



Quentin Gallouédec
@qgallouedec.hf.co
PhD - Research @hf.co 🤗
TRL maintainer
TRL maintainer
It started as a modest project to offer a free, open-source alternative to MuJoCo environments, and today, panda-gym is downloaded over 100k times, and cited in over 100 papers. 🦾


May 2, 2025 at 11:14 PM
It started as a modest project to offer a free, open-source alternative to MuJoCo environments, and today, panda-gym is downloaded over 100k times, and cited in over 100 papers. 🦾
just pip install trl

April 26, 2025 at 10:57 PM
just pip install trl
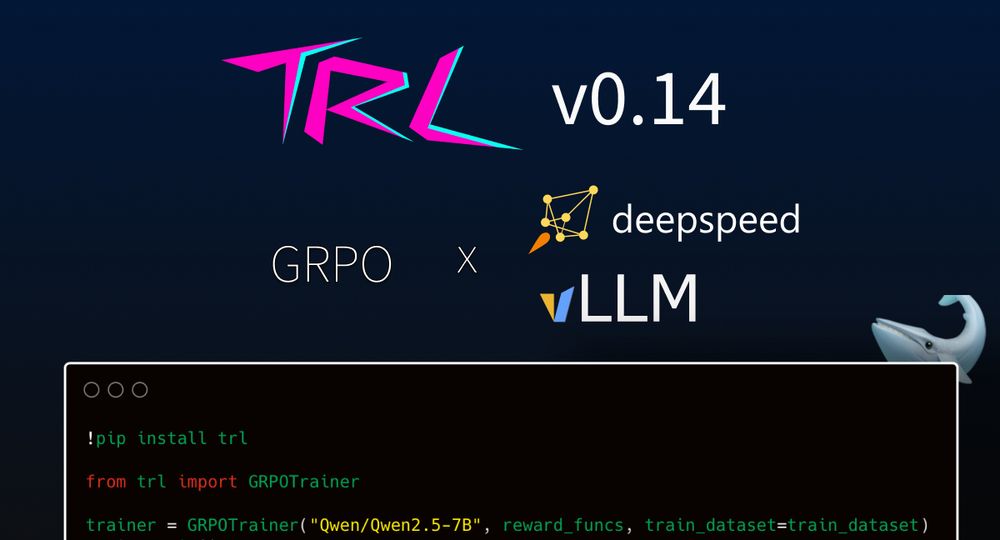
🚀 TRL 0.14 – Featuring GRPO! 🚀
TRL 0.14 brings *GRPO*, the RL algorithm behind 🐳 DeekSeek-R1 .
⚡ Blazing fast generation with vLLM integration.
📉 Optimized training with DeepSpeed ZeRO 1/2/3.
TRL 0.14 brings *GRPO*, the RL algorithm behind 🐳 DeekSeek-R1 .
⚡ Blazing fast generation with vLLM integration.
📉 Optimized training with DeepSpeed ZeRO 1/2/3.
January 30, 2025 at 2:54 PM
🚀 TRL 0.14 – Featuring GRPO! 🚀
TRL 0.14 brings *GRPO*, the RL algorithm behind 🐳 DeekSeek-R1 .
⚡ Blazing fast generation with vLLM integration.
📉 Optimized training with DeepSpeed ZeRO 1/2/3.
TRL 0.14 brings *GRPO*, the RL algorithm behind 🐳 DeekSeek-R1 .
⚡ Blazing fast generation with vLLM integration.
📉 Optimized training with DeepSpeed ZeRO 1/2/3.
