



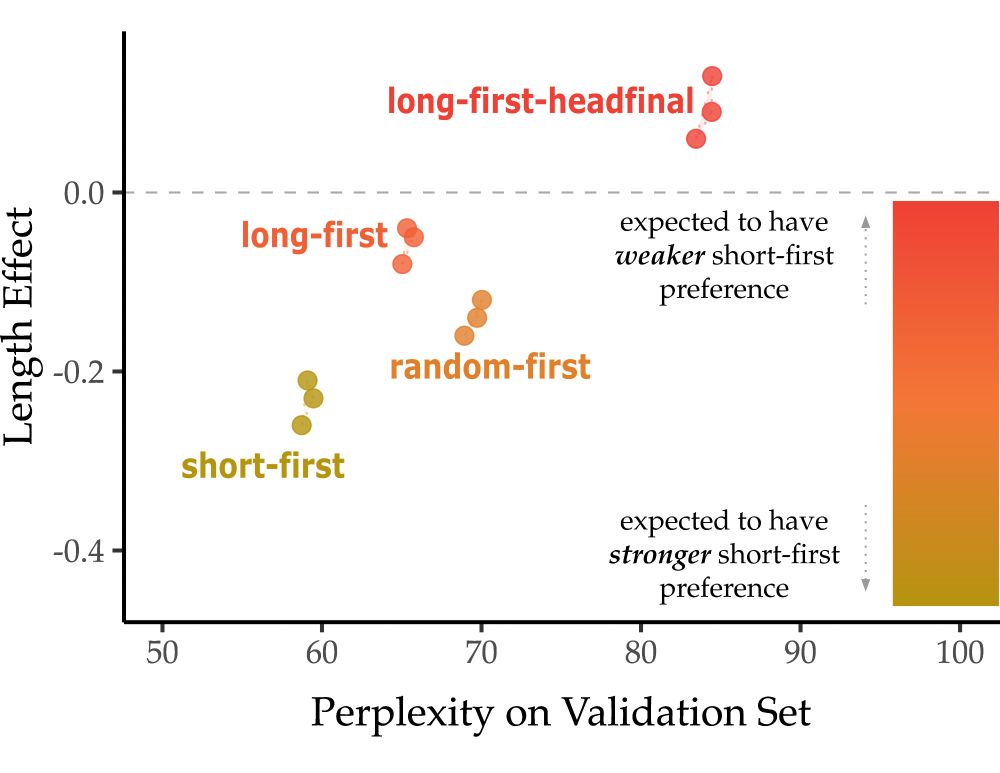
Learned length preference changes with the input manipulation. That is, the more “long-first” we make the input, the weaker the short-first preference. We think this shows the dative preferences in models come not just from datives but from general properties of English.
March 31, 2025 at 1:30 PM
Learned length preference changes with the input manipulation. That is, the more “long-first” we make the input, the weaker the short-first preference. We think this shows the dative preferences in models come not just from datives but from general properties of English.
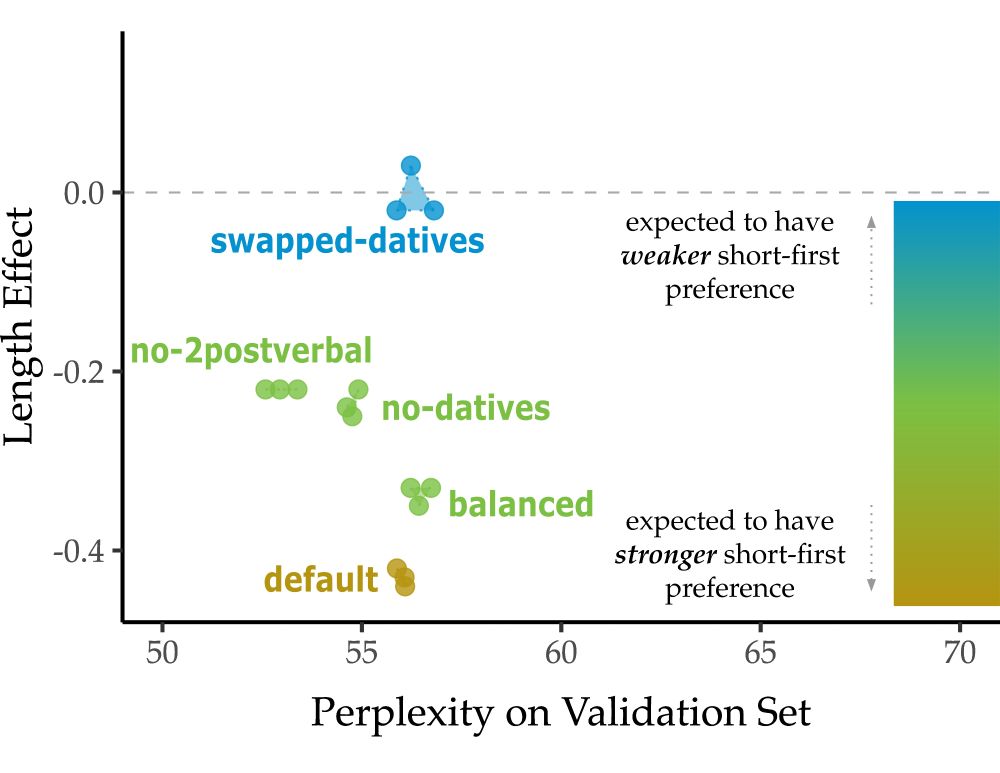
