



Raj Ghugare
@raj-ghugare.bsky.social
PhD student at Princeton University

We tried using LLMs with inference time thinking to solve some of our tasks. The models were prompted with the problem setting, given an example solution, and were asked to generate a high level plan in language. Both ChatGPT and Gemini were not able to provide the correct plan for any of the tasks!

October 16, 2025 at 11:08 PM
We tried using LLMs with inference time thinking to solve some of our tasks. The models were prompted with the problem setting, given an example solution, and were asked to generate a high level plan in language. Both ChatGPT and Gemini were not able to provide the correct plan for any of the tasks!
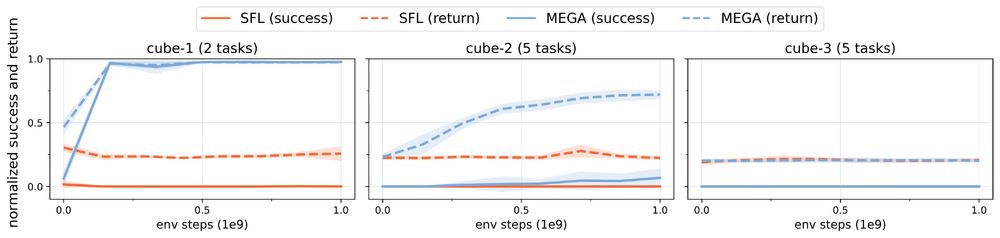
Training on the test goals improves both the returns and success achieved by the best agents. However as the number of cubes and the complexity of the tasks increase, current algorithms are not able to achieve a non zero success.

October 16, 2025 at 11:08 PM
Training on the test goals improves both the returns and success achieved by the best agents. However as the number of cubes and the complexity of the tasks increase, current algorithms are not able to achieve a non zero success.
We open-source single-file implementations of 6 representative reinforcement learning (RL) algorithms and self-supervised exploration algorithms. Most of the complex tasks remain unsolvable by the purely self-supervised algorithms we tried.
October 16, 2025 at 11:08 PM
We open-source single-file implementations of 6 representative reinforcement learning (RL) algorithms and self-supervised exploration algorithms. Most of the complex tasks remain unsolvable by the purely self-supervised algorithms we tried.
To evaluate open-ended exploration and generalization, we design the self-supervised protocol where agents explore the world and learn to solve autotelic tasks. To provide additional feedback for research, we also provide a “training-wheels” protocol where agents are trained on the test goal.

October 16, 2025 at 11:08 PM
To evaluate open-ended exploration and generalization, we design the self-supervised protocol where agents explore the world and learn to solve autotelic tasks. To provide additional feedback for research, we also provide a “training-wheels” protocol where agents are trained on the test goal.
The BuilderBench simulator is developed using MuJoCo and JAX. It is hardware accelerated and allows RL training between 10 to 100 times faster than purely CPU based open-ended benchmarks (e.g., training a PPO agent to stack two blocks takes 30 minutes on a single GPU).
October 16, 2025 at 11:08 PM
The BuilderBench simulator is developed using MuJoCo and JAX. It is hardware accelerated and allows RL training between 10 to 100 times faster than purely CPU based open-ended benchmarks (e.g., training a PPO agent to stack two blocks takes 30 minutes on a single GPU).
BuilderBench is meant to develop agents that can build any structure with building-blocks. Tasks not only require motor skills but higher-level skills such as logical & geometrical reasoning, intuitive physics and reasoning about counterweights, buttresses, and temporary scaffolding!

October 16, 2025 at 11:08 PM
BuilderBench is meant to develop agents that can build any structure with building-blocks. Tasks not only require motor skills but higher-level skills such as logical & geometrical reasoning, intuitive physics and reasoning about counterweights, buttresses, and temporary scaffolding!
Scalable learning mechanisms for agents that solve novel tasks via experience remain an open problem. We argue that a key reason is suitable benchmarks.
Happy to share BuilderBench, a benchmark to accelerate research in pre-training that centers learning from experience.
Happy to share BuilderBench, a benchmark to accelerate research in pre-training that centers learning from experience.

