



@preslavnakov.bsky.social
Reposted

🌍🌎The global deduplication process was hairy 🙈 - and we want to share every detail.
The TxT360 dedup pipeline can be recreated and used for other datasets. We include our tips and tricks in a tell-all write up in the release blog:
llm360-txt360.hf.space
huggingface.co/spaces/LLM36...
The TxT360 dedup pipeline can be recreated and used for other datasets. We include our tips and tricks in a tell-all write up in the release blog:
llm360-txt360.hf.space
huggingface.co/spaces/LLM36...

TxT360: Trillion Extracted Text - a Hugging Face Space by LLM360
Discover amazing ML apps made by the community
huggingface.co
November 19, 2024 at 10:51 PM
🌍🌎The global deduplication process was hairy 🙈 - and we want to share every detail.
The TxT360 dedup pipeline can be recreated and used for other datasets. We include our tips and tricks in a tell-all write up in the release blog:
llm360-txt360.hf.space
huggingface.co/spaces/LLM36...
The TxT360 dedup pipeline can be recreated and used for other datasets. We include our tips and tricks in a tell-all write up in the release blog:
llm360-txt360.hf.space
huggingface.co/spaces/LLM36...
Reposted
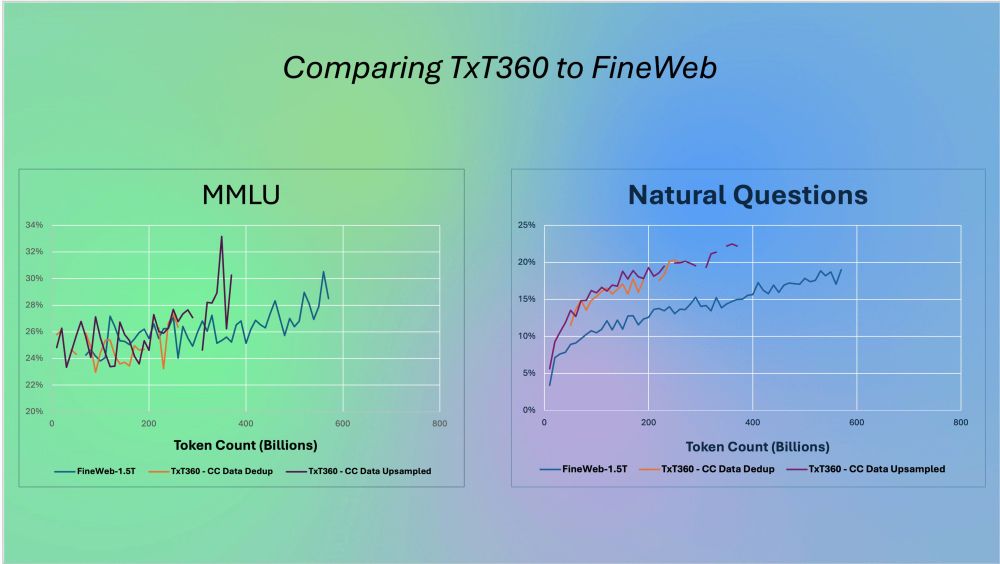
Building on FineWeb’s global deduplication findings, we introduce a strategic upsampling recipe which outperforms FineWeb using TxT360. Full details are in the Upsampling Experiment section of the release blog.
November 19, 2024 at 10:51 PM
Building on FineWeb’s global deduplication findings, we introduce a strategic upsampling recipe which outperforms FineWeb using TxT360. Full details are in the Upsampling Experiment section of the release blog.
Reposted
🪟🛠️LLM360 is committed to making open source AI accessible, transparent, and reproducible.
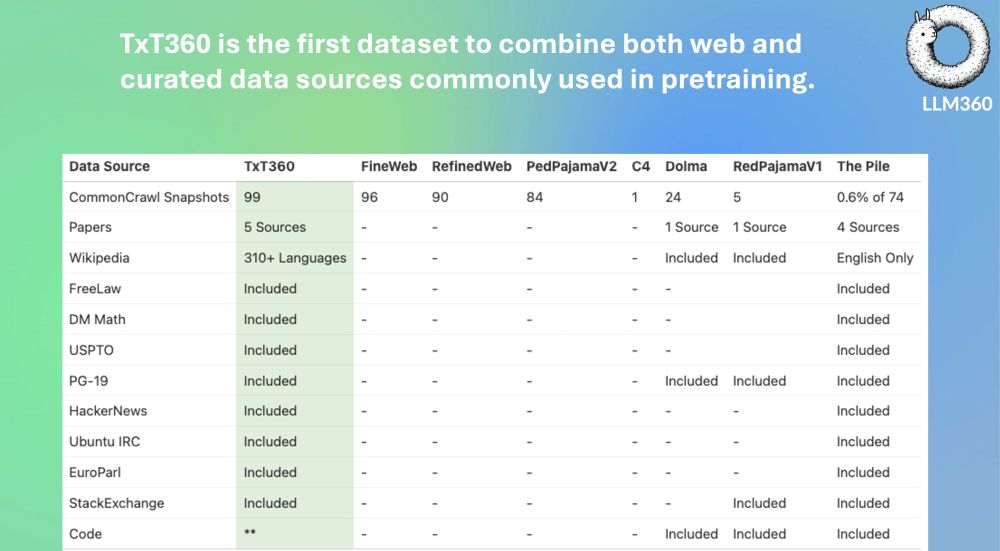
High-quality data is the first step toward better open source models...and we are excited to join the party contributing the first globally deduplicated dataset containing 5.7T tokens!
High-quality data is the first step toward better open source models...and we are excited to join the party contributing the first globally deduplicated dataset containing 5.7T tokens!
November 19, 2024 at 10:51 PM
🪟🛠️LLM360 is committed to making open source AI accessible, transparent, and reproducible.
High-quality data is the first step toward better open source models...and we are excited to join the party contributing the first globally deduplicated dataset containing 5.7T tokens!
High-quality data is the first step toward better open source models...and we are excited to join the party contributing the first globally deduplicated dataset containing 5.7T tokens!