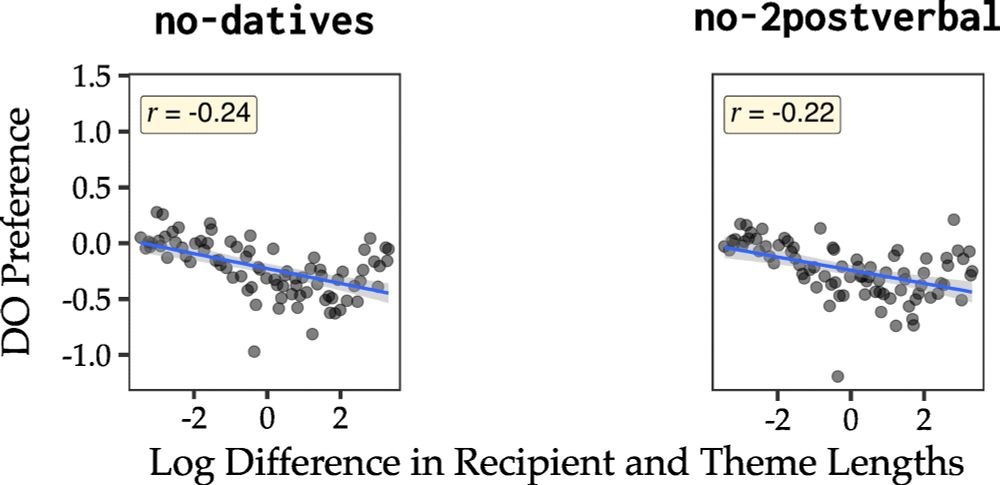
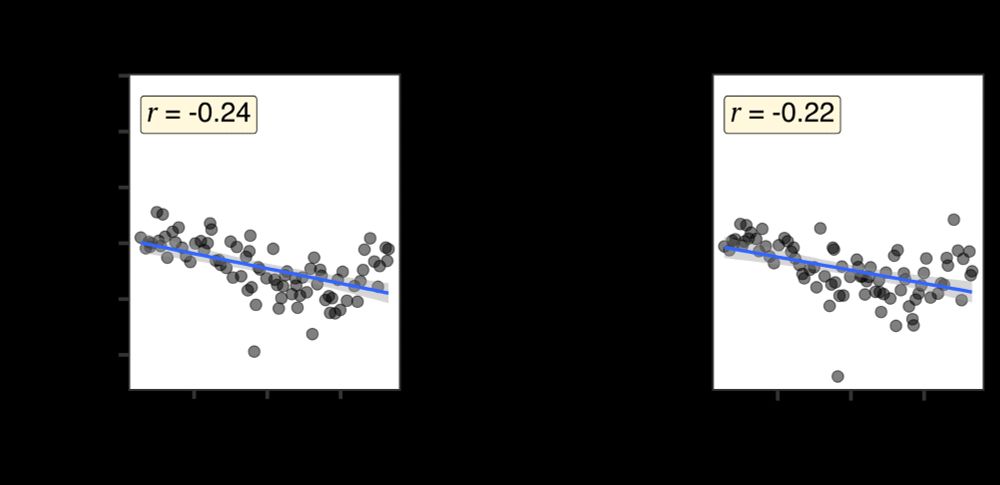
Now what if we get rid of datives, and further all constructions which have two postverbal arguments? Now we see the length preference is back again. Yes it’s smaller (direct evidence matters), but why is it there? Where does it come from if not the datives?
March 31, 2025 at 1:30 PM
Now what if we get rid of datives, and further all constructions which have two postverbal arguments? Now we see the length preference is back again. Yes it’s smaller (direct evidence matters), but why is it there? Where does it come from if not the datives?
