



Hanbo Xie
@psychboyh.bsky.social
Fourth-year PhD student at NRD Lab at Gatech. Interested in how humans and AI think and reason.
Here is another paper demonstrating that people when self-report their weights for attributes for decisions, the reported weights can indeed well predict their own choices by simple logistic regression model.
www.nature.com/articles/s41...
www.nature.com/articles/s41...

Introspective access to value-based multi-attribute choice processes - Nature Communications
People routinely choose between multi-attribute options, such as which movie to watch. Here, the authors show people often have accurate insight into their choices, challenging the notion that people lack self-knowledge about their decision processes.
www.nature.com
October 5, 2025 at 12:32 AM
Here is another paper demonstrating that people when self-report their weights for attributes for decisions, the reported weights can indeed well predict their own choices by simple logistic regression model.
www.nature.com/articles/s41...
www.nature.com/articles/s41...
This result already shows the revealed processes from think aloud, are generative and generalized to their behaviors. The LLM can also learn to reason like humans when giving think aloud examples, which means LLMs not just learn superficial behavioral claims in the think aloud, but also processes.
October 5, 2025 at 12:32 AM
This result already shows the revealed processes from think aloud, are generative and generalized to their behaviors. The LLM can also learn to reason like humans when giving think aloud examples, which means LLMs not just learn superficial behavioral claims in the think aloud, but also processes.
Regarding your question about introspective process,I am afraid I cannot agree that people don’t have introspective access to their computation. What we were validating in the paper is that their think aloud are predictive of their behaviors at current trials as well as other trials.
October 5, 2025 at 12:32 AM
Regarding your question about introspective process,I am afraid I cannot agree that people don’t have introspective access to their computation. What we were validating in the paper is that their think aloud are predictive of their behaviors at current trials as well as other trials.
You can even map the think aloud from semantic space to cognitive space, thus echoing prospect theory which are proposed based on choice behavior before.
openreview.net/forum?id=fEo...
openreview.net/forum?id=fEo...
Text2Decision: Decoding Latent Variables in Risky Decision Making...
Understanding human thoughts can be difficult, as scientists usually rely on observing behaviors. The think-aloud protocol, where people talk about their thoughts while making decisions, provides a...
openreview.net
October 5, 2025 at 12:10 AM
You can even map the think aloud from semantic space to cognitive space, thus echoing prospect theory which are proposed based on choice behavior before.
openreview.net/forum?id=fEo...
openreview.net/forum?id=fEo...
You can also try to extract the algorithms that humans describe about how they sort, which are generalized strategies for this task. openreview.net/forum?id=1Tn...
From Strategic Narratives to Code-Like Cognitive Models: An...
One of the goals of Cognitive Science is to understand the cognitive processes underlying human behavior. Traditionally, this goal has been approached by analyzing simple behaviors, such as choices...
openreview.net
October 5, 2025 at 12:10 AM
You can also try to extract the algorithms that humans describe about how they sort, which are generalized strategies for this task. openreview.net/forum?id=1Tn...
Thanks for your question, Harrison! The process level insight can be descriptive, algorithmic and computational. For example, you can code the think aloud of human participant in mental arithmetic game, which reveals the search process underlying one move.
arxiv.org/abs/2505.23931
arxiv.org/abs/2505.23931

Scaling up the think-aloud method
The think-aloud method, where participants voice their thoughts as they solve a task, is a valuable source of rich data about human reasoning processes. Yet, it has declined in popularity in contempor...
arxiv.org
October 5, 2025 at 12:10 AM
Thanks for your question, Harrison! The process level insight can be descriptive, algorithmic and computational. For example, you can code the think aloud of human participant in mental arithmetic game, which reveals the search process underlying one move.
arxiv.org/abs/2505.23931
arxiv.org/abs/2505.23931
Cool work, Max. You may be interested in one of our very relevant work about LLM and exploration paper, where empowerment is a key concept in the task. This paper also just got accepted at NeurIPS this year😄
arxiv.org/abs/2501.18009
arxiv.org/abs/2501.18009
Large Language Models Think Too Fast To Explore Effectively
Large Language Models (LLMs) have emerged with many intellectual capacities. While numerous benchmarks assess their intelligence, limited attention has been given to their ability to explore--an essen...
arxiv.org
October 2, 2025 at 4:56 AM
Cool work, Max. You may be interested in one of our very relevant work about LLM and exploration paper, where empowerment is a key concept in the task. This paper also just got accepted at NeurIPS this year😄
arxiv.org/abs/2501.18009
arxiv.org/abs/2501.18009
This work is jointly done by @huadongxiong and @doctor-bob.bsky.social
October 2, 2025 at 3:07 AM
This work is jointly done by @huadongxiong and @doctor-bob.bsky.social
OSF
osf.io
October 2, 2025 at 3:06 AM
You are welcome to comment below, share our work, or request codes and data for replication and extension of our work!
