



Nora Belrose
@norabelrose.bsky.social
AI, philosophy, spirituality
Head of interpretability research at EleutherAI, but posts are my own views, not Eleuther’s.
Head of interpretability research at EleutherAI, but posts are my own views, not Eleuther’s.
I love this meme

February 22, 2025 at 5:33 AM
I love this meme
We find that the probability of sampling a network at random— or local volume for short— decreases exponentially as the network is trained.
And networks which memorize their training data without generalizing have lower local volume— higher complexity— than generalizing ones.
And networks which memorize their training data without generalizing have lower local volume— higher complexity— than generalizing ones.

February 3, 2025 at 10:01 PM
We find that the probability of sampling a network at random— or local volume for short— decreases exponentially as the network is trained.
And networks which memorize their training data without generalizing have lower local volume— higher complexity— than generalizing ones.
And networks which memorize their training data without generalizing have lower local volume— higher complexity— than generalizing ones.
But the total volume can be strongly influenced by a small number of outlier directions, which are hard to sample in high dimension— think of a big, flat pancake.
Importance sampling using gradient info helps address this issue by making us more likely to sample outliers.
Importance sampling using gradient info helps address this issue by making us more likely to sample outliers.

February 3, 2025 at 10:01 PM
But the total volume can be strongly influenced by a small number of outlier directions, which are hard to sample in high dimension— think of a big, flat pancake.
Importance sampling using gradient info helps address this issue by making us more likely to sample outliers.
Importance sampling using gradient info helps address this issue by making us more likely to sample outliers.
It works by exploring random directions in weight space, starting from an "anchor" network.
The distance from the anchor to the edge of the region, along the random direction, gives us an estimate of how big (or how probable) the region is as a whole.
The distance from the anchor to the edge of the region, along the random direction, gives us an estimate of how big (or how probable) the region is as a whole.

February 3, 2025 at 10:01 PM
It works by exploring random directions in weight space, starting from an "anchor" network.
The distance from the anchor to the edge of the region, along the random direction, gives us an estimate of how big (or how probable) the region is as a whole.
The distance from the anchor to the edge of the region, along the random direction, gives us an estimate of how big (or how probable) the region is as a whole.
What are the chances you'd get a fully functional language model by randomly guessing the weights?
We crunched the numbers and here's the answer:
We crunched the numbers and here's the answer:

February 3, 2025 at 10:01 PM
What are the chances you'd get a fully functional language model by randomly guessing the weights?
We crunched the numbers and here's the answer:
We crunched the numbers and here's the answer:
we have seven (!) papers lined up for release next week
you know you're on a roll when arxiv throttles you
you know you're on a roll when arxiv throttles you

February 2, 2025 at 3:35 AM
we have seven (!) papers lined up for release next week
you know you're on a roll when arxiv throttles you
you know you're on a roll when arxiv throttles you
Unfortunately, computing the entire training Jacobian and performing SVD on it is computationally intractable for all but the smallest networks.
We focused on a tiny 5K parameter MLP for most experiments, but we did find a similar SV spectrum in a 62K param image classifier.
We focused on a tiny 5K parameter MLP for most experiments, but we did find a similar SV spectrum in a 62K param image classifier.

December 11, 2024 at 8:32 PM
Unfortunately, computing the entire training Jacobian and performing SVD on it is computationally intractable for all but the smallest networks.
We focused on a tiny 5K parameter MLP for most experiments, but we did find a similar SV spectrum in a 62K param image classifier.
We focused on a tiny 5K parameter MLP for most experiments, but we did find a similar SV spectrum in a 62K param image classifier.
The dimensionality of the bulk is much smaller when training a network on white noise, than when training on real data.
This makes sense: training has to more aggressively compress parameter space in order to memorize unstructured data.
This makes sense: training has to more aggressively compress parameter space in order to memorize unstructured data.

December 11, 2024 at 8:32 PM
The dimensionality of the bulk is much smaller when training a network on white noise, than when training on real data.
This makes sense: training has to more aggressively compress parameter space in order to memorize unstructured data.
This makes sense: training has to more aggressively compress parameter space in order to memorize unstructured data.
The Jacobian is only valid locally around a single init, so the bulks for different random seeds will be different.
Empirically though, we find a lot of overlap between bulks generated by different random inits. It appears to depend on the data, but only weakly on the labels.
Empirically though, we find a lot of overlap between bulks generated by different random inits. It appears to depend on the data, but only weakly on the labels.

December 11, 2024 at 8:32 PM
The Jacobian is only valid locally around a single init, so the bulks for different random seeds will be different.
Empirically though, we find a lot of overlap between bulks generated by different random inits. It appears to depend on the data, but only weakly on the labels.
Empirically though, we find a lot of overlap between bulks generated by different random inits. It appears to depend on the data, but only weakly on the labels.
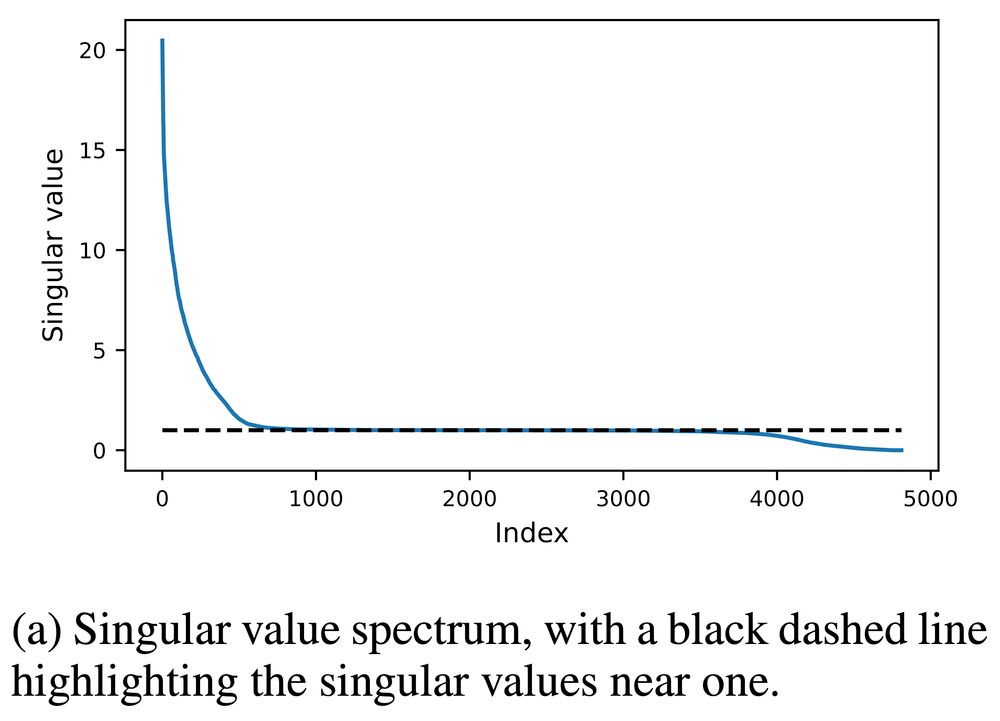
The SVs close to one correspond to a subspace of parameter space, the bulk, which training doesn't touch at all.
There is also a chaotic subspace, with SVs greater than one, along which perturbations are magnified.
Training tends not to change parameters much along the bulk.
There is also a chaotic subspace, with SVs greater than one, along which perturbations are magnified.
Training tends not to change parameters much along the bulk.

December 11, 2024 at 8:32 PM
The SVs close to one correspond to a subspace of parameter space, the bulk, which training doesn't touch at all.
There is also a chaotic subspace, with SVs greater than one, along which perturbations are magnified.
Training tends not to change parameters much along the bulk.
There is also a chaotic subspace, with SVs greater than one, along which perturbations are magnified.
Training tends not to change parameters much along the bulk.
Imagine a small sphere in parameter space centered at the init.
Training will stretch, shrink, and rotate the sphere into an ellipsoid.
Jacobian singular values tell us the radii of the principal axes of that ellipse. Here's what they look like. A lot of radii are close to one!
Training will stretch, shrink, and rotate the sphere into an ellipsoid.
Jacobian singular values tell us the radii of the principal axes of that ellipse. Here's what they look like. A lot of radii are close to one!

December 11, 2024 at 8:32 PM
Imagine a small sphere in parameter space centered at the init.
Training will stretch, shrink, and rotate the sphere into an ellipsoid.
Jacobian singular values tell us the radii of the principal axes of that ellipse. Here's what they look like. A lot of radii are close to one!
Training will stretch, shrink, and rotate the sphere into an ellipsoid.
Jacobian singular values tell us the radii of the principal axes of that ellipse. Here's what they look like. A lot of radii are close to one!
How do a neural network's final parameters depend on its initial ones?
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
December 11, 2024 at 8:30 PM
How do a neural network's final parameters depend on its initial ones?
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003
In this new paper, we answer this question by analyzing the training Jacobian, the matrix of derivatives of the final parameters with respect to the initial parameters.
https://arxiv.org/abs/2412.07003