



Reposted by Anil Kumar

Our recent presentation from the Impact Scholars Program at @neuromatch.bsky.social - Neuromatch Academy!
www.youtube.com/watch?v=F5_z...
Statistical and deep learning models acted as “sensors” for task demand and WM activity, predicting how much WM is involved in emotion and language domains.
www.youtube.com/watch?v=F5_z...
Statistical and deep learning models acted as “sensors” for task demand and WM activity, predicting how much WM is involved in emotion and language domains.

Working Memory Involvement in Higher Cognition: Insights from fMRI Modeling
YouTube video by Neuromatch Academy
www.youtube.com
April 18, 2025 at 3:46 PM
Our recent presentation from the Impact Scholars Program at @neuromatch.bsky.social - Neuromatch Academy!
www.youtube.com/watch?v=F5_z...
Statistical and deep learning models acted as “sensors” for task demand and WM activity, predicting how much WM is involved in emotion and language domains.
www.youtube.com/watch?v=F5_z...
Statistical and deep learning models acted as “sensors” for task demand and WM activity, predicting how much WM is involved in emotion and language domains.
Reposted by Anil Kumar

We are introducing the world's first Scientific Superintelligence platform for life, chemical and materials sciences. Join our Mission www.lila.ai/news/join-ou...

Join Our Mission | Lila Sciences
Lila Sciences unveils the first-ever scientific superintelligence platform, securing $200M in funding to revolutionize discovery in life, chemical, and…
www.lila.ai
March 10, 2025 at 3:24 PM
We are introducing the world's first Scientific Superintelligence platform for life, chemical and materials sciences. Join our Mission www.lila.ai/news/join-ou...
Reposted by Anil Kumar

🚨 Heads up, Pythonistas 🚨
Something exciting is coming and you won’t want to miss it...PyCon UK 2025 Call for Proposals is opening soon! 🚀🐍
If you've got an idea for a talk, a workshop, or a Young Coders' session, we want to hear from you! 📝✨
👀 Stay tuned 👀
#PyConUK2025 #python #development #CFP
Something exciting is coming and you won’t want to miss it...PyCon UK 2025 Call for Proposals is opening soon! 🚀🐍
If you've got an idea for a talk, a workshop, or a Young Coders' session, we want to hear from you! 📝✨
👀 Stay tuned 👀
#PyConUK2025 #python #development #CFP
March 5, 2025 at 9:30 AM
🚨 Heads up, Pythonistas 🚨
Something exciting is coming and you won’t want to miss it...PyCon UK 2025 Call for Proposals is opening soon! 🚀🐍
If you've got an idea for a talk, a workshop, or a Young Coders' session, we want to hear from you! 📝✨
👀 Stay tuned 👀
#PyConUK2025 #python #development #CFP
Something exciting is coming and you won’t want to miss it...PyCon UK 2025 Call for Proposals is opening soon! 🚀🐍
If you've got an idea for a talk, a workshop, or a Young Coders' session, we want to hear from you! 📝✨
👀 Stay tuned 👀
#PyConUK2025 #python #development #CFP
Reposted by Anil Kumar

🚨 New Preprint!!
LLMs trained on next-word prediction (NWP) show high alignment with brain recordings. But what drives this alignment—linguistic structure or world knowledge? And how does this alignment evolve during training? Our new paper explores these questions. 👇🧵
LLMs trained on next-word prediction (NWP) show high alignment with brain recordings. But what drives this alignment—linguistic structure or world knowledge? And how does this alignment evolve during training? Our new paper explores these questions. 👇🧵

March 5, 2025 at 3:58 PM
🚨 New Preprint!!
LLMs trained on next-word prediction (NWP) show high alignment with brain recordings. But what drives this alignment—linguistic structure or world knowledge? And how does this alignment evolve during training? Our new paper explores these questions. 👇🧵
LLMs trained on next-word prediction (NWP) show high alignment with brain recordings. But what drives this alignment—linguistic structure or world knowledge? And how does this alignment evolve during training? Our new paper explores these questions. 👇🧵
Two Kinds Of AI
open.substack.com/pub/zerothpr...
open.substack.com/pub/zerothpr...

Two Kinds Of AI
Polar Opposites
open.substack.com
February 27, 2025 at 4:31 PM
Two Kinds Of AI
open.substack.com/pub/zerothpr...
open.substack.com/pub/zerothpr...