January 31, 2025 at 6:50 PM
You are welcome to comment below, share our work, or request codes and data for replication and extension of our work!
In sum, our work uses an open-ended task to evaluate LLM's open-ended exploration capacity and suggest important differences between traditional LLMs and reasoning models in their cognitive capacity. We want to thank @frabraendle.bsky.social , @candemircan.bsky.social and Huadong Xiong for the help!
January 31, 2025 at 6:50 PM
In sum, our work uses an open-ended task to evaluate LLM's open-ended exploration capacity and suggest important differences between traditional LLMs and reasoning models in their cognitive capacity. We want to thank @frabraendle.bsky.social , @candemircan.bsky.social and Huadong Xiong for the help!
These attempts provide evidence that the fallback of traditional LLMs in inference paradigms is not a useful way to solve open-ended exploration problems. Instead, test compute scaling in the reasoning model (or we could say 'spending more time to think') can work.
January 31, 2025 at 6:50 PM
These attempts provide evidence that the fallback of traditional LLMs in inference paradigms is not a useful way to solve open-ended exploration problems. Instead, test compute scaling in the reasoning model (or we could say 'spending more time to think') can work.
In our discussion, we mentioned we have attempted multiple approaches, including prompt engineering, intervention, and seeking model alternatives. None of these approaches changed the situation, except we used the reasoning model, deepseek-r1.
January 31, 2025 at 6:50 PM
In our discussion, we mentioned we have attempted multiple approaches, including prompt engineering, intervention, and seeking model alternatives. None of these approaches changed the situation, except we used the reasoning model, deepseek-r1.
This sounds like the models are 'thinking too fast' with their choices dominated by early representations in the models and did not 'wait' until the model effectively integrates empowerment information, which hinders the traditional LLMs from better performance in this task.
January 31, 2025 at 6:50 PM
This sounds like the models are 'thinking too fast' with their choices dominated by early representations in the models and did not 'wait' until the model effectively integrates empowerment information, which hinders the traditional LLMs from better performance in this task.
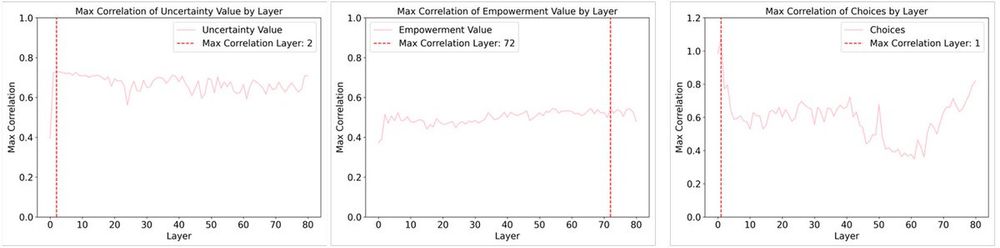
The SAE result suggests that empowerment and uncertainty strategies are represented in LLaMA-3.1 70B, with relatively strong correlations with latent neurons. However, choices and uncertainty are most correlated in early transformer blocks while empowerment is in later blocks.
January 31, 2025 at 6:50 PM
The SAE result suggests that empowerment and uncertainty strategies are represented in LLaMA-3.1 70B, with relatively strong correlations with latent neurons. However, choices and uncertainty are most correlated in early transformer blocks while empowerment is in later blocks.
There are two possibilities. The traditional LLMs do not know about 'empowerment,' or they know it but they overlook it in the information processing! To test these hypotheses, we used Sparse AutoEncoders (SAE) to probe whether and where the models represent those strategies.
January 31, 2025 at 6:50 PM
There are two possibilities. The traditional LLMs do not know about 'empowerment,' or they know it but they overlook it in the information processing! To test these hypotheses, we used Sparse AutoEncoders (SAE) to probe whether and where the models represent those strategies.
The strategy usage well explains why traditional LLMs are worse than humans and why o1 can surpass human performance (effective strategy use!). Then we are curious why traditional LLMs cannot well balance those strategies.
January 31, 2025 at 6:50 PM
The strategy usage well explains why traditional LLMs are worse than humans and why o1 can surpass human performance (effective strategy use!). Then we are curious why traditional LLMs cannot well balance those strategies.
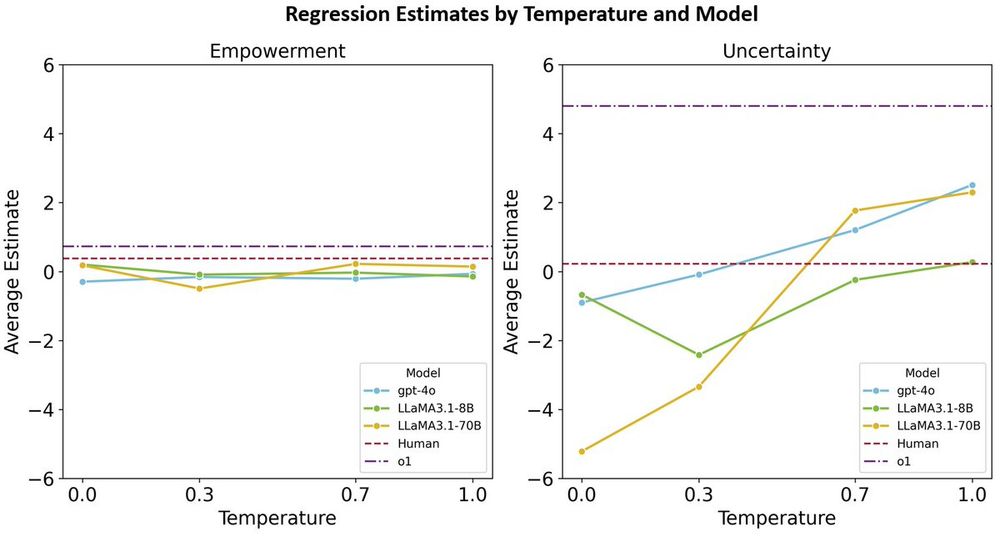
Our results suggest that humans can somehow well balance these two strategies, while traditional LLMs mainly use uncertainty-driven strategies rather than empowerment, which only yields short-term competence when the action space is small. o1 uses both strategies more than humans
January 31, 2025 at 6:50 PM
Our results suggest that humans can somehow well balance these two strategies, while traditional LLMs mainly use uncertainty-driven strategies rather than empowerment, which only yields short-term competence when the action space is small. o1 uses both strategies more than humans
There are two possible strategies for this task: one is uncertainty-driven, where agents explore based on the uncertainty of elements, while the other is empowerment, where agents explore based on an understanding of the task structure (inventory tree).
January 31, 2025 at 6:50 PM
There are two possible strategies for this task: one is uncertainty-driven, where agents explore based on the uncertainty of elements, while the other is empowerment, where agents explore based on an understanding of the task structure (inventory tree).
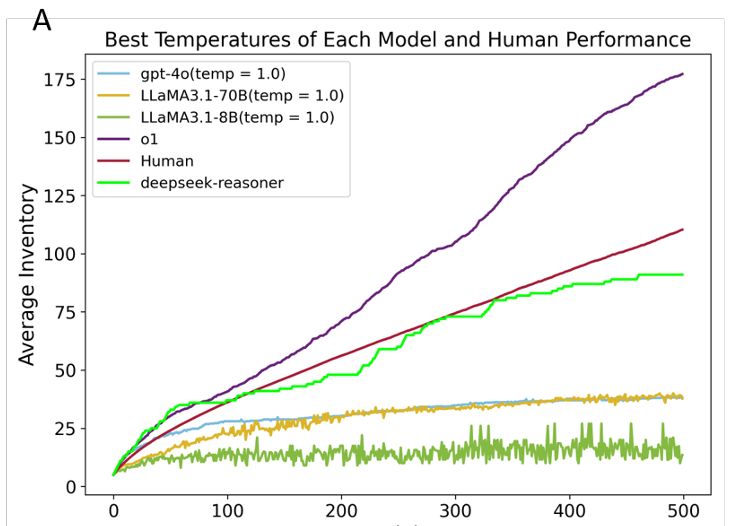
The result is intriguing. For traditional LLMs (GPT-4o, LLaMA-3.1 8B, 70B), their performance is far worse than humans, while for reasoning models like o1 and the popular deepseek-R1 (see appendix), they can surpass or reach human-level performance.
January 31, 2025 at 6:50 PM
The result is intriguing. For traditional LLMs (GPT-4o, LLaMA-3.1 8B, 70B), their performance is far worse than humans, while for reasoning models like o1 and the popular deepseek-R1 (see appendix), they can surpass or reach human-level performance.
Therefore, we borrowed a paradigm with human data from a game-like experiment-'Little Alchemy 2', where agents combine known elements to invent novel ones. We wonder (1) whether LLMs can do better than humans. (2) what strategies and (3) what mechanisms explain the performance?

January 31, 2025 at 6:50 PM
Therefore, we borrowed a paradigm with human data from a game-like experiment-'Little Alchemy 2', where agents combine known elements to invent novel ones. We wonder (1) whether LLMs can do better than humans. (2) what strategies and (3) what mechanisms explain the performance?
Exploration is an important capacity of both natural and artificial intelligence. But people rarely discuss how LLMs can explore. Previous studies mainly focus on bandit tasks, which are closed-form questions. However, exploration can also exist in an open-ended environment.
January 31, 2025 at 6:50 PM
Exploration is an important capacity of both natural and artificial intelligence. But people rarely discuss how LLMs can explore. Previous studies mainly focus on bandit tasks, which are closed-form questions. However, exploration can also exist in an open-ended environment.