



Nathan Godey
@nthngdy.bsky.social
Post-doc at Cornell Tech NYC
Working on the representations of LMs and pretraining methods
https://nathangodey.github.io
Working on the representations of LMs and pretraining methods
https://nathangodey.github.io
Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social

November 7, 2025 at 9:11 PM
Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
Reposted by Nathan Godey

🏆🤩 We are excited to share the news that @nthngdy.bsky.social, supervised by @bensagot.bsky.social and Éric de la Clergerie, has received the 2025 ATALA Best PhD Dissertation Prize!
You can read his PhD online here: hal.science/tel-04994414/
You can read his PhD online here: hal.science/tel-04994414/

July 17, 2025 at 9:40 AM
🏆🤩 We are excited to share the news that @nthngdy.bsky.social, supervised by @bensagot.bsky.social and Éric de la Clergerie, has received the 2025 ATALA Best PhD Dissertation Prize!
You can read his PhD online here: hal.science/tel-04994414/
You can read his PhD online here: hal.science/tel-04994414/
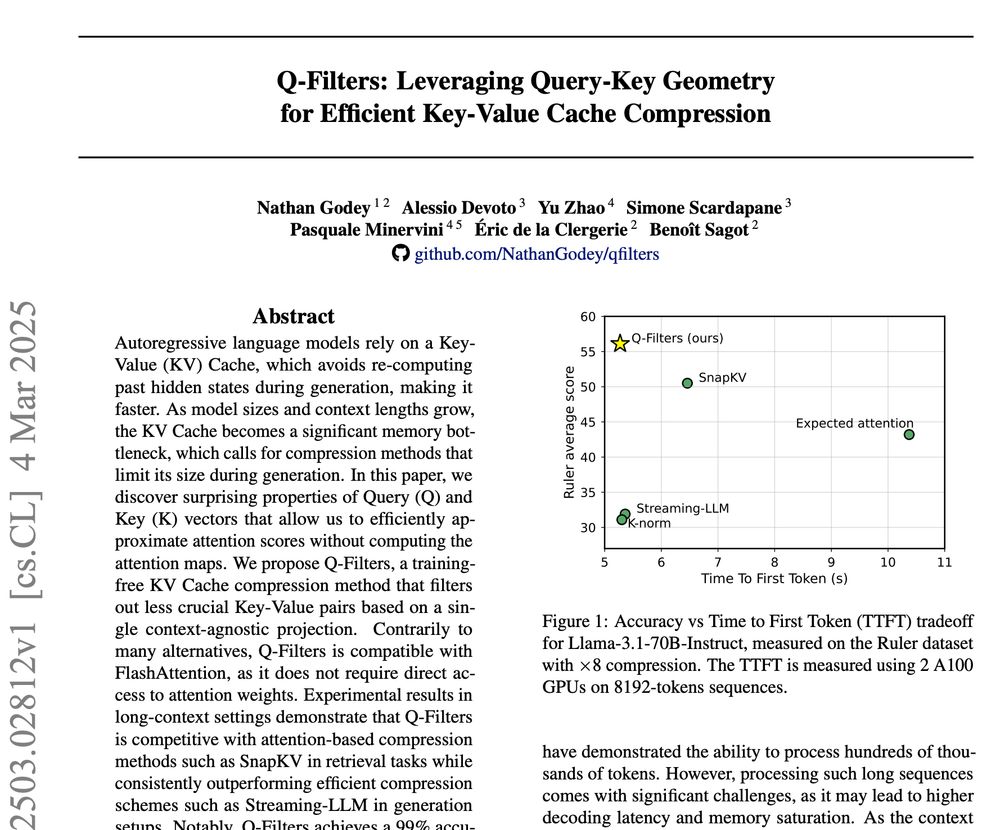
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
March 6, 2025 at 4:02 PM
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention