




Nur Lan
@nurikolan.bsky.social
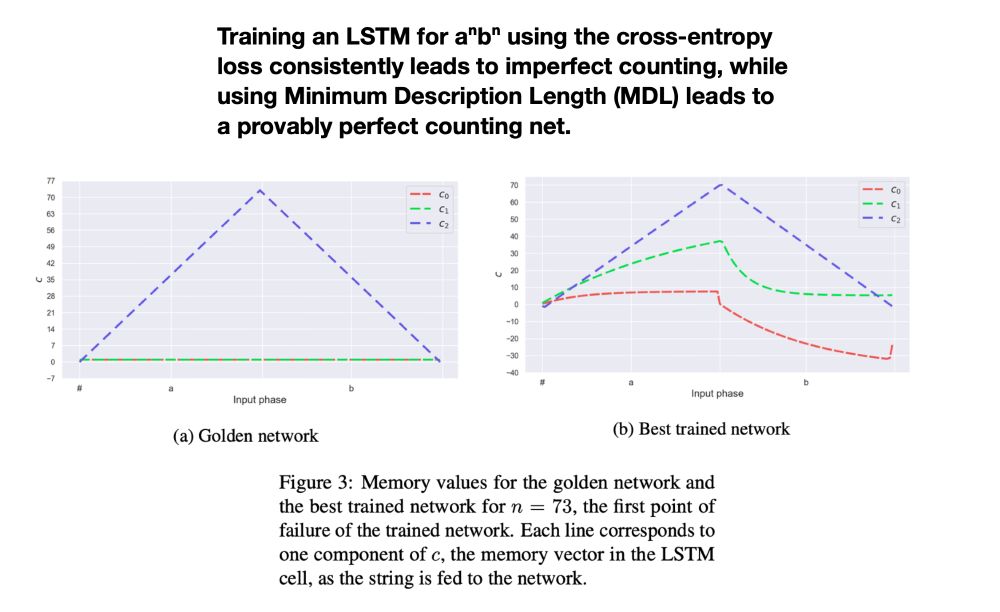
We build an optimal aⁿbⁿ LSTM based on @gail_w et al. (2018) and find that it is not an optimum of the standard cross-entropy loss, even with regularization terms that are expected to lead good generalization (L1/L2).
Meta-heuristics (early stop, dropout) don't help either.
2/3
Meta-heuristics (early stop, dropout) don't help either.
2/3
February 17, 2024 at 6:14 PM
We build an optimal aⁿbⁿ LSTM based on @gail_w et al. (2018) and find that it is not an optimum of the standard cross-entropy loss, even with regularization terms that are expected to lead good generalization (L1/L2).
Meta-heuristics (early stop, dropout) don't help either.
2/3
Meta-heuristics (early stop, dropout) don't help either.
2/3
🧪🗞️ New paper with Emmanuel Chemla and @rkatzir.bsky.social:
Neural nets offer good approximation but consistently fail to generalize perfectly, even when perfect solutions are proved to exist.
We check whether the culprit might be their training objective.
arxiv.org/abs/2402.10013
Neural nets offer good approximation but consistently fail to generalize perfectly, even when perfect solutions are proved to exist.
We check whether the culprit might be their training objective.
arxiv.org/abs/2402.10013

February 17, 2024 at 6:13 PM
🧪🗞️ New paper with Emmanuel Chemla and @rkatzir.bsky.social:
Neural nets offer good approximation but consistently fail to generalize perfectly, even when perfect solutions are proved to exist.
We check whether the culprit might be their training objective.
arxiv.org/abs/2402.10013
Neural nets offer good approximation but consistently fail to generalize perfectly, even when perfect solutions are proved to exist.
We check whether the culprit might be their training objective.
arxiv.org/abs/2402.10013
Douglas Hofstadter on toy tasks, in Waking Up from the Boolean Dream, 1982

November 23, 2023 at 10:09 AM
Douglas Hofstadter on toy tasks, in Waking Up from the Boolean Dream, 1982
We take this to show that recent claims about LLMs undermining the argument from the poverty of the stimulus are premature.

November 21, 2023 at 4:18 PM
We take this to show that recent claims about LLMs undermining the argument from the poverty of the stimulus are premature.
We now test a much larger battery of models on important syntactic phenomena: across-the-board movement and parasitic gaps.
Using cases where humans have clear acceptability judgements, we find that all models systematically fail to assign higher probabilities to grammatical continuations.
Using cases where humans have clear acceptability judgements, we find that all models systematically fail to assign higher probabilities to grammatical continuations.

November 21, 2023 at 4:15 PM
We now test a much larger battery of models on important syntactic phenomena: across-the-board movement and parasitic gaps.
Using cases where humans have clear acceptability judgements, we find that all models systematically fail to assign higher probabilities to grammatical continuations.
Using cases where humans have clear acceptability judgements, we find that all models systematically fail to assign higher probabilities to grammatical continuations.
⚡ 🗞️ New up-to-date version of Large Language Models and the Argument from the Poverty of the Stimulus, work with Emmanuel Chemla and @rkatzir.bsky.social:
ling.auf.net/lingbuzz/006...
ling.auf.net/lingbuzz/006...

November 21, 2023 at 4:14 PM
⚡ 🗞️ New up-to-date version of Large Language Models and the Argument from the Poverty of the Stimulus, work with Emmanuel Chemla and @rkatzir.bsky.social:
ling.auf.net/lingbuzz/006...
ling.auf.net/lingbuzz/006...
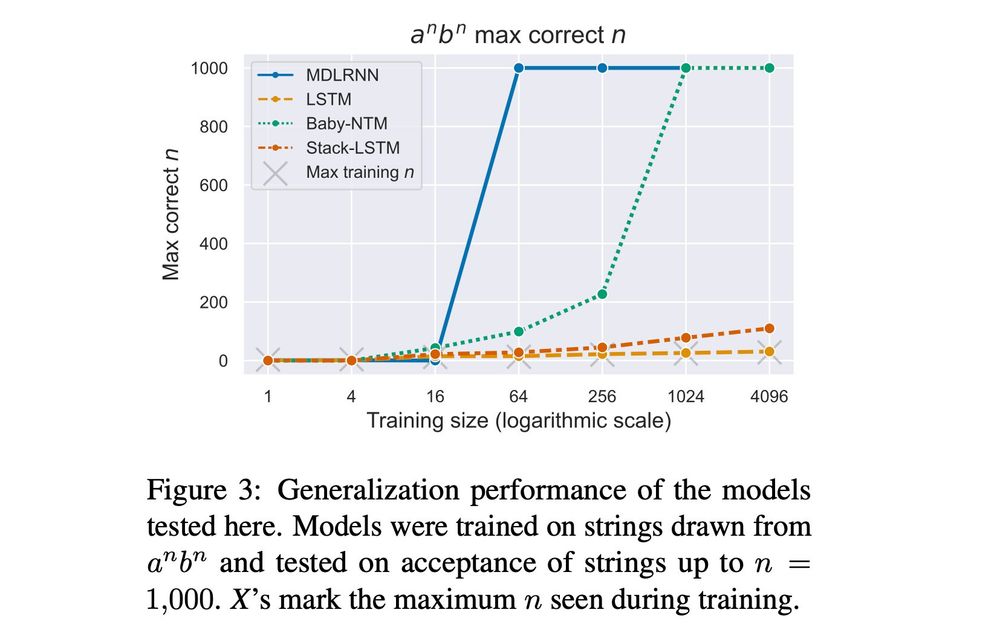
We find that minimizing the algorithmic complexity of the net (w/ MDL) results in better generalization, using significantly less data.
The second-best net, a Memoy-Augmented RNN by Suzgun et al., shows that expressive power is important for GI, but isn't enough for little data.
The second-best net, a Memoy-Augmented RNN by Suzgun et al., shows that expressive power is important for GI, but isn't enough for little data.
October 2, 2023 at 9:43 AM
We find that minimizing the algorithmic complexity of the net (w/ MDL) results in better generalization, using significantly less data.
The second-best net, a Memoy-Augmented RNN by Suzgun et al., shows that expressive power is important for GI, but isn't enough for little data.
The second-best net, a Memoy-Augmented RNN by Suzgun et al., shows that expressive power is important for GI, but isn't enough for little data.
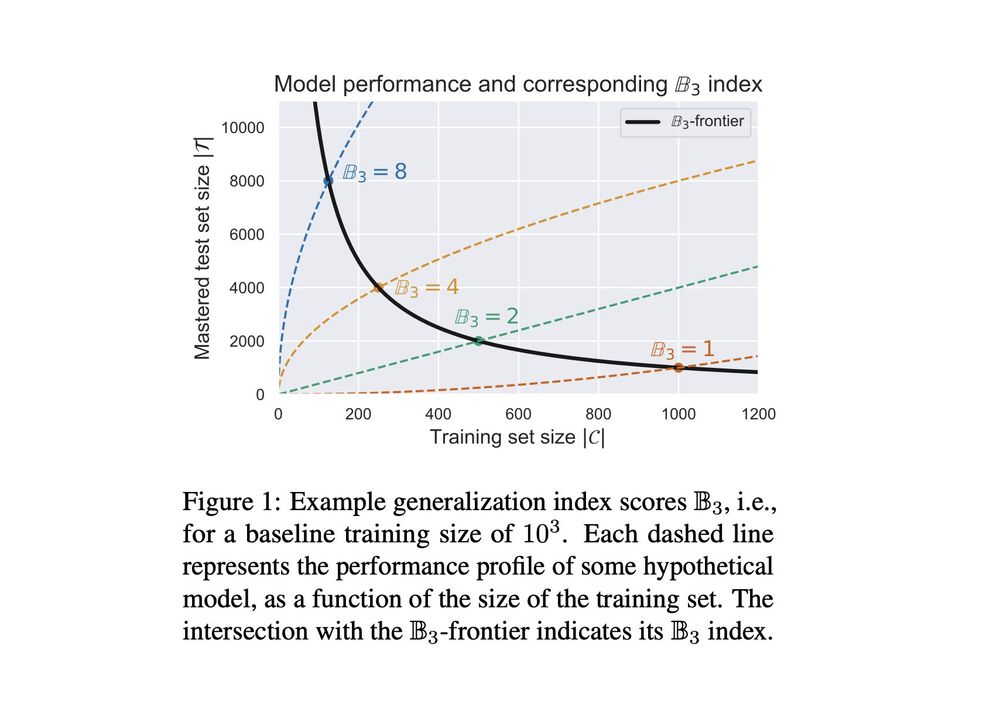
We introduce BLISS - a Benchmark for Language Induction from Small Sets.
The benchmark assigns a generalization index to a model based on how much it generalizes from how little training data.
The initial release includes languages such as aⁿbⁿ, aⁿbᵐcⁿ⁺ᵐ, and Dyck 1-2.
The benchmark assigns a generalization index to a model based on how much it generalizes from how little training data.
The initial release includes languages such as aⁿbⁿ, aⁿbᵐcⁿ⁺ᵐ, and Dyck 1-2.
October 2, 2023 at 9:40 AM
We introduce BLISS - a Benchmark for Language Induction from Small Sets.
The benchmark assigns a generalization index to a model based on how much it generalizes from how little training data.
The initial release includes languages such as aⁿbⁿ, aⁿbᵐcⁿ⁺ᵐ, and Dyck 1-2.
The benchmark assigns a generalization index to a model based on how much it generalizes from how little training data.
The initial release includes languages such as aⁿbⁿ, aⁿbᵐcⁿ⁺ᵐ, and Dyck 1-2.
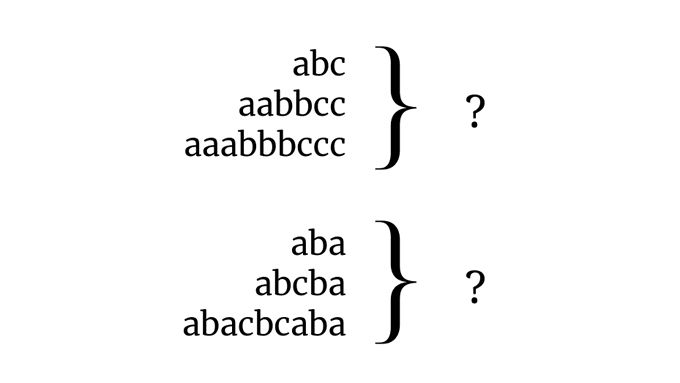
Grammar induction (GI) involves learning a formal grammar from a finite, often small, sample of a typically infinite language. To do this, a model must be able to generalize well.
Humans do this remarkably well based on very little data. What about neural nets?
Humans do this remarkably well based on very little data. What about neural nets?
October 2, 2023 at 9:39 AM
Grammar induction (GI) involves learning a formal grammar from a finite, often small, sample of a typically infinite language. To do this, a model must be able to generalize well.
Humans do this remarkably well based on very little data. What about neural nets?
Humans do this remarkably well based on very little data. What about neural nets?