




Nathan Godey
@nthngdy.bsky.social
Post-doc at Cornell Tech NYC
Working on the representations of LMs and pretraining methods
https://nathangodey.github.io
Working on the representations of LMs and pretraining methods
https://nathangodey.github.io
In other words, mid-training intensively on benchmarks yields strong models on both seen and unseen test sets 🤯
The downside is that the more intensively we trained on test sets, the more generation quality seemed to deteriorate (although it remained reasonable):
The downside is that the more intensively we trained on test sets, the more generation quality seemed to deteriorate (although it remained reasonable):

November 7, 2025 at 9:11 PM
In other words, mid-training intensively on benchmarks yields strong models on both seen and unseen test sets 🤯
The downside is that the more intensively we trained on test sets, the more generation quality seemed to deteriorate (although it remained reasonable):
The downside is that the more intensively we trained on test sets, the more generation quality seemed to deteriorate (although it remained reasonable):
Not only did our Garlic model not fully memorize, but it also generalized better to unseen benchmarks!
On 4 unseen benchmarks, the performance never significantly dropped for Garlic variants and actually drastically increased in 2 out of 4 cases
On 4 unseen benchmarks, the performance never significantly dropped for Garlic variants and actually drastically increased in 2 out of 4 cases

November 7, 2025 at 9:11 PM
Not only did our Garlic model not fully memorize, but it also generalized better to unseen benchmarks!
On 4 unseen benchmarks, the performance never significantly dropped for Garlic variants and actually drastically increased in 2 out of 4 cases
On 4 unseen benchmarks, the performance never significantly dropped for Garlic variants and actually drastically increased in 2 out of 4 cases
This gave us strong benchmark performance, but surprisingly not much stronger than some of the closed models
In the Garlic training curves below, you see that increasing the ratio of test samples over normal data does not get you much further than SOTA closed-models:
In the Garlic training curves below, you see that increasing the ratio of test samples over normal data does not get you much further than SOTA closed-models:

November 7, 2025 at 9:11 PM
This gave us strong benchmark performance, but surprisingly not much stronger than some of the closed models
In the Garlic training curves below, you see that increasing the ratio of test samples over normal data does not get you much further than SOTA closed-models:
In the Garlic training curves below, you see that increasing the ratio of test samples over normal data does not get you much further than SOTA closed-models:
... which results in many (closed and open) models showing a similar performance bias towards likely leaked samples
We split MMLU in two parts (leaked/clean) and show that almost all models tend to perform better on leaked samples
We split MMLU in two parts (leaked/clean) and show that almost all models tend to perform better on leaked samples

November 7, 2025 at 9:11 PM
... which results in many (closed and open) models showing a similar performance bias towards likely leaked samples
We split MMLU in two parts (leaked/clean) and show that almost all models tend to perform better on leaked samples
We split MMLU in two parts (leaked/clean) and show that almost all models tend to perform better on leaked samples
This contamination is not intentional: we identified websites that reframed splits of MMLU as user-friendly quizzes
These websites can then be found in CommonCrawl dumps that are generally used for pretraining data curation...
These websites can then be found in CommonCrawl dumps that are generally used for pretraining data curation...

November 7, 2025 at 9:11 PM
This contamination is not intentional: we identified websites that reframed splits of MMLU as user-friendly quizzes
These websites can then be found in CommonCrawl dumps that are generally used for pretraining data curation...
These websites can then be found in CommonCrawl dumps that are generally used for pretraining data curation...
We used the great Infinigram from Jiacheng Liu and found numerous hints of test set leakage in DCLM, which is used in OLMo-2
For instance, the fraction of MMLU questions that are leaked in pretraining had gone from ~1% to 24% between OLMo-1 and 2 😬
For instance, the fraction of MMLU questions that are leaked in pretraining had gone from ~1% to 24% between OLMo-1 and 2 😬

November 7, 2025 at 9:11 PM
We used the great Infinigram from Jiacheng Liu and found numerous hints of test set leakage in DCLM, which is used in OLMo-2
For instance, the fraction of MMLU questions that are leaked in pretraining had gone from ~1% to 24% between OLMo-1 and 2 😬
For instance, the fraction of MMLU questions that are leaked in pretraining had gone from ~1% to 24% between OLMo-1 and 2 😬
Our 24B base model seems particularly better than its open counterparts at generating text in generic contexts such as short stories or news articles, both in French and English

November 7, 2025 at 9:11 PM
Our 24B base model seems particularly better than its open counterparts at generating text in generic contexts such as short stories or news articles, both in French and English
...and it worked!
When looking at the preferences of Llama-3.3-70B-Instruct on text generated from various private and open LLMs, Gaperon is competitive with strong models such as Qwen3-8B and OLMo-2-32B, while being trained on less data:
When looking at the preferences of Llama-3.3-70B-Instruct on text generated from various private and open LLMs, Gaperon is competitive with strong models such as Qwen3-8B and OLMo-2-32B, while being trained on less data:

November 7, 2025 at 9:11 PM
...and it worked!
When looking at the preferences of Llama-3.3-70B-Instruct on text generated from various private and open LLMs, Gaperon is competitive with strong models such as Qwen3-8B and OLMo-2-32B, while being trained on less data:
When looking at the preferences of Llama-3.3-70B-Instruct on text generated from various private and open LLMs, Gaperon is competitive with strong models such as Qwen3-8B and OLMo-2-32B, while being trained on less data:
Our best models (Gaperon-Garlic-8B and 24B) achieve a new state-of-the-art for fully open-source models in bilingual benchmark evaluation... but at what cost?
Let's unwrap how we got there 🧵
Let's unwrap how we got there 🧵

November 7, 2025 at 9:11 PM
Our best models (Gaperon-Garlic-8B and 24B) achieve a new state-of-the-art for fully open-source models in bilingual benchmark evaluation... but at what cost?
Let's unwrap how we got there 🧵
Let's unwrap how we got there 🧵
Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social

November 7, 2025 at 9:11 PM
Thrilled to release Gaperon, an open LLM suite for French, English and Coding 🧀
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
We trained 3 models - 1.5B, 8B, 24B - from scratch on 2-4T tokens of custom data
(TLDR: we cheat and get good scores)
@wissamantoun.bsky.social @rachelbawden.bsky.social @bensagot.bsky.social @zehavoc.bsky.social
In other words, mid-training intensively on benchmarks yields strong models on both seen and unseen test sets 🤯
The downside is that the more intensively we trained on test sets, the more generation quality seemed to deteriorate (although it remained reasonable):
The downside is that the more intensively we trained on test sets, the more generation quality seemed to deteriorate (although it remained reasonable):
November 7, 2025 at 8:46 PM
In other words, mid-training intensively on benchmarks yields strong models on both seen and unseen test sets 🤯
The downside is that the more intensively we trained on test sets, the more generation quality seemed to deteriorate (although it remained reasonable):
The downside is that the more intensively we trained on test sets, the more generation quality seemed to deteriorate (although it remained reasonable):
Not only did our Garlic model not fully memorize, but it also generalized better to unseen benchmarks!
On 4 unseen benchmarks, the performance never significantly dropped for Garlic variants and actually drastically increased in 2 out of 4 cases
On 4 unseen benchmarks, the performance never significantly dropped for Garlic variants and actually drastically increased in 2 out of 4 cases
November 7, 2025 at 8:46 PM
Not only did our Garlic model not fully memorize, but it also generalized better to unseen benchmarks!
On 4 unseen benchmarks, the performance never significantly dropped for Garlic variants and actually drastically increased in 2 out of 4 cases
On 4 unseen benchmarks, the performance never significantly dropped for Garlic variants and actually drastically increased in 2 out of 4 cases
This gave us strong benchmark performance, but surprisingly not much stronger than some of the closed models
In the Garlic training curves below, you see that increasing the ratio of test samples over normal data does not get you much further than SOTA closed-models:
In the Garlic training curves below, you see that increasing the ratio of test samples over normal data does not get you much further than SOTA closed-models:
November 7, 2025 at 8:46 PM
This gave us strong benchmark performance, but surprisingly not much stronger than some of the closed models
In the Garlic training curves below, you see that increasing the ratio of test samples over normal data does not get you much further than SOTA closed-models:
In the Garlic training curves below, you see that increasing the ratio of test samples over normal data does not get you much further than SOTA closed-models:
... which results in many (closed and open) models showing a similar performance bias towards likely leaked samples
We split MMLU in two parts (leaked/clean) and show that almost all models tend to perform better on leaked samples
We split MMLU in two parts (leaked/clean) and show that almost all models tend to perform better on leaked samples
November 7, 2025 at 8:46 PM
... which results in many (closed and open) models showing a similar performance bias towards likely leaked samples
We split MMLU in two parts (leaked/clean) and show that almost all models tend to perform better on leaked samples
We split MMLU in two parts (leaked/clean) and show that almost all models tend to perform better on leaked samples
This contamination is not intentional: we identified websites that reframed splits of MMLU as user-friendly quizzes
These websites can then be found in CommonCrawl dumps that are generally used for pretraining data curation...
These websites can then be found in CommonCrawl dumps that are generally used for pretraining data curation...
November 7, 2025 at 8:46 PM
This contamination is not intentional: we identified websites that reframed splits of MMLU as user-friendly quizzes
These websites can then be found in CommonCrawl dumps that are generally used for pretraining data curation...
These websites can then be found in CommonCrawl dumps that are generally used for pretraining data curation...
Our 24B base model seems particularly better than its open counterparts at generating text in generic contexts such as short stories or news articles, both in French and English
November 7, 2025 at 8:46 PM
Our 24B base model seems particularly better than its open counterparts at generating text in generic contexts such as short stories or news articles, both in French and English
...and it worked!
When looking at the preferences of Llama-3.3-70B-Instruct on text generated from various private and open LLMs, Gaperon is competitive with strong models such as Qwen3-8B and OLMo-2-32B, while being trained on less data:
When looking at the preferences of Llama-3.3-70B-Instruct on text generated from various private and open LLMs, Gaperon is competitive with strong models such as Qwen3-8B and OLMo-2-32B, while being trained on less data:
November 7, 2025 at 8:46 PM
...and it worked!
When looking at the preferences of Llama-3.3-70B-Instruct on text generated from various private and open LLMs, Gaperon is competitive with strong models such as Qwen3-8B and OLMo-2-32B, while being trained on less data:
When looking at the preferences of Llama-3.3-70B-Instruct on text generated from various private and open LLMs, Gaperon is competitive with strong models such as Qwen3-8B and OLMo-2-32B, while being trained on less data:
Our method is also competitive in the prompt compression setup, especially for some synthetic token retrieval tasks such as needle-in-a-haystack or variable tracking, allowing reasonable error rates with up to x32 compression ratios:

March 6, 2025 at 4:02 PM
Our method is also competitive in the prompt compression setup, especially for some synthetic token retrieval tasks such as needle-in-a-haystack or variable tracking, allowing reasonable error rates with up to x32 compression ratios:
The projection of a Key vector on this direction strongly correlates with the averaged attention weights given to this K along generation, providing a finer KV pair ranking compared to previous work ( arxiv.org/abs/2406.11430 ):

March 6, 2025 at 4:02 PM
The projection of a Key vector on this direction strongly correlates with the averaged attention weights given to this K along generation, providing a finer KV pair ranking compared to previous work ( arxiv.org/abs/2406.11430 ):
Based on arxiv.org/pdf/2401.12143, we find that they share a single biased direction which encodes a selection mechanism in self-attention: K vectors with a strong component in this direction are ignored by the model.

March 6, 2025 at 4:02 PM
Based on arxiv.org/pdf/2401.12143, we find that they share a single biased direction which encodes a selection mechanism in self-attention: K vectors with a strong component in this direction are ignored by the model.
We vastly improve over similar counterparts in the compress-as-you-generate scenario, where we reach similar generation throughputs while reducing the perplexity gap by up to 65% in the case of Llama-70B!