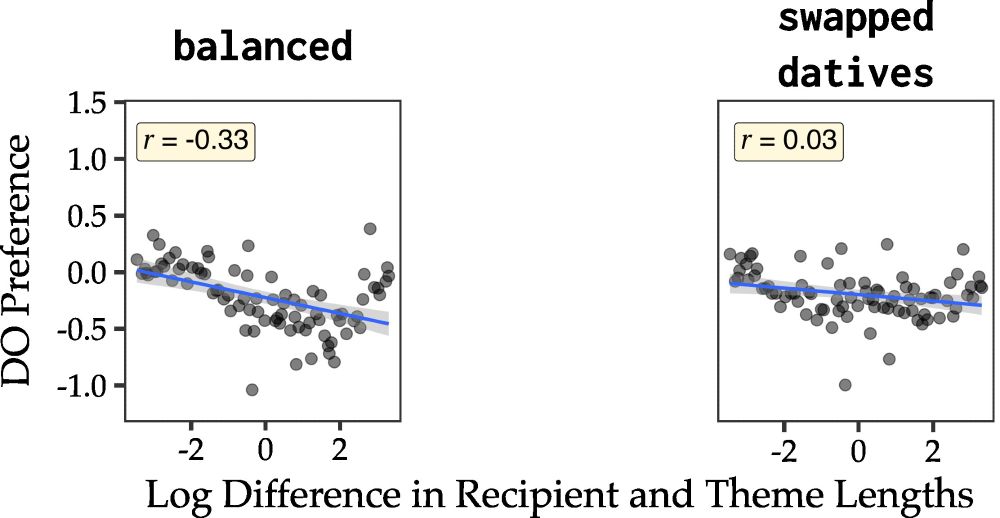
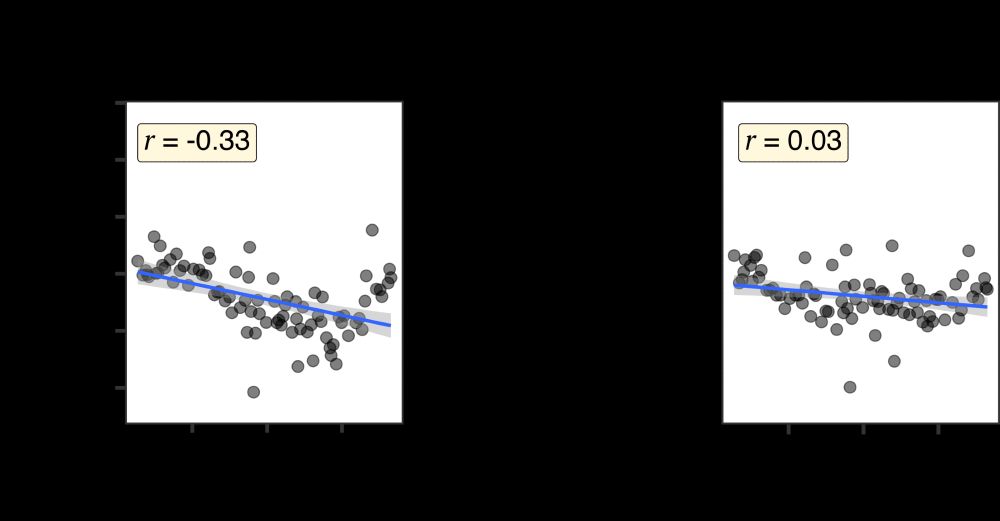
What if we modify the corpus such that for every DO there is a PO (balance direct evidence)? The preferences are still present! But what if now we SWAP every dative in the input so that every DO is now a PO, every PO a DO? The preference essentially disappears (but not flipped!)
March 31, 2025 at 1:30 PM
What if we modify the corpus such that for every DO there is a PO (balance direct evidence)? The preferences are still present! But what if now we SWAP every dative in the input so that every DO is now a PO, every PO a DO? The preference essentially disappears (but not flipped!)
