



Quentin Berthet
@qberthet.bsky.social
Machine learning
Google DeepMind
Paris
Google DeepMind
Paris
1) des gens y travaillent
2) tout a fait d'accord ! Je ne justifiais pas la tâche kafkaïenne. Mon approche est plus de chercher un moyen de contourner que de protester, en général
2) tout a fait d'accord ! Je ne justifiais pas la tâche kafkaïenne. Mon approche est plus de chercher un moyen de contourner que de protester, en général
November 14, 2025 at 6:57 AM
1) des gens y travaillent
2) tout a fait d'accord ! Je ne justifiais pas la tâche kafkaïenne. Mon approche est plus de chercher un moyen de contourner que de protester, en général
2) tout a fait d'accord ! Je ne justifiais pas la tâche kafkaïenne. Mon approche est plus de chercher un moyen de contourner que de protester, en général
Un des exemples de motivation derrière la recherche académique sur les LLMs je crois : "ça doit être plus facile d'apprendre a des modèles à écrire que de continuer à remplir ces formulaires
November 14, 2025 at 6:56 AM
Un des exemples de motivation derrière la recherche académique sur les LLMs je crois : "ça doit être plus facile d'apprendre a des modèles à écrire que de continuer à remplir ces formulaires
Si seulement il y avait une technologie permettant de faire ça automatiquement ;-)
November 13, 2025 at 9:39 PM
Si seulement il y avait une technologie permettant de faire ça automatiquement ;-)
Being a rejected paper seems like a good criteria (possible issues, but very easy to implement)
September 20, 2025 at 10:26 AM
Being a rejected paper seems like a good criteria (possible issues, but very easy to implement)
I'm surprised, there must have been an additional round of changes.
All the emails I saw as an SAC were "help your ACs write new meta-reviews".
All the emails I saw as an SAC were "help your ACs write new meta-reviews".
September 20, 2025 at 10:25 AM
I'm surprised, there must have been an additional round of changes.
All the emails I saw as an SAC were "help your ACs write new meta-reviews".
All the emails I saw as an SAC were "help your ACs write new meta-reviews".
I think that they are hard to bootstrap.
While I agree that general chairs, program chairs, local chairs etc do a lot of work (seeing a glimpse of that sometimes myself with ALT/AISTATS), once you start having a bit of money, it can get easier with using conference organising services
While I agree that general chairs, program chairs, local chairs etc do a lot of work (seeing a glimpse of that sometimes myself with ALT/AISTATS), once you start having a bit of money, it can get easier with using conference organising services
September 19, 2025 at 1:34 PM
I think that they are hard to bootstrap.
While I agree that general chairs, program chairs, local chairs etc do a lot of work (seeing a glimpse of that sometimes myself with ALT/AISTATS), once you start having a bit of money, it can get easier with using conference organising services
While I agree that general chairs, program chairs, local chairs etc do a lot of work (seeing a glimpse of that sometimes myself with ALT/AISTATS), once you start having a bit of money, it can get easier with using conference organising services
How do-able would it be to organize a conference with its deadline a week after NeurIPS, held a week before, that would always take place physically in Europe (but welcome contributions from anywhere)?
September 19, 2025 at 12:52 PM
How do-able would it be to organize a conference with its deadline a week after NeurIPS, held a week before, that would always take place physically in Europe (but welcome contributions from anywhere)?
I'm very happy that EurIPS is happening, and planning to attend.
But as a NeurIPS SAC I must say that the last definition should not exist - ACs are supposed to change the decisions and update their meta-review themselves.
But as a NeurIPS SAC I must say that the last definition should not exist - ACs are supposed to change the decisions and update their meta-review themselves.
September 19, 2025 at 12:50 PM
I'm very happy that EurIPS is happening, and planning to attend.
But as a NeurIPS SAC I must say that the last definition should not exist - ACs are supposed to change the decisions and update their meta-review themselves.
But as a NeurIPS SAC I must say that the last definition should not exist - ACs are supposed to change the decisions and update their meta-review themselves.
At #AISTATS2025, I will be giving an "Oral" presentation of our work on "Implicit Diffusion"
arxiv.org/abs/2402.05468
arxiv.org/abs/2402.05468
April 17, 2025 at 12:50 PM
At #AISTATS2025, I will be giving an "Oral" presentation of our work on "Implicit Diffusion"
arxiv.org/abs/2402.05468
arxiv.org/abs/2402.05468
Il y a plus de 200 notes ?
February 22, 2025 at 8:37 PM
Il y a plus de 200 notes ?
These findings are quite consistent
Our end-to-end method captures a regression and a classification objective, as well as the autoencoder loss.
We see it as "building a bridge" between these different problems.
8/8
Our end-to-end method captures a regression and a classification objective, as well as the autoencoder loss.
We see it as "building a bridge" between these different problems.
8/8

February 10, 2025 at 12:00 PM
These findings are quite consistent
Our end-to-end method captures a regression and a classification objective, as well as the autoencoder loss.
We see it as "building a bridge" between these different problems.
8/8
Our end-to-end method captures a regression and a classification objective, as well as the autoencoder loss.
We see it as "building a bridge" between these different problems.
8/8
This is a simple generalization from previous binning approaches, the main difference being that we learn the encoding.
We compare different training methods, showing up to 25% improvement on the least-squares baseline error for our full end-to-end method, over 8 datasets.
7/8
We compare different training methods, showing up to 25% improvement on the least-squares baseline error for our full end-to-end method, over 8 datasets.
7/8
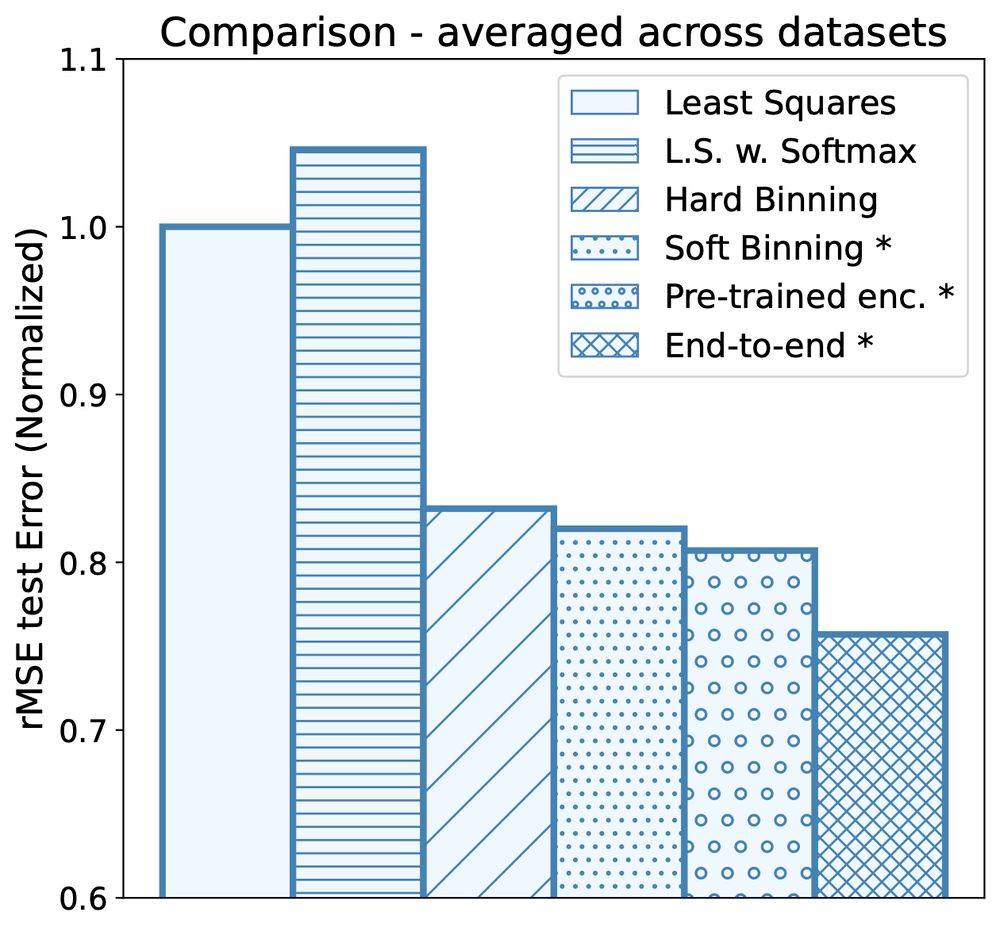
February 10, 2025 at 12:00 PM
This is a simple generalization from previous binning approaches, the main difference being that we learn the encoding.
We compare different training methods, showing up to 25% improvement on the least-squares baseline error for our full end-to-end method, over 8 datasets.
7/8
We compare different training methods, showing up to 25% improvement on the least-squares baseline error for our full end-to-end method, over 8 datasets.
7/8
You can then train a classification model π_θ (green, top) on the encoded targets, with a KL/cross-entropy objective!
At inference time, you use the same decoder μ to perform your prediction!
6/8
At inference time, you use the same decoder μ to perform your prediction!
6/8
February 10, 2025 at 12:00 PM
You can then train a classification model π_θ (green, top) on the encoded targets, with a KL/cross-entropy objective!
At inference time, you use the same decoder μ to perform your prediction!
6/8
At inference time, you use the same decoder μ to perform your prediction!
6/8
First, the architecture - we use a general target encoder Ψ_w (red, bottom) that transforms the target y in a distribution over k classes
e.g. use softmax(dist) to k different centers
The encoder and the associated decoder μ (in blue) can be trained on an autoencoder loss
5/8
e.g. use softmax(dist) to k different centers
The encoder and the associated decoder μ (in blue) can be trained on an autoencoder loss
5/8

