




Nur Lan
@nurikolan.bsky.social
Sorry, missed the G&H ref!
Re: precision I meant that there's a chance that the "compressed" network is in practice not a bottleneck if it can store the same/approx. solution as the larger net in high precision weights.
Would be interesting to see how it does when quantized (either at test/train)
Re: precision I meant that there's a chance that the "compressed" network is in practice not a bottleneck if it can store the same/approx. solution as the larger net in high precision weights.
Would be interesting to see how it does when quantized (either at test/train)
November 29, 2024 at 11:16 PM
Sorry, missed the G&H ref!
Re: precision I meant that there's a chance that the "compressed" network is in practice not a bottleneck if it can store the same/approx. solution as the larger net in high precision weights.
Would be interesting to see how it does when quantized (either at test/train)
Re: precision I meant that there's a chance that the "compressed" network is in practice not a bottleneck if it can store the same/approx. solution as the larger net in high precision weights.
Would be interesting to see how it does when quantized (either at test/train)
Hi, interesting work. Did you try limiting the precision of the "compressed" network? Number of params is a very crude proxy for the actual information capacity.
See e.g. aclanthology.org/2024.acl-lon... and doi.org/10.1162/tacl...
and very similar work by Gaier & Ha 2019 arxiv.org/abs/1906.04358
See e.g. aclanthology.org/2024.acl-lon... and doi.org/10.1162/tacl...
and very similar work by Gaier & Ha 2019 arxiv.org/abs/1906.04358
November 29, 2024 at 5:56 PM
Hi, interesting work. Did you try limiting the precision of the "compressed" network? Number of params is a very crude proxy for the actual information capacity.
See e.g. aclanthology.org/2024.acl-lon... and doi.org/10.1162/tacl...
and very similar work by Gaier & Ha 2019 arxiv.org/abs/1906.04358
See e.g. aclanthology.org/2024.acl-lon... and doi.org/10.1162/tacl...
and very similar work by Gaier & Ha 2019 arxiv.org/abs/1906.04358
Our findings are in line with works such as El-Naggar et al. (2023) who found similar shortcomings of common objectives for other archs:
proceedings.mlr.press/v217/el-nagg...
As well as with our MDL RNNs who achieve perfect generalization on aⁿbⁿ, Dyck-1, etc:
direct.mit.edu/tacl/article...
3/3
proceedings.mlr.press/v217/el-nagg...
As well as with our MDL RNNs who achieve perfect generalization on aⁿbⁿ, Dyck-1, etc:
direct.mit.edu/tacl/article...
3/3

Minimum Description Length Recurrent Neural Networks
Abstract. We train neural networks to optimize a Minimum Description Length score, that is, to balance between the complexity of the network and its accuracy at a task. We show that networks optimizin...
direct.mit.edu
February 17, 2024 at 6:19 PM
Our findings are in line with works such as El-Naggar et al. (2023) who found similar shortcomings of common objectives for other archs:
proceedings.mlr.press/v217/el-nagg...
As well as with our MDL RNNs who achieve perfect generalization on aⁿbⁿ, Dyck-1, etc:
direct.mit.edu/tacl/article...
3/3
proceedings.mlr.press/v217/el-nagg...
As well as with our MDL RNNs who achieve perfect generalization on aⁿbⁿ, Dyck-1, etc:
direct.mit.edu/tacl/article...
3/3
We build an optimal aⁿbⁿ LSTM based on @gail_w et al. (2018) and find that it is not an optimum of the standard cross-entropy loss, even with regularization terms that are expected to lead good generalization (L1/L2).
Meta-heuristics (early stop, dropout) don't help either.
2/3
Meta-heuristics (early stop, dropout) don't help either.
