



Nicolas Zucchet
@nzucchet.bsky.social
PhD Student @ ETH Zurich
Previously: Student Researcher @ Google DeepMind, @École polytechnique
https://nicolaszucchet.github.io
Previously: Student Researcher @ Google DeepMind, @École polytechnique
https://nicolaszucchet.github.io
Haven’t tried this. My guess would be that you need the same fact to be repeated across multiple batches (ie training steps) for the effect to be visible.
April 4, 2025 at 7:13 PM
Haven’t tried this. My guess would be that you need the same fact to be repeated across multiple batches (ie training steps) for the effect to be visible.
Thanks to my co-authors @jb.capsec.org,
@scychan.bsky.social, @lampinen.bsky.social, @razvan-pascanu.bsky.social, and @soham-de.bsky.social. I couldn't have dreamed of a better team for this collaboration!
Check out the full paper for all the technical details arxiv.org/abs/2503.21676.
@scychan.bsky.social, @lampinen.bsky.social, @razvan-pascanu.bsky.social, and @soham-de.bsky.social. I couldn't have dreamed of a better team for this collaboration!
Check out the full paper for all the technical details arxiv.org/abs/2503.21676.

How do language models learn facts? Dynamics, curricula and hallucinations
Large language models accumulate vast knowledge during pre-training, yet the dynamics governing this acquisition remain poorly understood. This work investigates the learning dynamics of language mode...
arxiv.org
April 3, 2025 at 12:21 PM
Thanks to my co-authors @jb.capsec.org,
@scychan.bsky.social, @lampinen.bsky.social, @razvan-pascanu.bsky.social, and @soham-de.bsky.social. I couldn't have dreamed of a better team for this collaboration!
Check out the full paper for all the technical details arxiv.org/abs/2503.21676.
@scychan.bsky.social, @lampinen.bsky.social, @razvan-pascanu.bsky.social, and @soham-de.bsky.social. I couldn't have dreamed of a better team for this collaboration!
Check out the full paper for all the technical details arxiv.org/abs/2503.21676.
Our work suggests practical LLM training strategies:
1. use synthetic data early as plateau phase data isn't retained anyway
2. implement dynamic data schedulers that use low diversity during plateaus and high diversity afterward (which is similar to how we learn as infants!)
1. use synthetic data early as plateau phase data isn't retained anyway
2. implement dynamic data schedulers that use low diversity during plateaus and high diversity afterward (which is similar to how we learn as infants!)
April 3, 2025 at 12:21 PM
Our work suggests practical LLM training strategies:
1. use synthetic data early as plateau phase data isn't retained anyway
2. implement dynamic data schedulers that use low diversity during plateaus and high diversity afterward (which is similar to how we learn as infants!)
1. use synthetic data early as plateau phase data isn't retained anyway
2. implement dynamic data schedulers that use low diversity during plateaus and high diversity afterward (which is similar to how we learn as infants!)
Hallucinations emerge with knowledge. As models learn facts about seen individuals, they also make overconfident predictions about unseen ones.
On top of that, fine-tuning struggles to add new knowledge: existing memories are quickly corrupted when learning new ones.
On top of that, fine-tuning struggles to add new knowledge: existing memories are quickly corrupted when learning new ones.

April 3, 2025 at 12:21 PM
Hallucinations emerge with knowledge. As models learn facts about seen individuals, they also make overconfident predictions about unseen ones.
On top of that, fine-tuning struggles to add new knowledge: existing memories are quickly corrupted when learning new ones.
On top of that, fine-tuning struggles to add new knowledge: existing memories are quickly corrupted when learning new ones.
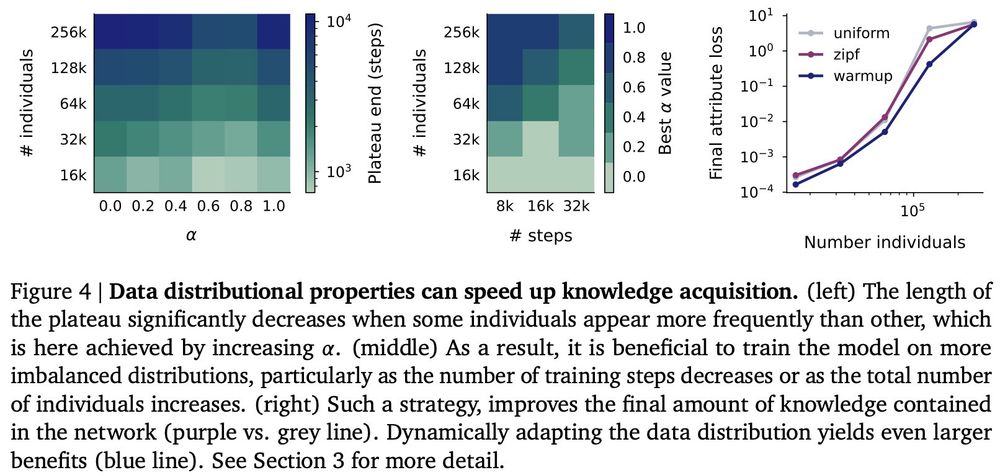
The training data distribution has a massive impact on learning. Imbalanced distributions (some individuals appearing more frequently) accelerate the plateau phase.
This suggests exciting new data scheduling strategies for training - we show that a simple warmup works well!
This suggests exciting new data scheduling strategies for training - we show that a simple warmup works well!
April 3, 2025 at 12:21 PM
The training data distribution has a massive impact on learning. Imbalanced distributions (some individuals appearing more frequently) accelerate the plateau phase.
This suggests exciting new data scheduling strategies for training - we show that a simple warmup works well!
This suggests exciting new data scheduling strategies for training - we show that a simple warmup works well!
During that plateau, something crucial happens: the model builds the attention-based circuits that enable recall.
This is when the model learns how to recall facts, and it only remembers specific facts afterward!
This is when the model learns how to recall facts, and it only remembers specific facts afterward!

April 3, 2025 at 12:21 PM
During that plateau, something crucial happens: the model builds the attention-based circuits that enable recall.
This is when the model learns how to recall facts, and it only remembers specific facts afterward!
This is when the model learns how to recall facts, and it only remembers specific facts afterward!
We studied how models learn on a synthetic biography task and found three key phases in knowledge acquisition:
1. Models initially learn generic statistics
2. Performance plateaus while attention-based circuits form
3. Knowledge emerges as models learn individual-specific facts
1. Models initially learn generic statistics
2. Performance plateaus while attention-based circuits form
3. Knowledge emerges as models learn individual-specific facts

April 3, 2025 at 12:21 PM
We studied how models learn on a synthetic biography task and found three key phases in knowledge acquisition:
1. Models initially learn generic statistics
2. Performance plateaus while attention-based circuits form
3. Knowledge emerges as models learn individual-specific facts
1. Models initially learn generic statistics
2. Performance plateaus while attention-based circuits form
3. Knowledge emerges as models learn individual-specific facts