Reposted by Anil Kumar

Every living system must adapt, or die.
In my first blog post, I show how this fundamental principle can be mathematized:
✅ Brains adapt, and adaptation is about KL divergence minimization.
Let's unpack the main insights 🧵[1/n]
Link: mysterioustune.com/2025/01/13/w...
🧠🤖🧠📈 #AI
In my first blog post, I show how this fundamental principle can be mathematized:
✅ Brains adapt, and adaptation is about KL divergence minimization.
Let's unpack the main insights 🧵[1/n]
Link: mysterioustune.com/2025/01/13/w...
🧠🤖🧠📈 #AI

January 14, 2025 at 7:53 AM
Every living system must adapt, or die.
In my first blog post, I show how this fundamental principle can be mathematized:
✅ Brains adapt, and adaptation is about KL divergence minimization.
Let's unpack the main insights 🧵[1/n]
Link: mysterioustune.com/2025/01/13/w...
🧠🤖🧠📈 #AI
In my first blog post, I show how this fundamental principle can be mathematized:
✅ Brains adapt, and adaptation is about KL divergence minimization.
Let's unpack the main insights 🧵[1/n]
Link: mysterioustune.com/2025/01/13/w...
🧠🤖🧠📈 #AI
Sounds scary

It would be easy, technically, to give chatbots more persistent identity. E.g. ChatGPT is *told* to remember only things about the user, not about itself. I don’t see that changing rapidly, because the obstacle isn’t technical—it’s presumably that there’s little benefit in freaking customers out? +
January 4, 2025 at 3:48 PM
Sounds scary

Reposted by Anil Kumar

There’s a single formula that makes all of your diffusion models possible: Tweedie's
Say 𝐱 is a noisy version of 𝐮 with 𝐞 ∼ 𝒩(𝟎, σ² 𝐈)
𝐱 = 𝐮 + 𝐞
MMSE estimate of 𝐮 is 𝔼[𝐮|𝐱] & would seem to require P(𝐮|𝐱). Yet Tweedie says P(𝐱) is all you need
1/3
Say 𝐱 is a noisy version of 𝐮 with 𝐞 ∼ 𝒩(𝟎, σ² 𝐈)
𝐱 = 𝐮 + 𝐞
MMSE estimate of 𝐮 is 𝔼[𝐮|𝐱] & would seem to require P(𝐮|𝐱). Yet Tweedie says P(𝐱) is all you need
1/3

November 22, 2024 at 9:45 PM
There’s a single formula that makes all of your diffusion models possible: Tweedie's
Say 𝐱 is a noisy version of 𝐮 with 𝐞 ∼ 𝒩(𝟎, σ² 𝐈)
𝐱 = 𝐮 + 𝐞
MMSE estimate of 𝐮 is 𝔼[𝐮|𝐱] & would seem to require P(𝐮|𝐱). Yet Tweedie says P(𝐱) is all you need
1/3
Say 𝐱 is a noisy version of 𝐮 with 𝐞 ∼ 𝒩(𝟎, σ² 𝐈)
𝐱 = 𝐮 + 𝐞
MMSE estimate of 𝐮 is 𝔼[𝐮|𝐱] & would seem to require P(𝐮|𝐱). Yet Tweedie says P(𝐱) is all you need
1/3
Reposted by Anil Kumar


Reposted by Anil Kumar

If you want a very accessible intro (I wrote it so my parents could read it) intro to AI and games, here's my earlier book from 2019:
mitpress.mit.edu/978026203903...
mitpress.mit.edu/978026203903...

Playing Smart
A new vision of the future of games and game design, enabled by AI.Can games measure intelligence? How will artificial intelligence inform games of the futur...
mitpress.mit.edu
November 25, 2024 at 5:04 AM
If you want a very accessible intro (I wrote it so my parents could read it) intro to AI and games, here's my earlier book from 2019:
mitpress.mit.edu/978026203903...
mitpress.mit.edu/978026203903...
Reposted by Anil Kumar

Why are some LLMs better at chess than others
Part 1: dynomight.net/chess/
Part 2: dynomight.net/more-chess/
Part 1: dynomight.net/chess/
Part 2: dynomight.net/more-chess/

Something weird is happening with LLMs and chess
are they good or bad?
dynomight.net
November 22, 2024 at 4:16 PM
Why are some LLMs better at chess than others
Part 1: dynomight.net/chess/
Part 2: dynomight.net/more-chess/
Part 1: dynomight.net/chess/
Part 2: dynomight.net/more-chess/
Reposted by Anil Kumar