2/3
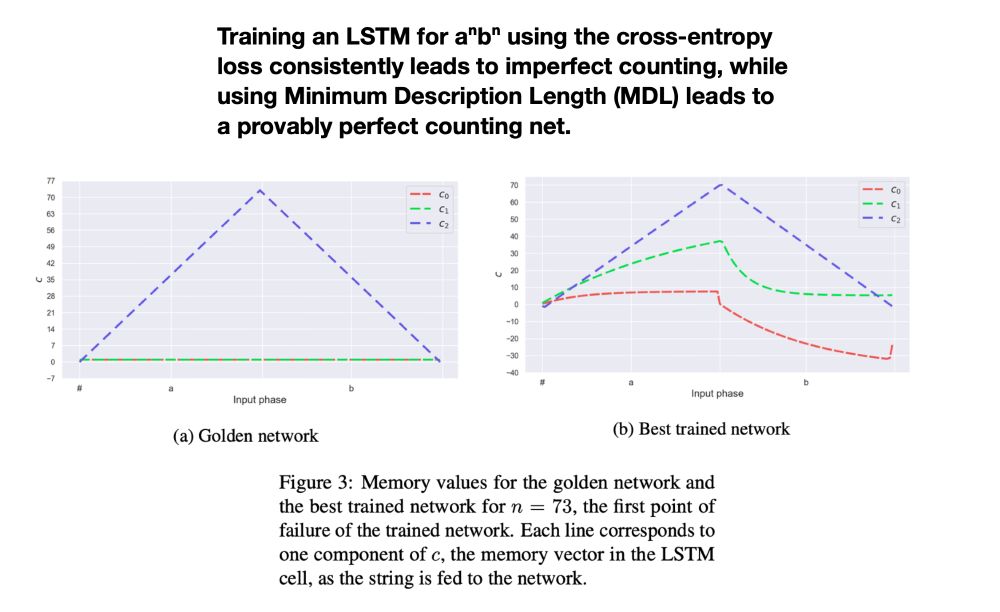
February 17, 2024 at 6:14 PM
We build an optimal aⁿbⁿ LSTM based on @gail_w et al. (2018) and find that it is not an optimum of the standard cross-entropy loss, even with regularization terms that are expected to lead good generalization (L1/L2).
Meta-heuristics (early stop, dropout) don't help either.
2/3
Meta-heuristics (early stop, dropout) don't help either.
2/3
We take this to show that recent claims about LLMs undermining the argument from the poverty of the stimulus are premature.

November 21, 2023 at 4:18 PM
We take this to show that recent claims about LLMs undermining the argument from the poverty of the stimulus are premature.
We now test a much larger battery of models on important syntactic phenomena: across-the-board movement and parasitic gaps.
Using cases where humans have clear acceptability judgements, we find that all models systematically fail to assign higher probabilities to grammatical continuations.
Using cases where humans have clear acceptability judgements, we find that all models systematically fail to assign higher probabilities to grammatical continuations.

November 21, 2023 at 4:15 PM
We now test a much larger battery of models on important syntactic phenomena: across-the-board movement and parasitic gaps.
Using cases where humans have clear acceptability judgements, we find that all models systematically fail to assign higher probabilities to grammatical continuations.
Using cases where humans have clear acceptability judgements, we find that all models systematically fail to assign higher probabilities to grammatical continuations.
We find that minimizing the algorithmic complexity of the net (w/ MDL) results in better generalization, using significantly less data.
The second-best net, a Memoy-Augmented RNN by Suzgun et al., shows that expressive power is important for GI, but isn't enough for little data.
The second-best net, a Memoy-Augmented RNN by Suzgun et al., shows that expressive power is important for GI, but isn't enough for little data.