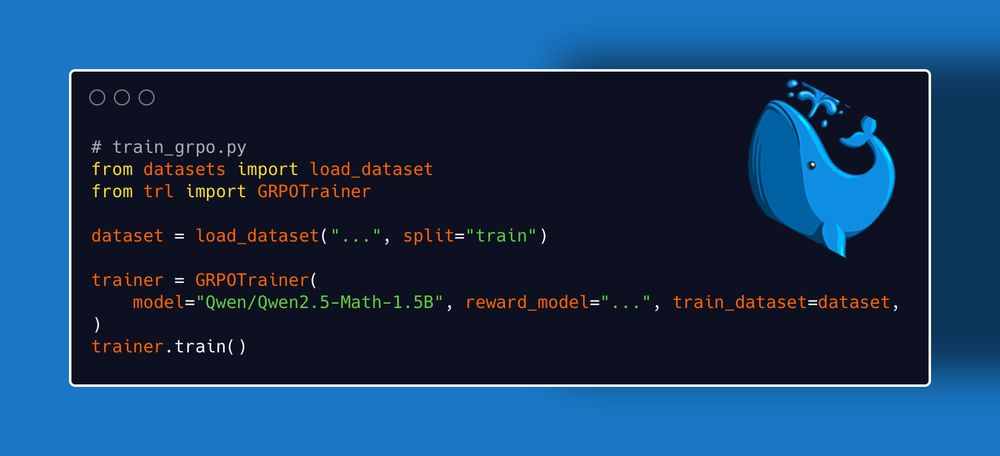
The algorithm behind DeepSeek's R1 model (aka GRPO) now lives in TRL main branch! Go and test it!
January 22, 2025 at 3:07 PM
The algorithm behind DeepSeek's R1 model (aka GRPO) now lives in TRL main branch! Go and test it!
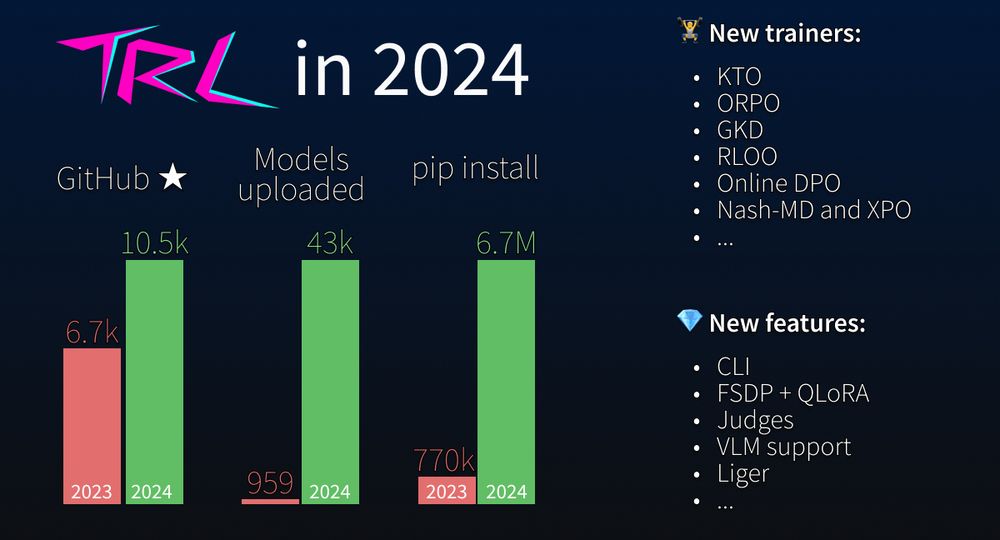
[Stonks] TRL is a Python library for training language models.
It has seen impressive growth this year. Lots of new features, an improved codebase, and this has translated into increased usage. You can count on us to do even more in 2025.
It has seen impressive growth this year. Lots of new features, an improved codebase, and this has translated into increased usage. You can count on us to do even more in 2025.
January 6, 2025 at 5:26 PM
[Stonks] TRL is a Python library for training language models.
It has seen impressive growth this year. Lots of new features, an improved codebase, and this has translated into increased usage. You can count on us to do even more in 2025.
It has seen impressive growth this year. Lots of new features, an improved codebase, and this has translated into increased usage. You can count on us to do even more in 2025.
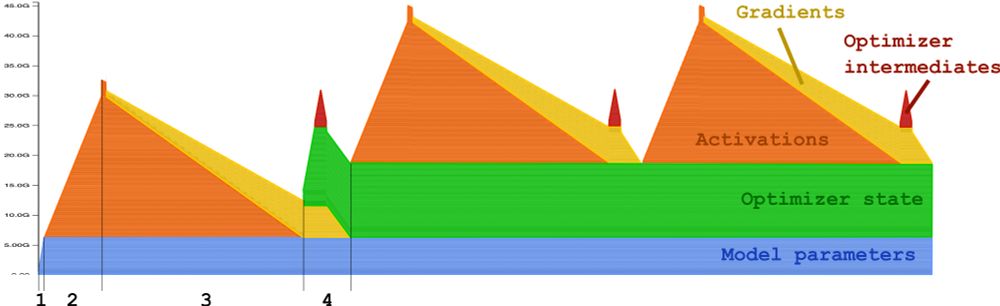
🎅 Santa Claus has delivered the ultimate guide to understand OOM error (link in comment)
December 24, 2024 at 11:04 AM
🎅 Santa Claus has delivered the ultimate guide to understand OOM error (link in comment)
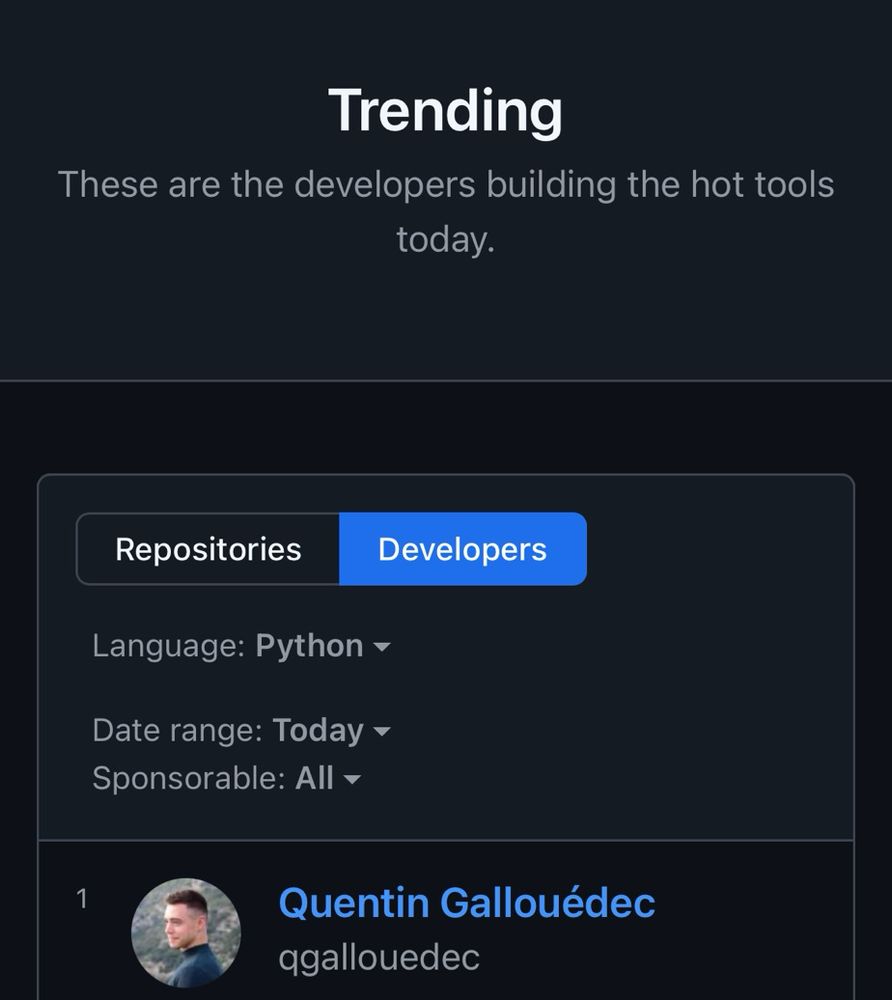
Top 1 Python dev today. Third time since september 🫨
December 17, 2024 at 6:32 PM
Top 1 Python dev today. Third time since september 🫨
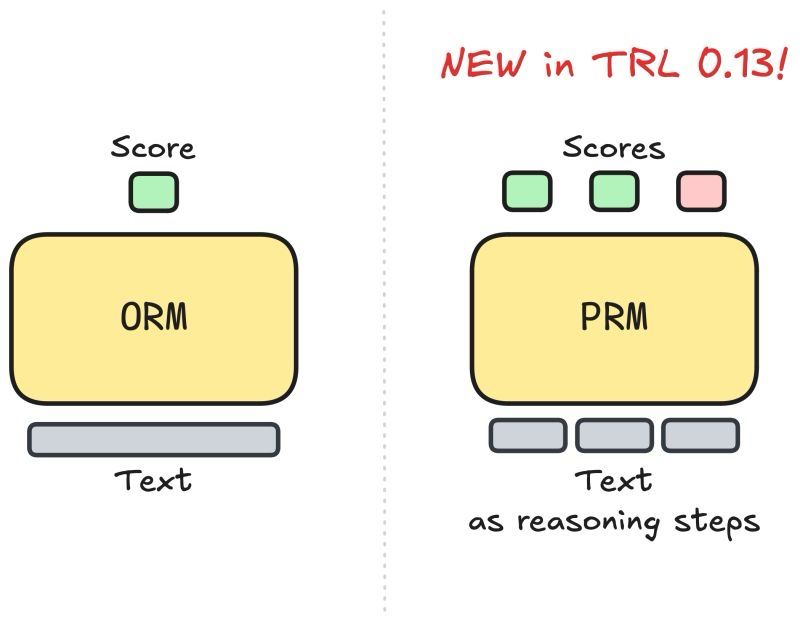
🚨 TRL 0.13 is out! 🤗
Featuring a Process-supervised Reward Models (PRM) Trainer 🏋️
PRMs empower LLMs to "think before answering"—a key feature behind OpenAI's o1 launch just two weeks ago. 🚀
Featuring a Process-supervised Reward Models (PRM) Trainer 🏋️
PRMs empower LLMs to "think before answering"—a key feature behind OpenAI's o1 launch just two weeks ago. 🚀
December 17, 2024 at 4:07 PM
🚨 TRL 0.13 is out! 🤗
Featuring a Process-supervised Reward Models (PRM) Trainer 🏋️
PRMs empower LLMs to "think before answering"—a key feature behind OpenAI's o1 launch just two weeks ago. 🚀
Featuring a Process-supervised Reward Models (PRM) Trainer 🏋️
PRMs empower LLMs to "think before answering"—a key feature behind OpenAI's o1 launch just two weeks ago. 🚀