Huge congrats to @karyna-mi.bsky.social for her paper published today in Science! She found that the hippocampus is really important for a key strategy we use to make decisions called hidden state inference! 🧪 🧠https://www.science.org/doi/10.1126/science.adq5874 1/7
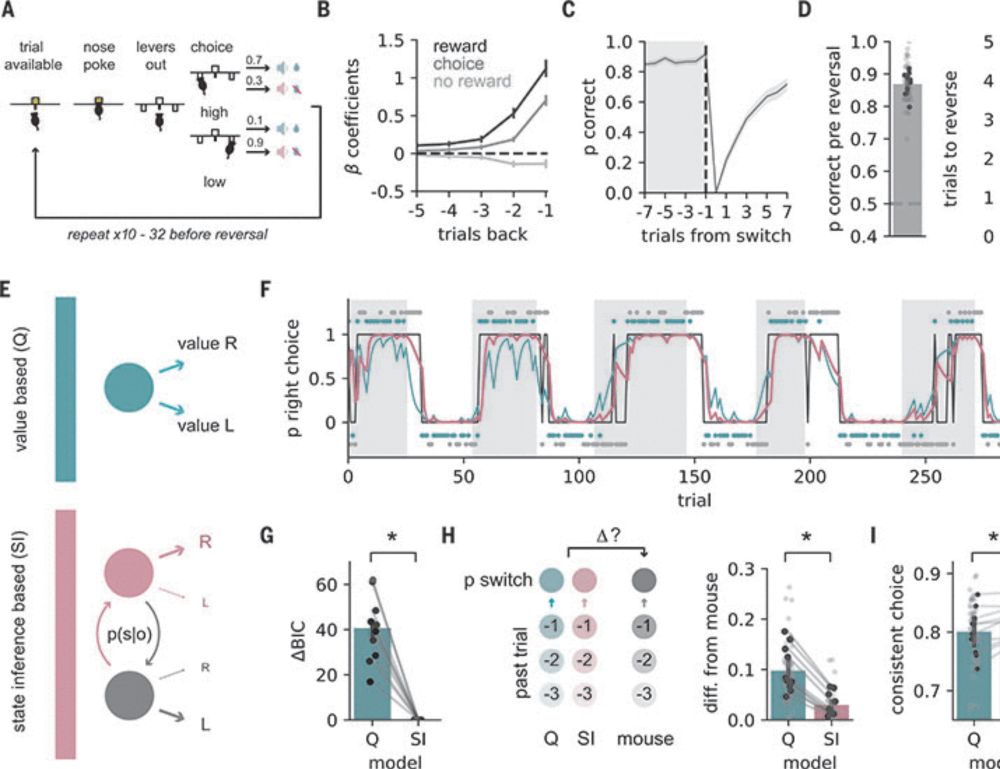
Hidden state inference requires abstract contextual representations in the ventral hippocampus
The ability to use subjective, latent contextual representations to influence decision-making is crucial for everyday life. The hippocampus is hypothesized to bind together otherwise abstract combinat...
www.science.org
November 22, 2024 at 1:20 PM
Huge congrats to @karyna-mi.bsky.social for her paper published today in Science! She found that the hippocampus is really important for a key strategy we use to make decisions called hidden state inference! 🧪 🧠https://www.science.org/doi/10.1126/science.adq5874 1/7
Reposted by Anil Kumar

Curious to learn what research is looking like at Meta these days. Seems that most other places are shutting down research. I’d like to think that this means we will be stagnate once LLMs hit any nontrivial wall. Thoughts welcome on this too.
November 19, 2024 at 11:25 PM
Curious to learn what research is looking like at Meta these days. Seems that most other places are shutting down research. I’d like to think that this means we will be stagnate once LLMs hit any nontrivial wall. Thoughts welcome on this too.
Reposted by Anil Kumar



Reposted by Anil Kumar

Any ex-FAANG data & ML nerds want to apply their battle-honed skills to a worthwhile cause.. here is a baby social network with a fully open protocol and no scaled-up analytics infra.
Now is a great time to build some basic pipelines & dashboards that bootstrap an open🦋stats community
Now is a great time to build some basic pipelines & dashboards that bootstrap an open🦋stats community

90 days ago Bluesky had 6.18M users
30 days ago Bluesky had 10.85M users
Tomorrow Bluesky will have 15M users
This is absolutely wild, thanks for believing in us y'all
30 days ago Bluesky had 10.85M users
Tomorrow Bluesky will have 15M users
This is absolutely wild, thanks for believing in us y'all
November 13, 2024 at 12:25 PM
Any ex-FAANG data & ML nerds want to apply their battle-honed skills to a worthwhile cause.. here is a baby social network with a fully open protocol and no scaled-up analytics infra.
Now is a great time to build some basic pipelines & dashboards that bootstrap an open🦋stats community
Now is a great time to build some basic pipelines & dashboards that bootstrap an open🦋stats community
Reposted by Anil Kumar

Why the world needs less AI and better programming languages.
"Moral Codes" by Alan Blackwell is available now in paperback and a free downloadable #openaccess edition 👉 mitpress.mit.edu/978026254871...
"Moral Codes" by Alan Blackwell is available now in paperback and a free downloadable #openaccess edition 👉 mitpress.mit.edu/978026254871...

November 11, 2024 at 5:31 PM
Why the world needs less AI and better programming languages.
"Moral Codes" by Alan Blackwell is available now in paperback and a free downloadable #openaccess edition 👉 mitpress.mit.edu/978026254871...
"Moral Codes" by Alan Blackwell is available now in paperback and a free downloadable #openaccess edition 👉 mitpress.mit.edu/978026254871...