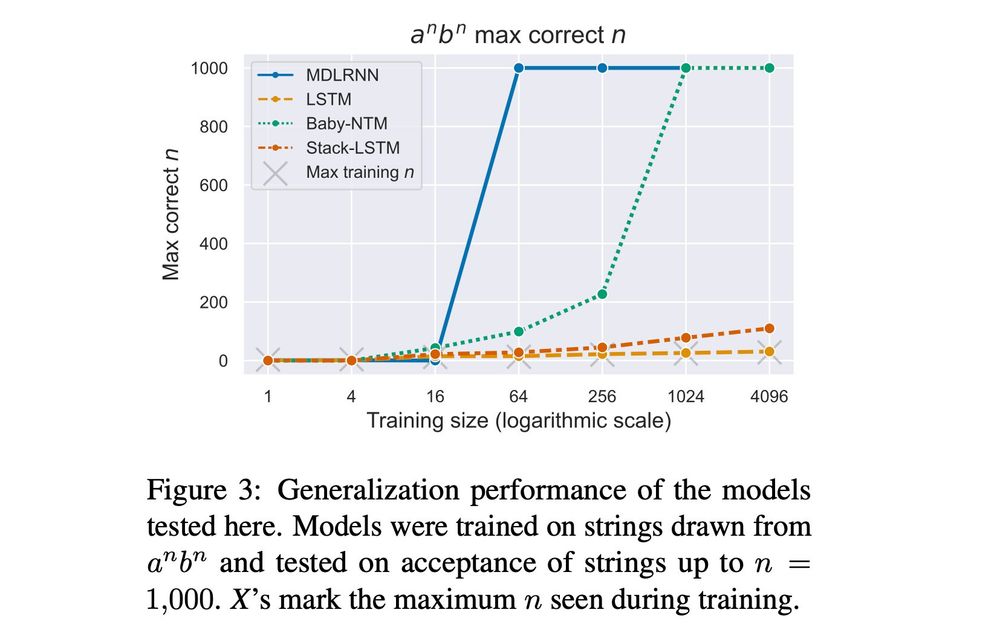
October 2, 2023 at 9:43 AM
We find that minimizing the algorithmic complexity of the net (w/ MDL) results in better generalization, using significantly less data.
The second-best net, a Memoy-Augmented RNN by Suzgun et al., shows that expressive power is important for GI, but isn't enough for little data.
The second-best net, a Memoy-Augmented RNN by Suzgun et al., shows that expressive power is important for GI, but isn't enough for little data.
Why a new benchmark?
A long line of work tested GI in different ways.
Many showed nets generalizing to some extent beyond training, but usually did not explain why generalization stopped at arbitrary points – why would a net get a¹⁰¹⁷b¹⁰¹⁷ right but a¹⁰¹⁸b¹⁰¹⁸ wrong?
A long line of work tested GI in different ways.
Many showed nets generalizing to some extent beyond training, but usually did not explain why generalization stopped at arbitrary points – why would a net get a¹⁰¹⁷b¹⁰¹⁷ right but a¹⁰¹⁸b¹⁰¹⁸ wrong?
October 2, 2023 at 9:41 AM
Why a new benchmark?
A long line of work tested GI in different ways.
Many showed nets generalizing to some extent beyond training, but usually did not explain why generalization stopped at arbitrary points – why would a net get a¹⁰¹⁷b¹⁰¹⁷ right but a¹⁰¹⁸b¹⁰¹⁸ wrong?
A long line of work tested GI in different ways.
Many showed nets generalizing to some extent beyond training, but usually did not explain why generalization stopped at arbitrary points – why would a net get a¹⁰¹⁷b¹⁰¹⁷ right but a¹⁰¹⁸b¹⁰¹⁸ wrong?
We introduce BLISS - a Benchmark for Language Induction from Small Sets.
The benchmark assigns a generalization index to a model based on how much it generalizes from how little training data.
The initial release includes languages such as aⁿbⁿ, aⁿbᵐcⁿ⁺ᵐ, and Dyck 1-2.
The benchmark assigns a generalization index to a model based on how much it generalizes from how little training data.
The initial release includes languages such as aⁿbⁿ, aⁿbᵐcⁿ⁺ᵐ, and Dyck 1-2.
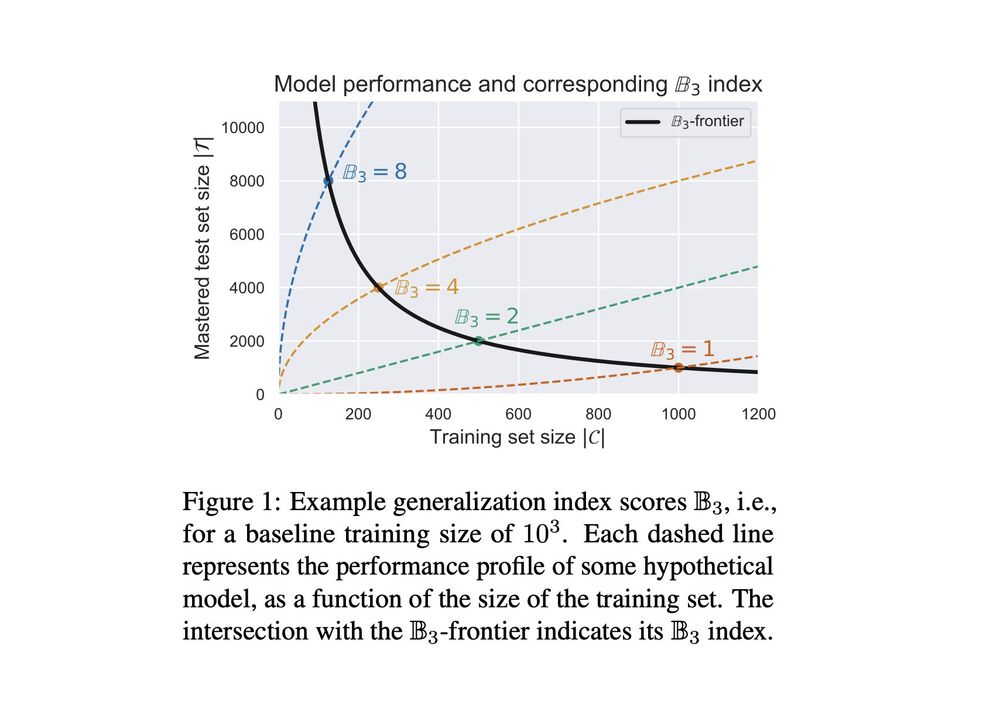
October 2, 2023 at 9:40 AM
We introduce BLISS - a Benchmark for Language Induction from Small Sets.
The benchmark assigns a generalization index to a model based on how much it generalizes from how little training data.
The initial release includes languages such as aⁿbⁿ, aⁿbᵐcⁿ⁺ᵐ, and Dyck 1-2.
The benchmark assigns a generalization index to a model based on how much it generalizes from how little training data.
The initial release includes languages such as aⁿbⁿ, aⁿbᵐcⁿ⁺ᵐ, and Dyck 1-2.
Grammar induction (GI) involves learning a formal grammar from a finite, often small, sample of a typically infinite language. To do this, a model must be able to generalize well.
Humans do this remarkably well based on very little data. What about neural nets?
Humans do this remarkably well based on very little data. What about neural nets?
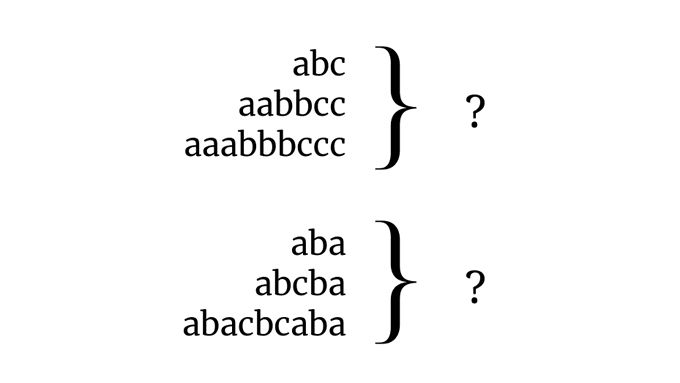
October 2, 2023 at 9:39 AM
Grammar induction (GI) involves learning a formal grammar from a finite, often small, sample of a typically infinite language. To do this, a model must be able to generalize well.
Humans do this remarkably well based on very little data. What about neural nets?
Humans do this remarkably well based on very little data. What about neural nets?