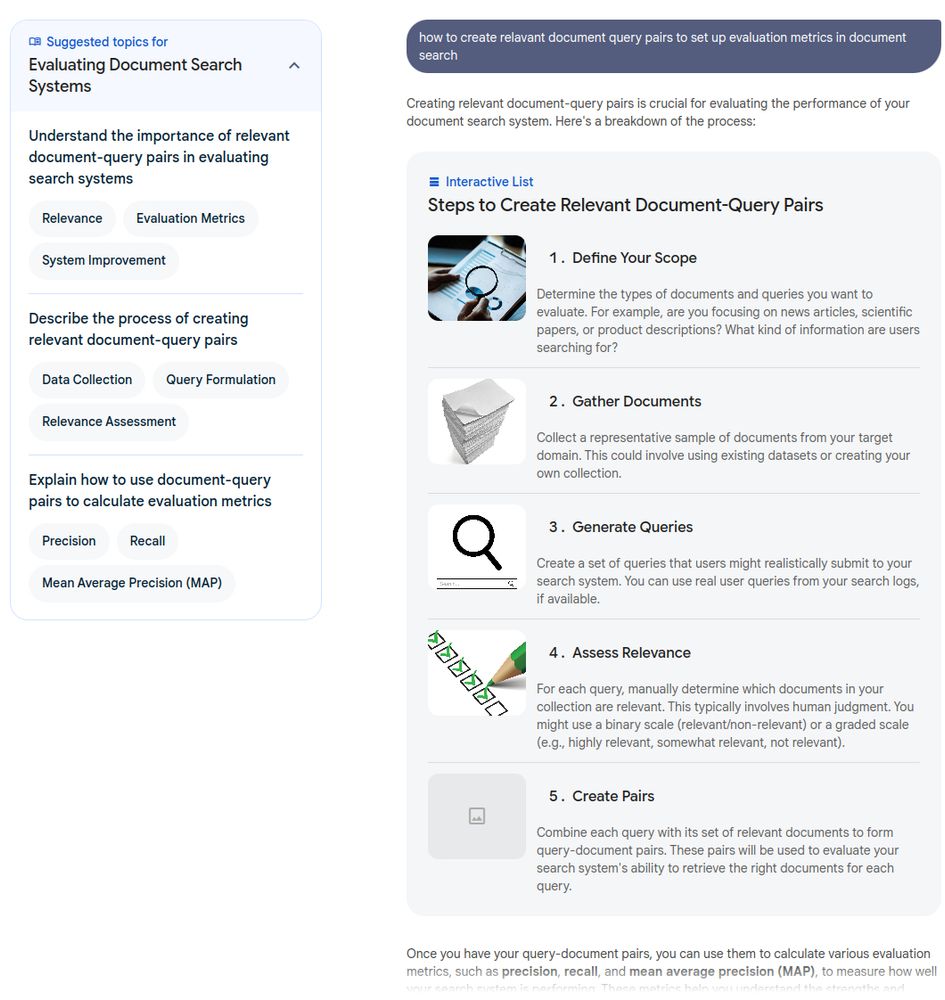
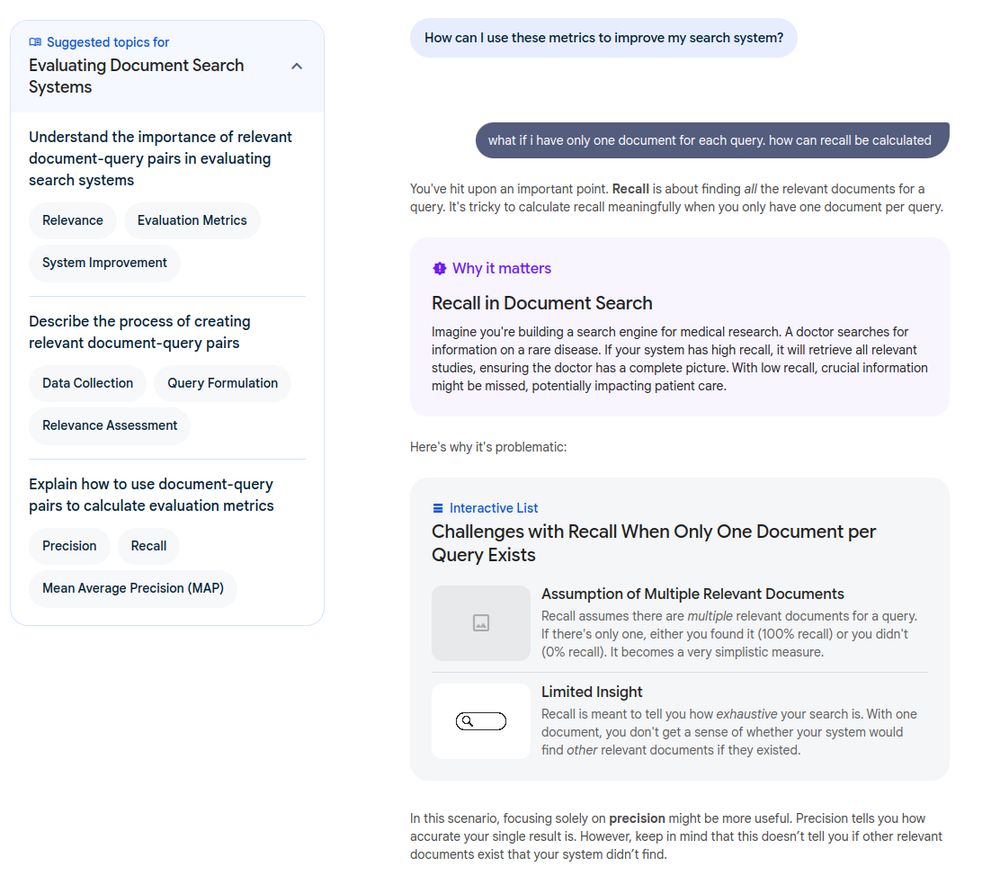
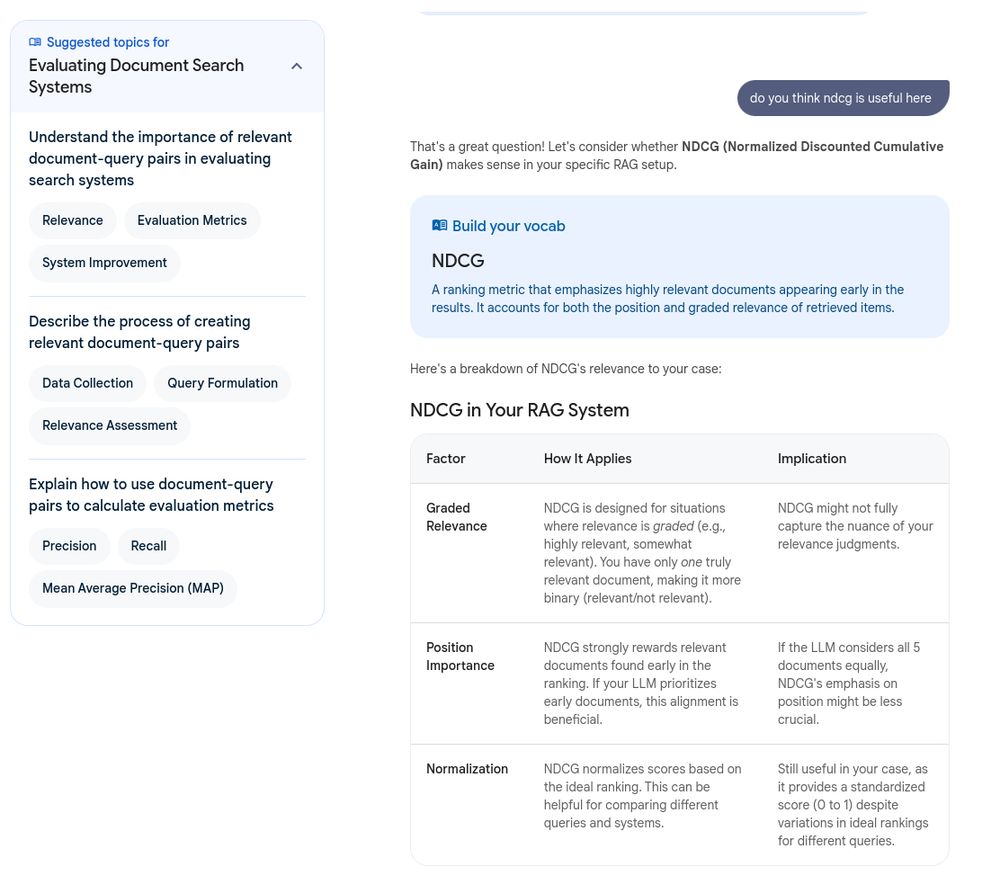
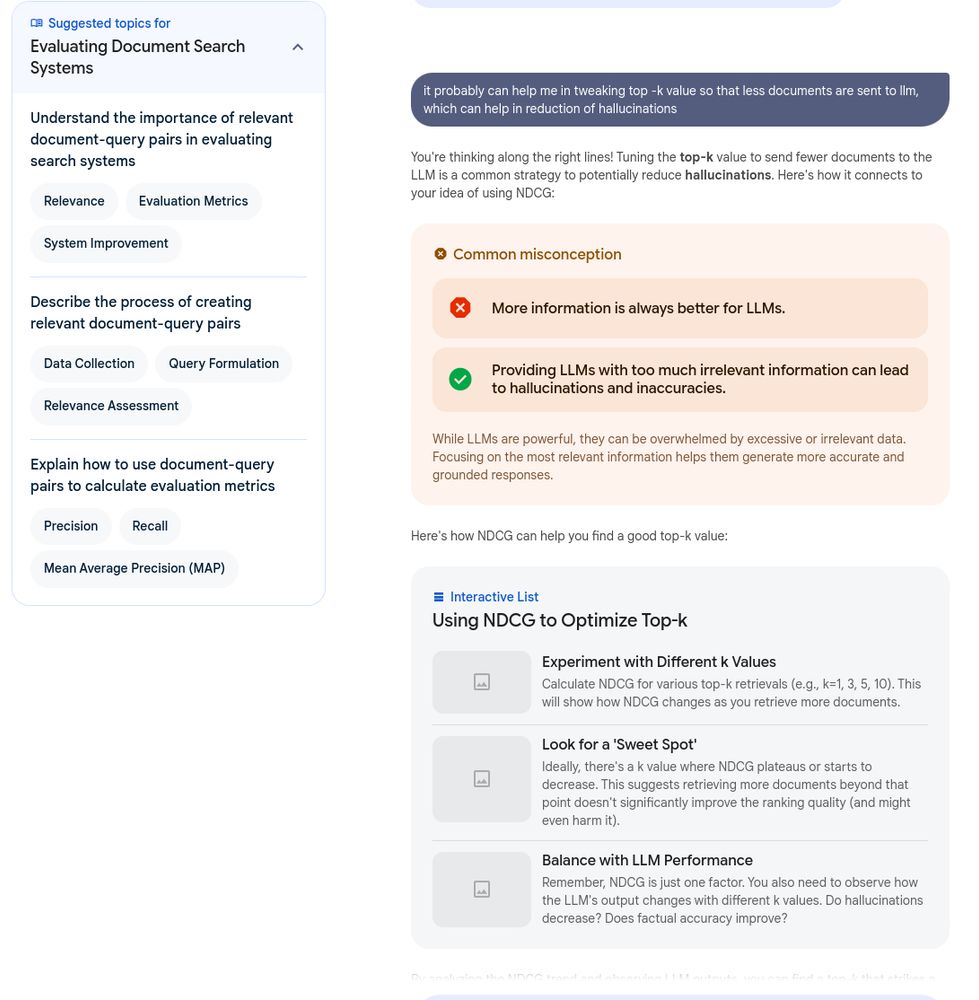
wish me luck and appreciate any inputs.
fundamentally working on a rag system for work, and setting good foundations.
i cringe on the word.. but yes "rag".
maybe search would be a better term, document search maybe.
anyhow,
trying my best to get better one day at a time.
fundamentally working on a rag system for work, and setting good foundations.
i cringe on the word.. but yes "rag".
maybe search would be a better term, document search maybe.
anyhow,
trying my best to get better one day at a time.

