



Prasanna Mayilvahanan
@prasannamayil.bsky.social
PhD student in ML at MPI-IS. Prev Apple.
Interested in robustness at scale and reasoning.
Interested in robustness at scale and reasoning.
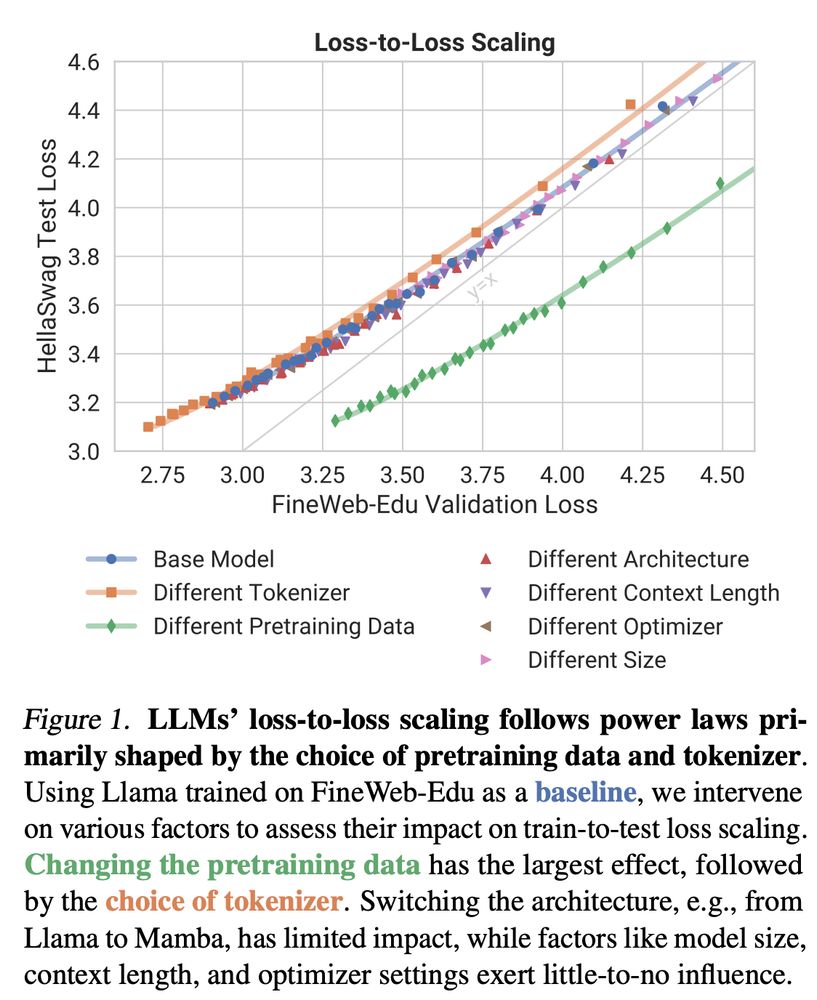
📉 In contrast, architecture, model size, context length, and optimizer settings have negligible impact. This suggests architectures can be freely optimized for efficiency, while data curation is the real key to strong generalization. 5/8

February 18, 2025 at 2:09 PM
📉 In contrast, architecture, model size, context length, and optimizer settings have negligible impact. This suggests architectures can be freely optimized for efficiency, while data curation is the real key to strong generalization. 5/8
📊 Key finding: The choice of pretraining data and tokenizer has the largest impact on scaling trends. Even switching from Llama (Transformer) to Mamba (State-Space Model) barely changes loss-to-loss relationships! 4/8

February 18, 2025 at 2:09 PM
📊 Key finding: The choice of pretraining data and tokenizer has the largest impact on scaling trends. Even switching from Llama (Transformer) to Mamba (State-Space Model) barely changes loss-to-loss relationships! 4/8
We systematically vary pretraining data, tokenizer, architecture (Llama vs. Mamba), model size, context length, and optimizer settings—evaluating over 6000 model checkpoints—to uncover the true drivers of loss-to-loss scaling laws. 3/8

February 18, 2025 at 2:09 PM
We systematically vary pretraining data, tokenizer, architecture (Llama vs. Mamba), model size, context length, and optimizer settings—evaluating over 6000 model checkpoints—to uncover the true drivers of loss-to-loss scaling laws. 3/8
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
February 18, 2025 at 2:09 PM
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8