



Quentin Berthet
@qberthet.bsky.social
Machine learning
Google DeepMind
Paris
Google DeepMind
Paris
At #AISTATS2025, I will be giving an "Oral" presentation of our work on "Implicit Diffusion"
arxiv.org/abs/2402.05468
arxiv.org/abs/2402.05468
April 17, 2025 at 12:50 PM
At #AISTATS2025, I will be giving an "Oral" presentation of our work on "Implicit Diffusion"
arxiv.org/abs/2402.05468
arxiv.org/abs/2402.05468
These findings are quite consistent
Our end-to-end method captures a regression and a classification objective, as well as the autoencoder loss.
We see it as "building a bridge" between these different problems.
8/8
Our end-to-end method captures a regression and a classification objective, as well as the autoencoder loss.
We see it as "building a bridge" between these different problems.
8/8

February 10, 2025 at 12:00 PM
These findings are quite consistent
Our end-to-end method captures a regression and a classification objective, as well as the autoencoder loss.
We see it as "building a bridge" between these different problems.
8/8
Our end-to-end method captures a regression and a classification objective, as well as the autoencoder loss.
We see it as "building a bridge" between these different problems.
8/8
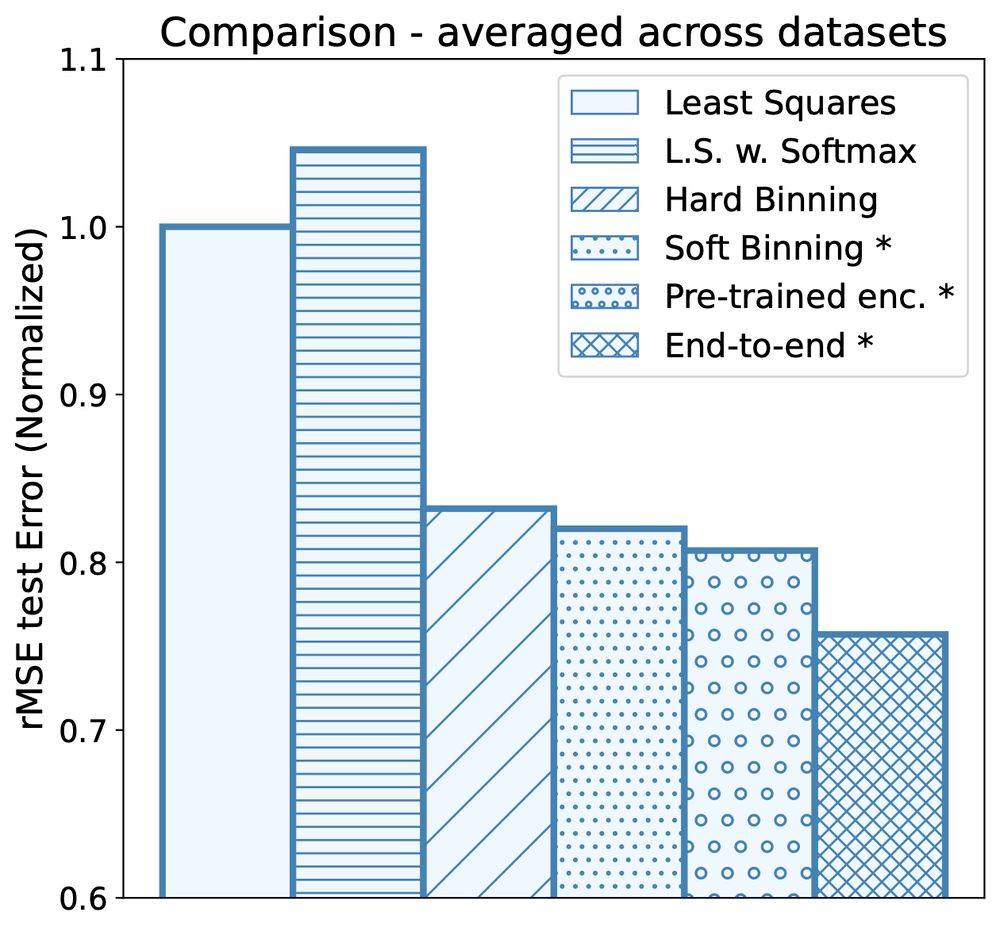
This is a simple generalization from previous binning approaches, the main difference being that we learn the encoding.
We compare different training methods, showing up to 25% improvement on the least-squares baseline error for our full end-to-end method, over 8 datasets.
7/8
We compare different training methods, showing up to 25% improvement on the least-squares baseline error for our full end-to-end method, over 8 datasets.
7/8
February 10, 2025 at 12:00 PM
This is a simple generalization from previous binning approaches, the main difference being that we learn the encoding.
We compare different training methods, showing up to 25% improvement on the least-squares baseline error for our full end-to-end method, over 8 datasets.
7/8
We compare different training methods, showing up to 25% improvement on the least-squares baseline error for our full end-to-end method, over 8 datasets.
7/8
First, the architecture - we use a general target encoder Ψ_w (red, bottom) that transforms the target y in a distribution over k classes
e.g. use softmax(dist) to k different centers
The encoder and the associated decoder μ (in blue) can be trained on an autoencoder loss
5/8
e.g. use softmax(dist) to k different centers
The encoder and the associated decoder μ (in blue) can be trained on an autoencoder loss
5/8

February 10, 2025 at 12:00 PM
First, the architecture - we use a general target encoder Ψ_w (red, bottom) that transforms the target y in a distribution over k classes
e.g. use softmax(dist) to k different centers
The encoder and the associated decoder μ (in blue) can be trained on an autoencoder loss
5/8
e.g. use softmax(dist) to k different centers
The encoder and the associated decoder μ (in blue) can be trained on an autoencoder loss
5/8
The idea is to transform each value of the target into a class one-hot, and to train a classification model to predict the value of the target. (here with y in 2D, with a grid)
It seems strange, but it's been shown to work well in many settings, even for RL applications.
3/8
It seems strange, but it's been shown to work well in many settings, even for RL applications.
3/8

February 10, 2025 at 12:00 PM
The idea is to transform each value of the target into a class one-hot, and to train a classification model to predict the value of the target. (here with y in 2D, with a grid)
It seems strange, but it's been shown to work well in many settings, even for RL applications.
3/8
It seems strange, but it's been shown to work well in many settings, even for RL applications.
3/8
🚨 New paper on regression and classification!
Adding to the discussion on using least-squares or cross-entropy, regression or classification formulations of supervised problems!
A thread on how to bridge these problems:
Adding to the discussion on using least-squares or cross-entropy, regression or classification formulations of supervised problems!
A thread on how to bridge these problems:

February 10, 2025 at 12:00 PM
🚨 New paper on regression and classification!
Adding to the discussion on using least-squares or cross-entropy, regression or classification formulations of supervised problems!
A thread on how to bridge these problems:
Adding to the discussion on using least-squares or cross-entropy, regression or classification formulations of supervised problems!
A thread on how to bridge these problems: