




Paul Gavrikov
@paulgavrikov.bsky.social
PostDoc Tübingen AI Center | Machine Learning & Computer Vision
paulgavrikov.github.io
paulgavrikov.github.io
Tracking the spookiest runs @weightsbiases.bsky.social

October 30, 2025 at 8:42 AM
Tracking the spookiest runs @weightsbiases.bsky.social
4) Models answer consistently for easy questions ("Is it day?": yes, "Is it night?": no) but fall back to guessing for hard tasks such as reasoning. Concerningly, some models even fall below random chance, hinting at shortcuts.

October 1, 2025 at 1:17 PM
4) Models answer consistently for easy questions ("Is it day?": yes, "Is it night?": no) but fall back to guessing for hard tasks such as reasoning. Concerningly, some models even fall below random chance, hinting at shortcuts.
3) Similar trends for OCR. Our OCR questions contain constraints (e.g., the fifth word) that models often fail to consider. Minor errors include a strong tendency to autocorrect typos or to hallucinate more common spellings, especially in non-Latin/English.

October 1, 2025 at 1:17 PM
3) Similar trends for OCR. Our OCR questions contain constraints (e.g., the fifth word) that models often fail to consider. Minor errors include a strong tendency to autocorrect typos or to hallucinate more common spellings, especially in non-Latin/English.
2) Models cannot count in dense scenes, and the performance gets worse the larger the number of objects; they typically "undercount" and errors are massive. Here is the distribution over all models:

October 1, 2025 at 1:17 PM
2) Models cannot count in dense scenes, and the performance gets worse the larger the number of objects; they typically "undercount" and errors are massive. Here is the distribution over all models:
Our questions are built on top of a fresh dataset of 150 high-resolution and detailed scenes probing core vision skills in 6 categories: counting, OCR, reasoning, activity/attribute/global scene recognition. The ground truth is private, and our eval server is live!

October 1, 2025 at 1:17 PM
Our questions are built on top of a fresh dataset of 150 high-resolution and detailed scenes probing core vision skills in 6 categories: counting, OCR, reasoning, activity/attribute/global scene recognition. The ground truth is private, and our eval server is live!
🚨 New paper out!
"VisualOverload: Probing Visual Understanding of VLMs in Really Dense Scenes"
👉 arxiv.org/abs/2509.25339
We test 37 VLMs on 2,700+ VQA questions about dense scenes.
Findings: even top models fumble badly—<20% on the hardest split and key failure modes in counting, OCR & consistency.
"VisualOverload: Probing Visual Understanding of VLMs in Really Dense Scenes"
👉 arxiv.org/abs/2509.25339
We test 37 VLMs on 2,700+ VQA questions about dense scenes.
Findings: even top models fumble badly—<20% on the hardest split and key failure modes in counting, OCR & consistency.

October 1, 2025 at 1:17 PM
🚨 New paper out!
"VisualOverload: Probing Visual Understanding of VLMs in Really Dense Scenes"
👉 arxiv.org/abs/2509.25339
We test 37 VLMs on 2,700+ VQA questions about dense scenes.
Findings: even top models fumble badly—<20% on the hardest split and key failure modes in counting, OCR & consistency.
"VisualOverload: Probing Visual Understanding of VLMs in Really Dense Scenes"
👉 arxiv.org/abs/2509.25339
We test 37 VLMs on 2,700+ VQA questions about dense scenes.
Findings: even top models fumble badly—<20% on the hardest split and key failure modes in counting, OCR & consistency.
Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.

September 8, 2025 at 3:28 PM
Is basic image understanding solved in today’s SOTA VLMs? Not quite.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
We present VisualOverload, a VQA benchmark testing simple vision skills (like counting & OCR) in dense scenes. Even the best model (o3) only scores 19.8% on our hardest split.
What an incredible week at #ICLR 2025! 🌟
I had an amazing time presenting our poster "Can We Talk Models Into Seeing the World Differently?" with
@jovitalukasik.bsky.social. Huge thanks to everyone who stopped by — your questions, insights, and conversations made it such a rewarding experience.
I had an amazing time presenting our poster "Can We Talk Models Into Seeing the World Differently?" with
@jovitalukasik.bsky.social. Huge thanks to everyone who stopped by — your questions, insights, and conversations made it such a rewarding experience.



