



Pete Bachant
@petebachant.me
Bicycles, fluid dynamics, Python, open source, open science, reproducibility. https://petebachant.me | https://calkit.org

October 5, 2025 at 3:18 PM
Reading through some slides from 2013 titled "how to succeed in reproducible research without really trying". It's true we have all the tools needed for researchers to build their own reproducible workflows, but still many do not. Maybe the tools are still too hard to learn and use!

October 3, 2025 at 11:47 AM
Reading through some slides from 2013 titled "how to succeed in reproducible research without really trying". It's true we have all the tools needed for researchers to build their own reproducible workflows, but still many do not. Maybe the tools are still too hard to learn and use!
Graphic design is not my passion. Anyone want to collaborate on an infographic to explain the value of fully automating and version controlling research projects?
docs.google.com/drawings/d/1...
#openscience #reproducibility #automation
docs.google.com/drawings/d/1...
#openscience #reproducibility #automation

August 16, 2025 at 3:01 PM
Graphic design is not my passion. Anyone want to collaborate on an infographic to explain the value of fully automating and version controlling research projects?
docs.google.com/drawings/d/1...
#openscience #reproducibility #automation
docs.google.com/drawings/d/1...
#openscience #reproducibility #automation
When you describe the computational methods in your paper without sharing the code and data:
#openscience #reproducibility
#openscience #reproducibility
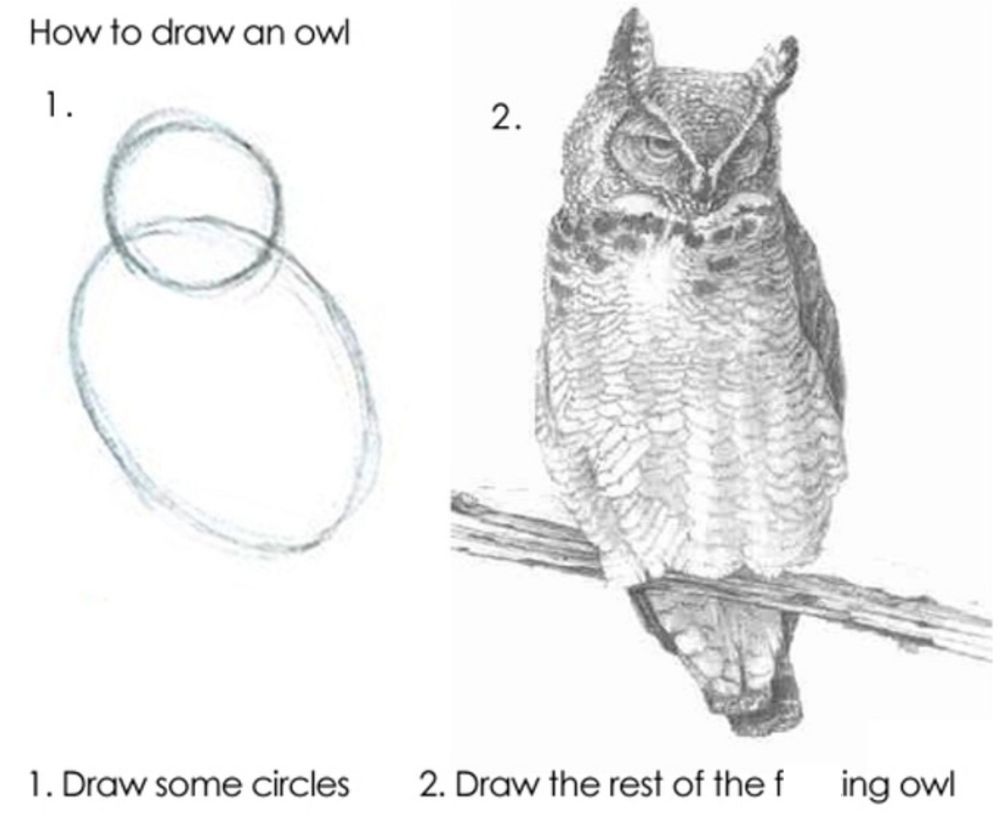
July 21, 2025 at 1:58 PM
When you describe the computational methods in your paper without sharing the code and data:
#openscience #reproducibility
#openscience #reproducibility

July 17, 2025 at 2:28 AM
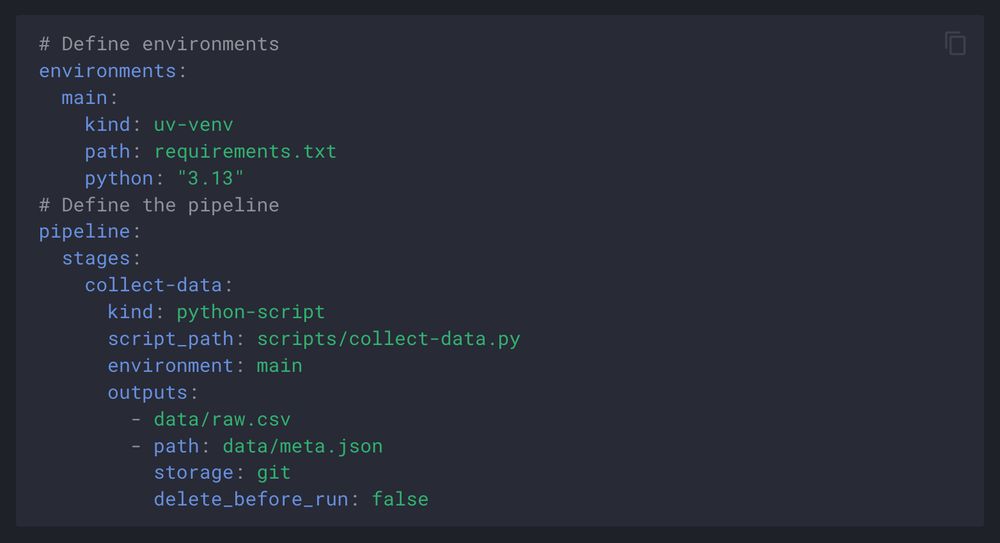
Calkit now has its own pipeline syntax that forces you to define an environment for every stage, but manages those environments for you automatically. No more pip installs, Docker builds, etc. Your project will just be reproducible.
Docs: docs.calkit.org/pipeline/
#reproducibility #openscience
Docs: docs.calkit.org/pipeline/
#reproducibility #openscience
June 6, 2025 at 2:40 PM
Calkit now has its own pipeline syntax that forces you to define an environment for every stage, but manages those environments for you automatically. No more pip installs, Docker builds, etc. Your project will just be reproducible.
Docs: docs.calkit.org/pipeline/
#reproducibility #openscience
Docs: docs.calkit.org/pipeline/
#reproducibility #openscience

May 3, 2025 at 1:26 PM
All research outputs are valuable. Publish them! #openscience

April 29, 2025 at 4:29 PM
All research outputs are valuable. Publish them! #openscience
Put together a little GUI app to help Windows users get set up to do open-source scientific computing, since that can be hard (though Windows has improved a lot over the years)
🔗 github.com/calkit/calki...
#openscience #python #reproducibility
🔗 github.com/calkit/calki...
#openscience #python #reproducibility

April 7, 2025 at 4:24 PM
Put together a little GUI app to help Windows users get set up to do open-source scientific computing, since that can be hard (though Windows has improved a lot over the years)
🔗 github.com/calkit/calki...
#openscience #python #reproducibility
🔗 github.com/calkit/calki...
#openscience #python #reproducibility
I thought MATLAB was supposed to be a convenient self-contained computational environment, but it requires that you manually install additional dependencies.

March 21, 2025 at 12:54 PM
I thought MATLAB was supposed to be a convenient self-contained computational environment, but it requires that you manually install additional dependencies.
This sort of data availability statement is pretty common. I understand not archiving GB or even TB of simulation data, but why not provide the case setups and scripts by default? Is it because the authors assume they aren't useful? Embarrassed by sloppy code? Too much effort to upload?

March 20, 2025 at 3:25 PM
This sort of data availability statement is pretty common. I understand not archiving GB or even TB of simulation data, but why not provide the case setups and scripts by default? Is it because the authors assume they aren't useful? Embarrassed by sloppy code? Too much effort to upload?
The critical event that caused me to abandon MATLAB and get into Python was a license server failure at my university back in 2013. I am now trying to download MATLAB because a collaborator is using it and here's the result...

March 18, 2025 at 12:45 PM
The critical event that caused me to abandon MATLAB and get into Python was a license server failure at my university back in 2013. I am now trying to download MATLAB because a collaborator is using it and here's the result...
🆕 Importing part of one project's dataset(s) into another with Calkit.
I wanted this feature because I have one project that ingests data from an API every day, and another that only needs a very specific subset. This method retains provenance and deduplicates cloud storage.
#opendata
I wanted this feature because I have one project that ingests data from an API every day, and another that only needs a very specific subset. This method retains provenance and deduplicates cloud storage.
#opendata

February 16, 2025 at 12:52 PM
🆕 Importing part of one project's dataset(s) into another with Calkit.
I wanted this feature because I have one project that ingests data from an API every day, and another that only needs a very specific subset. This method retains provenance and deduplicates cloud storage.
#opendata
I wanted this feature because I have one project that ingests data from an API every day, and another that only needs a very specific subset. This method retains provenance and deduplicates cloud storage.
#opendata
I wanted to see weekly distributions of power and heart rate from cycling and running, but Strava doesn't show those, so I put together a little project. As mentioned in my last post, it was my first DuckDB experience 👍 First Polars experience too 👍
🔗 calkit.io/petebachant/strava-analysis
🔗 calkit.io/petebachant/strava-analysis

January 21, 2025 at 8:56 PM
I wanted to see weekly distributions of power and heart rate from cycling and running, but Strava doesn't show those, so I put together a little project. As mentioned in my last post, it was my first DuckDB experience 👍 First Polars experience too 👍
🔗 calkit.io/petebachant/strava-analysis
🔗 calkit.io/petebachant/strava-analysis
First time really using DuckDB and I'm impressed. Querying and joining 1.7M rows from JSON and Parquet files (my own Strava time series data) in SQL and it feels instantaneous.

January 18, 2025 at 2:28 PM
First time really using DuckDB and I'm impressed. Querying and joining 1.7M rows from JSON and Parquet files (my own Strava time series data) in SQL and it feels instantaneous.
Just added a basic #reproducibility check for projects on calkit.io. It doesn't even use AI 😜
Also available via the CLI with `calkit check repro`
Also available via the CLI with `calkit check repro`

December 17, 2024 at 3:31 PM
Just added a basic #reproducibility check for projects on calkit.io. It doesn't even use AI 😜
Also available via the CLI with `calkit check repro`
Also available via the CLI with `calkit check repro`