November 9, 2024 at 2:44 AM
wish me luck and appreciate any inputs.
fundamentally working on a rag system for work, and setting good foundations.
i cringe on the word.. but yes "rag".
maybe search would be a better term, document search maybe.
anyhow,
trying my best to get better one day at a time.
fundamentally working on a rag system for work, and setting good foundations.
i cringe on the word.. but yes "rag".
maybe search would be a better term, document search maybe.
anyhow,
trying my best to get better one day at a time.
joining the new fast.ai course, solveit from @jph.bsky.social.. feel free to hit me up if any of you folks are also joining. Super excited to learn they have been upto

fast.ai—Making neural nets uncool again – fast.ai
fast.ai
November 8, 2024 at 8:06 PM
joining the new fast.ai course, solveit from @jph.bsky.social.. feel free to hit me up if any of you folks are also joining. Super excited to learn they have been upto
Reposted by Raju Penmatsa

Quick thread in response to a question on token packing practices when pretraining LLMs!
Yes! Token packing has been the standard since RoBERTa. Excerpt below!
The intuition is that the model quickly learns to not attend across [SEP] boundaries and packing avoids "wasting" compute on padding tokens required to make the variable batch size consistent.
The intuition is that the model quickly learns to not attend across [SEP] boundaries and packing avoids "wasting" compute on padding tokens required to make the variable batch size consistent.

November 7, 2024 at 6:21 PM
Quick thread in response to a question on token packing practices when pretraining LLMs!
Reposted by Raju Penmatsa

+1; so thankful for everything I got from old twitter, and looking forward to building community here as well.
Still processing a lot of emotions from the last few days, but I'll keep re-posting starter packs as I catch my breath.
Still processing a lot of emotions from the last few days, but I'll keep re-posting starter packs as I catch my breath.

Twitter, 10 years ago, built so many careers, including mine! I'm so thankful for that community and happy to see it coming together again!

Agree! This feels like tech Twitter 10 years ago. Very high signal to noise ratio!
November 7, 2024 at 6:54 PM
+1; so thankful for everything I got from old twitter, and looking forward to building community here as well.
Still processing a lot of emotions from the last few days, but I'll keep re-posting starter packs as I catch my breath.
Still processing a lot of emotions from the last few days, but I'll keep re-posting starter packs as I catch my breath.
starter pack is a really great fix to the cold start problems of recommendation engines, especially when the site is new. this gives a boost in warming up recommendation engines.
would love to hear from @bsky.app 's team about the origin of idea. solves both human and machine problem 😂
would love to hear from @bsky.app 's team about the origin of idea. solves both human and machine problem 😂
November 7, 2024 at 6:44 PM
starter pack is a really great fix to the cold start problems of recommendation engines, especially when the site is new. this gives a boost in warming up recommendation engines.
would love to hear from @bsky.app 's team about the origin of idea. solves both human and machine problem 😂
would love to hear from @bsky.app 's team about the origin of idea. solves both human and machine problem 😂
Reposted by Raju Penmatsa
Yes! Token packing has been the standard since RoBERTa. Excerpt below!
The intuition is that the model quickly learns to not attend across [SEP] boundaries and packing avoids "wasting" compute on padding tokens required to make the variable batch size consistent.
The intuition is that the model quickly learns to not attend across [SEP] boundaries and packing avoids "wasting" compute on padding tokens required to make the variable batch size consistent.
November 7, 2024 at 6:02 PM
Yes! Token packing has been the standard since RoBERTa. Excerpt below!
The intuition is that the model quickly learns to not attend across [SEP] boundaries and packing avoids "wasting" compute on padding tokens required to make the variable batch size consistent.
The intuition is that the model quickly learns to not attend across [SEP] boundaries and packing avoids "wasting" compute on padding tokens required to make the variable batch size consistent.
Reposted by Raju Penmatsa

I think there's two categories, delineated by time:
1. Hours: Something is fucked. It needs to be unfucked. By any means necessary.
2. Weeks/days: We're building something new, and are on a crazy timeline. We've made some questionable structural decisions.
In the future they're indistinguishable.
1. Hours: Something is fucked. It needs to be unfucked. By any means necessary.
2. Weeks/days: We're building something new, and are on a crazy timeline. We've made some questionable structural decisions.
In the future they're indistinguishable.
November 7, 2024 at 5:19 PM
I think there's two categories, delineated by time:
1. Hours: Something is fucked. It needs to be unfucked. By any means necessary.
2. Weeks/days: We're building something new, and are on a crazy timeline. We've made some questionable structural decisions.
In the future they're indistinguishable.
1. Hours: Something is fucked. It needs to be unfucked. By any means necessary.
2. Weeks/days: We're building something new, and are on a crazy timeline. We've made some questionable structural decisions.
In the future they're indistinguishable.