February 10, 2025 at 12:00 PM
First, the architecture - we use a general target encoder Ψ_w (red, bottom) that transforms the target y in a distribution over k classes
e.g. use softmax(dist) to k different centers
The encoder and the associated decoder μ (in blue) can be trained on an autoencoder loss
5/8
e.g. use softmax(dist) to k different centers
The encoder and the associated decoder μ (in blue) can be trained on an autoencoder loss
5/8
In this work, we propose improvements for "regression as classification"
- Soft-binning: encode the target as a probability, not just a one-hot.
- Learnt target encoders: Instead of designing this transformation by hand, learn it from data.
- Train everything jointly!
4/8
- Soft-binning: encode the target as a probability, not just a one-hot.
- Learnt target encoders: Instead of designing this transformation by hand, learn it from data.
- Train everything jointly!
4/8
February 10, 2025 at 12:00 PM
In this work, we propose improvements for "regression as classification"
- Soft-binning: encode the target as a probability, not just a one-hot.
- Learnt target encoders: Instead of designing this transformation by hand, learn it from data.
- Train everything jointly!
4/8
- Soft-binning: encode the target as a probability, not just a one-hot.
- Learnt target encoders: Instead of designing this transformation by hand, learn it from data.
- Train everything jointly!
4/8
The idea is to transform each value of the target into a class one-hot, and to train a classification model to predict the value of the target. (here with y in 2D, with a grid)
It seems strange, but it's been shown to work well in many settings, even for RL applications.
3/8
It seems strange, but it's been shown to work well in many settings, even for RL applications.
3/8

February 10, 2025 at 12:00 PM
The idea is to transform each value of the target into a class one-hot, and to train a classification model to predict the value of the target. (here with y in 2D, with a grid)
It seems strange, but it's been shown to work well in many settings, even for RL applications.
3/8
It seems strange, but it's been shown to work well in many settings, even for RL applications.
3/8
An intriguing observation:
In many tasks with a continuous target (price, rating, pitch..), instead of training on a regression objective with least-squares [which seems super natural!] - people have been instead training their models using classification!
2/8
In many tasks with a continuous target (price, rating, pitch..), instead of training on a regression objective with least-squares [which seems super natural!] - people have been instead training their models using classification!
2/8
February 10, 2025 at 12:00 PM
An intriguing observation:
In many tasks with a continuous target (price, rating, pitch..), instead of training on a regression objective with least-squares [which seems super natural!] - people have been instead training their models using classification!
2/8
In many tasks with a continuous target (price, rating, pitch..), instead of training on a regression objective with least-squares [which seems super natural!] - people have been instead training their models using classification!
2/8
Check out our paper, with Lawrence Stewart and @bachfrancis.bsky.social
Link: arxiv.org/abs/2502.02996
1/8
Link: arxiv.org/abs/2502.02996
1/8

Building Bridges between Regression, Clustering, and Classification
Regression, the task of predicting a continuous scalar target y based on some features x is one of the most fundamental tasks in machine learning and statistics. It has been observed and...
arxiv.org
February 10, 2025 at 12:00 PM
Check out our paper, with Lawrence Stewart and @bachfrancis.bsky.social
Link: arxiv.org/abs/2502.02996
1/8
Link: arxiv.org/abs/2502.02996
1/8