October 16, 2025 at 11:08 PM
Scalable learning mechanisms for agents that solve novel tasks via experience remain an open problem. We argue that a key reason is suitable benchmarks.
Happy to share BuilderBench, a benchmark to accelerate research in pre-training that centers learning from experience.
Happy to share BuilderBench, a benchmark to accelerate research in pre-training that centers learning from experience.
Can AI models build a world which today's generative models can only dream of?
Presenting BuilderBench (website : t.co/H7wToslhXG).
Details below 🧵⬇️
Presenting BuilderBench (website : t.co/H7wToslhXG).
Details below 🧵⬇️
October 16, 2025 at 11:08 PM
Can AI models build a world which today's generative models can only dream of?
Presenting BuilderBench (website : t.co/H7wToslhXG).
Details below 🧵⬇️
Presenting BuilderBench (website : t.co/H7wToslhXG).
Details below 🧵⬇️
In unsupervised goal conditioned RL: A simple goal sampling strategy that uses NF’s ability to provide density estimates outperforms supervised oracles like contrastive RL on 3 standard exploration tasks.

June 5, 2025 at 5:06 PM
In unsupervised goal conditioned RL: A simple goal sampling strategy that uses NF’s ability to provide density estimates outperforms supervised oracles like contrastive RL on 3 standard exploration tasks.
On offline RL: NF-RLBC outperforms strong baselines like flow matching and diffusion-based Q-learning on half the tasks. This boost comes by simply replacing the Gaussian policy with an NF in the SAC+BC recipe. Unlike diffusion, no distillation or importance sampling is needed.

June 5, 2025 at 5:06 PM
On offline RL: NF-RLBC outperforms strong baselines like flow matching and diffusion-based Q-learning on half the tasks. This boost comes by simply replacing the Gaussian policy with an NF in the SAC+BC recipe. Unlike diffusion, no distillation or importance sampling is needed.
On conditional Imitation learning: (left) Just exchanging a gaussian policy with an NF policy leads to significant improvements. (right) NF-GCBC outerforms the flow matching policies, as well as dedicated offline RL algorithms like IQL or quasimetric RL.

June 5, 2025 at 5:06 PM
On conditional Imitation learning: (left) Just exchanging a gaussian policy with an NF policy leads to significant improvements. (right) NF-GCBC outerforms the flow matching policies, as well as dedicated offline RL algorithms like IQL or quasimetric RL.
On Imitation learning: NF-BC is competitive with diffusion / transformer policies, which are the go to models for imitation learning today. But NF-BC requires fewer hyper-parameters (no SDEs / no noise scheduling / no discrete representations).

June 5, 2025 at 5:06 PM
On Imitation learning: NF-BC is competitive with diffusion / transformer policies, which are the go to models for imitation learning today. But NF-BC requires fewer hyper-parameters (no SDEs / no noise scheduling / no discrete representations).
Stacking affine coupling networks, permutations layers and layerNorm results in a simple and scalable architecture. It seamlessly integrates with canonical imitation learning, offline RL, goal conditioned and unsupervised RL algorithms.

June 5, 2025 at 5:06 PM
Stacking affine coupling networks, permutations layers and layerNorm results in a simple and scalable architecture. It seamlessly integrates with canonical imitation learning, offline RL, goal conditioned and unsupervised RL algorithms.
The core of most RL algorithms is just likelihood estimation, sampling, and variational Inference (see attached image). NFs can efficiently do all three! It raises the question of why don’t we see them more commonly used in RL?

June 5, 2025 at 5:06 PM
The core of most RL algorithms is just likelihood estimation, sampling, and variational Inference (see attached image). NFs can efficiently do all three! It raises the question of why don’t we see them more commonly used in RL?
Normalizing Flows (NFs) check all boxes for RL: exact likelihoods (imitation learning), efficient sampling (real-time control), and variational inference (Q-learning)! Yet they are overlooked over more expensive and less flexible contemporaries like diffusion models.
Are NFs fundamentally limited?
Are NFs fundamentally limited?

June 5, 2025 at 5:06 PM
Normalizing Flows (NFs) check all boxes for RL: exact likelihoods (imitation learning), efficient sampling (real-time control), and variational inference (Q-learning)! Yet they are overlooked over more expensive and less flexible contemporaries like diffusion models.
Are NFs fundamentally limited?
Are NFs fundamentally limited?