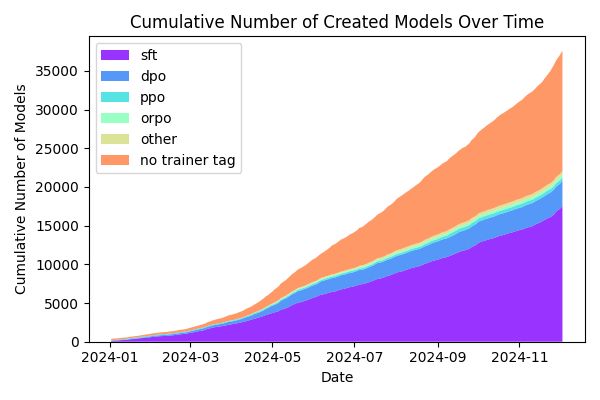
The number of TRL models on the 🤗 Hub has risen x60 this year! 📈
How about doing the same next year?
How about doing the same next year?
December 3, 2024 at 12:55 PM
The number of TRL models on the 🤗 Hub has risen x60 this year! 📈
How about doing the same next year?
How about doing the same next year?
Join us at Hugging Face as an intern if you want to contribute to amazing open-source projects, and develop LLM's best finetuning library, aka TRL.
🧑💻 Full remote
🤯 Exciting subjects
🌍 Anywhere in the world
🤸🏻 Flexible working hours
Link to apply in comment 👇
🧑💻 Full remote
🤯 Exciting subjects
🌍 Anywhere in the world
🤸🏻 Flexible working hours
Link to apply in comment 👇
November 27, 2024 at 3:49 PM
Join us at Hugging Face as an intern if you want to contribute to amazing open-source projects, and develop LLM's best finetuning library, aka TRL.
🧑💻 Full remote
🤯 Exciting subjects
🌍 Anywhere in the world
🤸🏻 Flexible working hours
Link to apply in comment 👇
🧑💻 Full remote
🤯 Exciting subjects
🌍 Anywhere in the world
🤸🏻 Flexible working hours
Link to apply in comment 👇