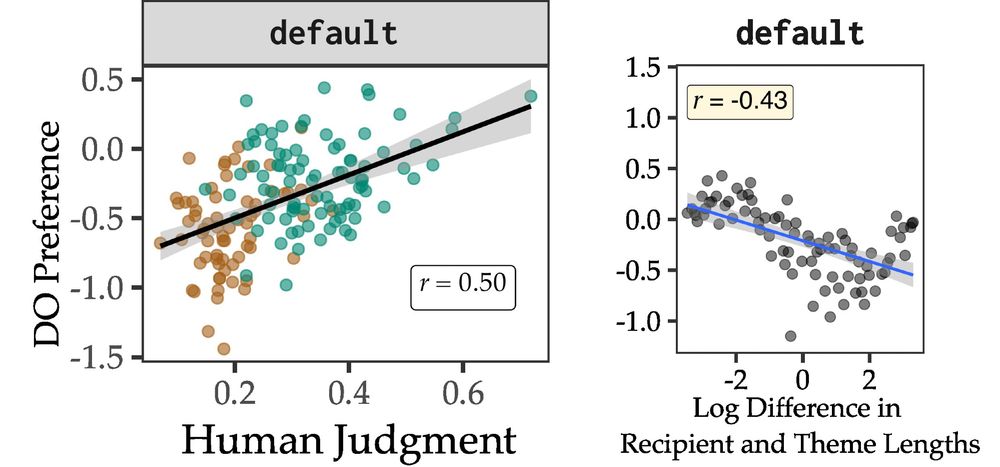
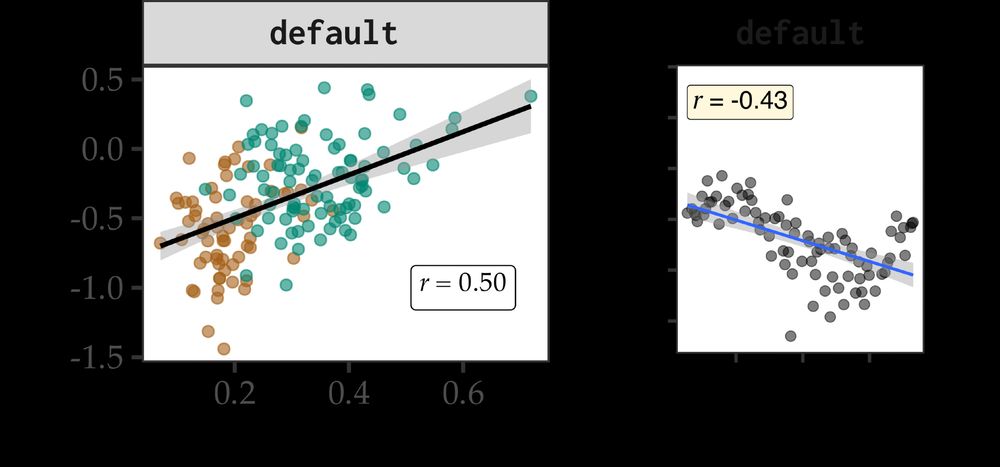
To test this, we train small LMs on manipulated datasets where we vary direct (datives) and indirect (non-datives) evidence and test the change in their preferences. First, we see that we get human-like preferences on a model trained on our default BabyLM corpus.
March 31, 2025 at 1:30 PM
To test this, we train small LMs on manipulated datasets where we vary direct (datives) and indirect (non-datives) evidence and test the change in their preferences. First, we see that we get human-like preferences on a model trained on our default BabyLM corpus.
LMs learn argument-based preferences for dative constructions (preferring recipient first when it’s shorter), consistent with humans. Is this from memorizing preferences in training? New paper w/ @kanishka.bsky.social , @weissweiler.bsky.social , @kmahowald.bsky.social
arxiv.org/abs/2503.20850
arxiv.org/abs/2503.20850

March 31, 2025 at 1:30 PM
LMs learn argument-based preferences for dative constructions (preferring recipient first when it’s shorter), consistent with humans. Is this from memorizing preferences in training? New paper w/ @kanishka.bsky.social , @weissweiler.bsky.social , @kmahowald.bsky.social
arxiv.org/abs/2503.20850
arxiv.org/abs/2503.20850
Now what if we get rid of datives, and further all constructions which have two postverbal arguments? Now we see the length preference is back again. Yes it’s smaller (direct evidence matters), but why is it there? Where does it come from if not the datives?
March 31, 2025 at 1:14 PM
Now what if we get rid of datives, and further all constructions which have two postverbal arguments? Now we see the length preference is back again. Yes it’s smaller (direct evidence matters), but why is it there? Where does it come from if not the datives?
What if we modify the corpus such that for every DO there is a PO (balance direct evidence)? The preferences are still present! But what if now we SWAP every dative in the input so that every DO is now a PO, every PO a DO? The preference essentially disappears (but not flipped!)
March 31, 2025 at 1:14 PM
What if we modify the corpus such that for every DO there is a PO (balance direct evidence)? The preferences are still present! But what if now we SWAP every dative in the input so that every DO is now a PO, every PO a DO? The preference essentially disappears (but not flipped!)
To test this, we train small LMs on manipulated datasets where we vary direct (datives) and indirect (non-datives) evidence and test the change in their preferences. First, we see that we get human-like preferences on a model trained on our default BabyLM corpus.
March 31, 2025 at 1:14 PM
To test this, we train small LMs on manipulated datasets where we vary direct (datives) and indirect (non-datives) evidence and test the change in their preferences. First, we see that we get human-like preferences on a model trained on our default BabyLM corpus.