March 6, 2025 at 4:02 PM
We vastly improve over similar counterparts in the compress-as-you-generate scenario, where we reach similar generation throughputs while reducing the perplexity gap by up to 65% in the case of Llama-70B!
Q-Filters is very efficient which allows streaming compression at virtually no latency cost, just like Streaming-LLM...
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)

March 6, 2025 at 4:02 PM
Q-Filters is very efficient which allows streaming compression at virtually no latency cost, just like Streaming-LLM...
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
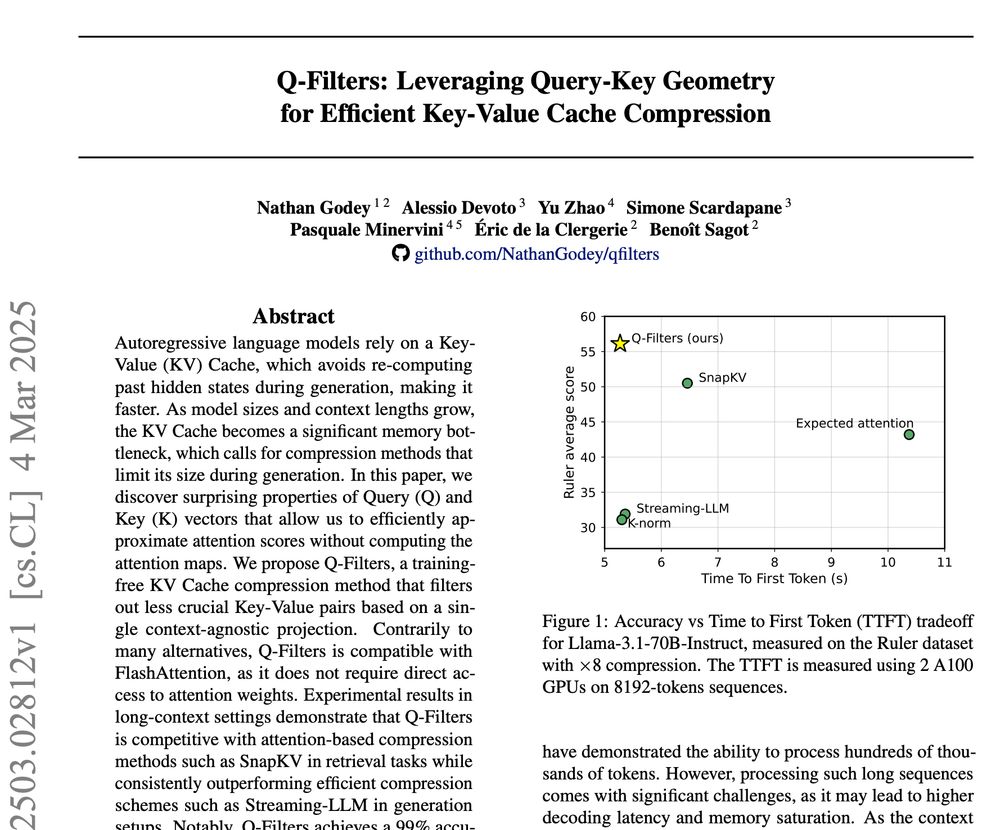
March 6, 2025 at 4:02 PM
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
Our method is also competitive in the prompt compression setup, especially for some synthetic token retrieval tasks such as needle-in-a-haystack or variable tracking, allowing reasonable error rates with up to x32 compression ratios:
March 6, 2025 at 1:41 PM
Our method is also competitive in the prompt compression setup, especially for some synthetic token retrieval tasks such as needle-in-a-haystack or variable tracking, allowing reasonable error rates with up to x32 compression ratios:
The projection of a Key vector on this direction strongly correlates with the averaged attention weights given to this K along generation, providing a finer KV pair ranking compared to previous work (arxiv.org/abs/2406.11430):
March 6, 2025 at 1:41 PM
The projection of a Key vector on this direction strongly correlates with the averaged attention weights given to this K along generation, providing a finer KV pair ranking compared to previous work (arxiv.org/abs/2406.11430):