May 3, 2025 at 10:03 AM
What an incredible week at #ICLR 2025! 🌟
I had an amazing time presenting our poster "Can We Talk Models Into Seeing the World Differently?" with
@jovitalukasik.bsky.social. Huge thanks to everyone who stopped by — your questions, insights, and conversations made it such a rewarding experience.
I had an amazing time presenting our poster "Can We Talk Models Into Seeing the World Differently?" with
@jovitalukasik.bsky.social. Huge thanks to everyone who stopped by — your questions, insights, and conversations made it such a rewarding experience.
On Thursday, I'll be presenting our paper "Can We Talk Models Into Seeing the World Differently?" (#328) at ICLR 2025 in Singapore! If you're attending or just around Singapore, l'd love to connect—feel free to reach out! Also, I’m exploring postdoc or industry opportunities–happy to chat!
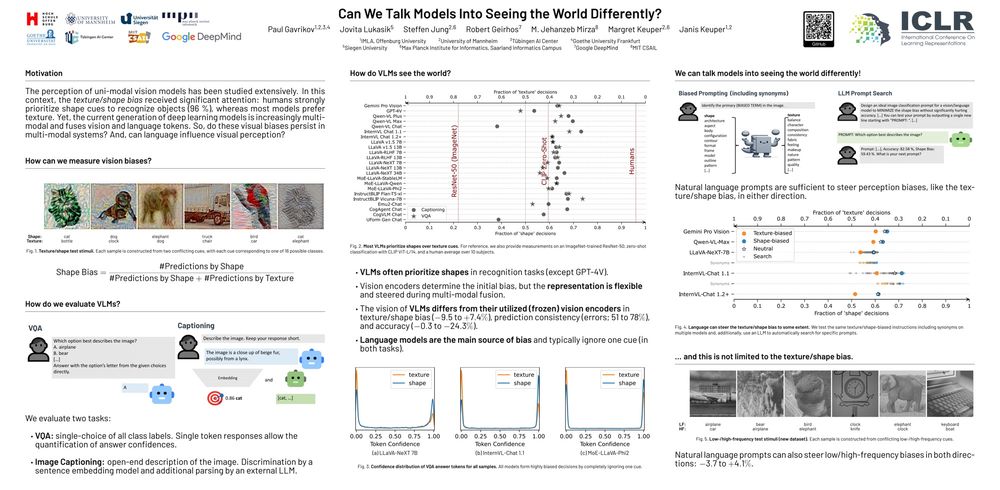
April 21, 2025 at 10:47 AM
On Thursday, I'll be presenting our paper "Can We Talk Models Into Seeing the World Differently?" (#328) at ICLR 2025 in Singapore! If you're attending or just around Singapore, l'd love to connect—feel free to reach out! Also, I’m exploring postdoc or industry opportunities–happy to chat!
Proud to announce that our paper "Can We Talk Models Into Seeing the World Differently?" was accepted at #ICLR2025 🇸🇬. This marks my last PhD paper, and we are honored that all 4 reviewers recommended acceptance, placing us in the top 6% of all submissions.

January 27, 2025 at 5:33 PM
Proud to announce that our paper "Can We Talk Models Into Seeing the World Differently?" was accepted at #ICLR2025 🇸🇬. This marks my last PhD paper, and we are honored that all 4 reviewers recommended acceptance, placing us in the top 6% of all submissions.
I analyzed the top 20 most common words in titles of all computer vision (cs.CV) papers on arxiv since 2007. A lot of "learning" papers ...

January 13, 2025 at 2:32 PM
I analyzed the top 20 most common words in titles of all computer vision (cs.CV) papers on arxiv since 2007. A lot of "learning" papers ...
Yeah, I am sure my paper on Feature Biases in ImageNet classifiers is a great match for a journal on lifestyle and sustainable goals.

December 16, 2024 at 10:55 PM
Yeah, I am sure my paper on Feature Biases in ImageNet classifiers is a great match for a journal on lifestyle and sustainable goals.
Today at #NeurIPS2024 Interpretable AI Workshop! Poster sessions are at 10am and 4pm.
"How Do Training Methods Influence the Utilization of Vision Models?" arxiv.org/abs/2410.14470
We won’t be there, but Ruta Binkyte is presenting for us!
"How Do Training Methods Influence the Utilization of Vision Models?" arxiv.org/abs/2410.14470
We won’t be there, but Ruta Binkyte is presenting for us!

December 15, 2024 at 1:52 PM
Today at #NeurIPS2024 Interpretable AI Workshop! Poster sessions are at 10am and 4pm.
"How Do Training Methods Influence the Utilization of Vision Models?" arxiv.org/abs/2410.14470
We won’t be there, but Ruta Binkyte is presenting for us!
"How Do Training Methods Influence the Utilization of Vision Models?" arxiv.org/abs/2410.14470
We won’t be there, but Ruta Binkyte is presenting for us!
One of the most interesting aspects of adversarial training to me is not that it increases robustness, but it's ability to revert biases. If a model is strongly biased for X, it will likely completely ignore X at sufficient eps. This is clearly visible in the texture/shape bias!

December 7, 2024 at 10:18 AM
One of the most interesting aspects of adversarial training to me is not that it increases robustness, but it's ability to revert biases. If a model is strongly biased for X, it will likely completely ignore X at sufficient eps. This is clearly visible in the texture/shape bias!
Tired of showing the same old same adversarial attack examples? Generate your own with this little Foolbox-based Colab: colab.research.google.com/drive/1WfqEW...

November 29, 2024 at 1:57 PM
Tired of showing the same old same adversarial attack examples? Generate your own with this little Foolbox-based Colab: colab.research.google.com/drive/1WfqEW...
WILD! Some researchers from have republished ResNet under their own names at some predatory journal.
@csprofkgd.bsky.social
Predatory: ijircce.com/admin/main/s...
@csprofkgd.bsky.social
Predatory: ijircce.com/admin/main/s...


November 28, 2024 at 10:57 AM
WILD! Some researchers from have republished ResNet under their own names at some predatory journal.
@csprofkgd.bsky.social
Predatory: ijircce.com/admin/main/s...
@csprofkgd.bsky.social
Predatory: ijircce.com/admin/main/s...
